本章目标:理解现代 ML 加速器(GPU/TPU)的核心组成部件,建立”芯片 = 计算单元 + 内存”的心智模型。
对应原书:Chapter 2 (TPUs) + Chapter 12 (GPUs)
改写范围:原书主线是 TPU 硬件;GPU/CUDA/Blackwell 内容是为 Megatron 和 NVIDIA 训练栈补的对照背景。 优先级:⭐⭐⭐ 高 | 建议时间:Day 1-2, 约 3 小时
1.1 为什么你需要了解硬件
🔗 与你的联系
作为预训练研究员,你关注 Scaling Law(C = 6ND 等公式)和模型架构设计。但 Scaling Law 告诉你”需要多少 FLOPs”,而硬件决定了”这些 FLOPs 要花多少时间和钱”。一个在理论上很好的架构(比如某种新注意力机制),如果在硬件上跑不快,就无法 scale。理解硬件是连接”模型设计”和”实际训练”的桥梁。
书中一个核心观点:
“A 20% win on benchmarks is irrelevant if it comes at a 20% cost to roofline efficiency.”
1.2 TPU 的核心组件
一个 TPU 本质上就是一个超强的矩阵乘法机器加上一块快速内存。
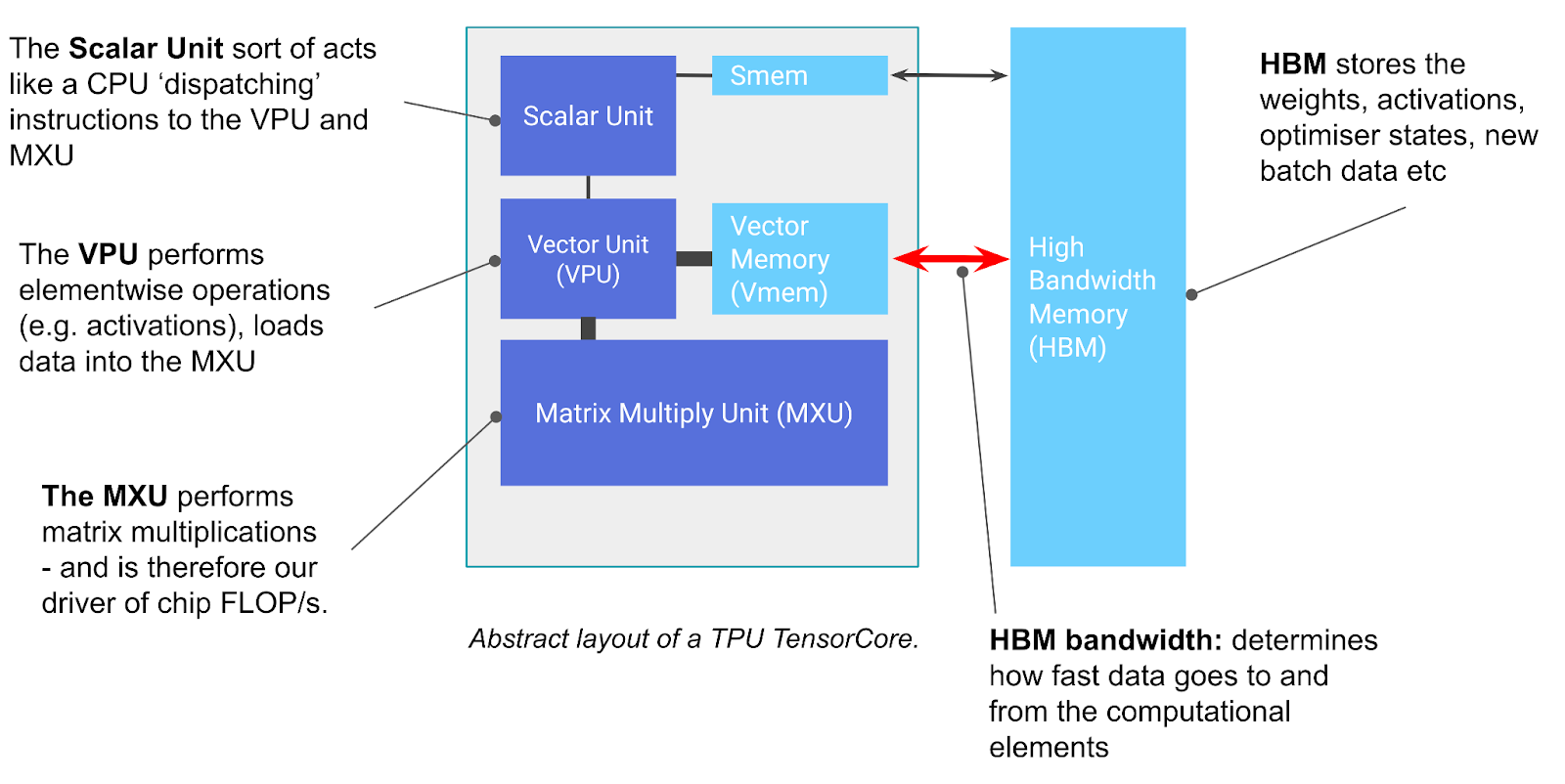
TPU 的核心组件:
MXU(Matrix Multiply Unit)— 矩阵乘法单元
- TPU 的核心,专门做矩阵乘法
- 使用脉动阵列(Systolic Array)架构
- TPU v5e:每个 MXU 每 8 个周期完成一次
bf16[8,128] × bf16[128,128]的矩阵乘法 - 总算力:TPU v5e 约
2×10¹⁴bf16 FLOPs/s
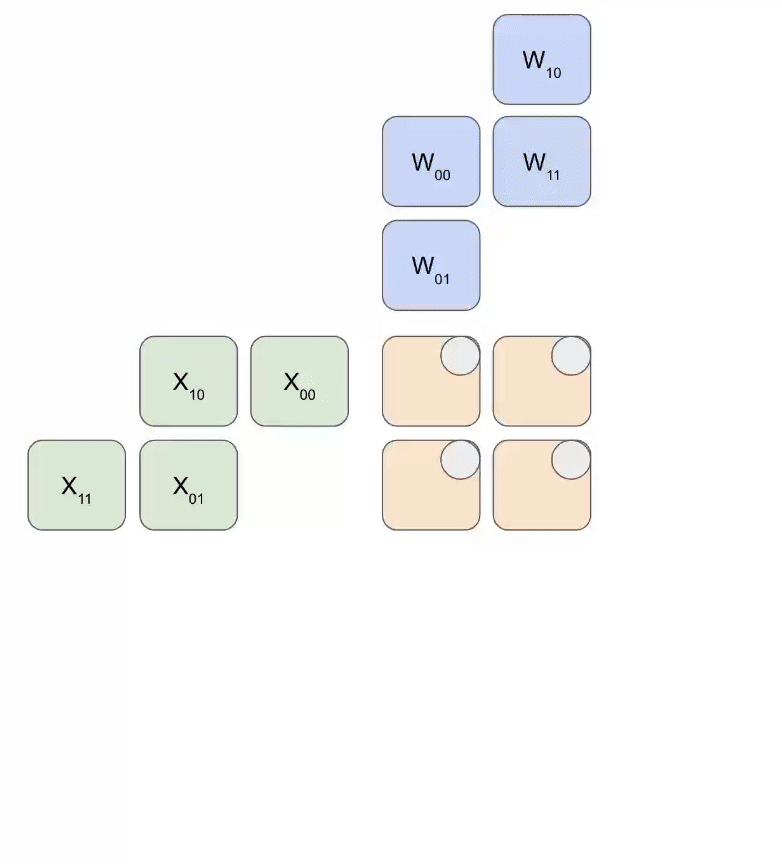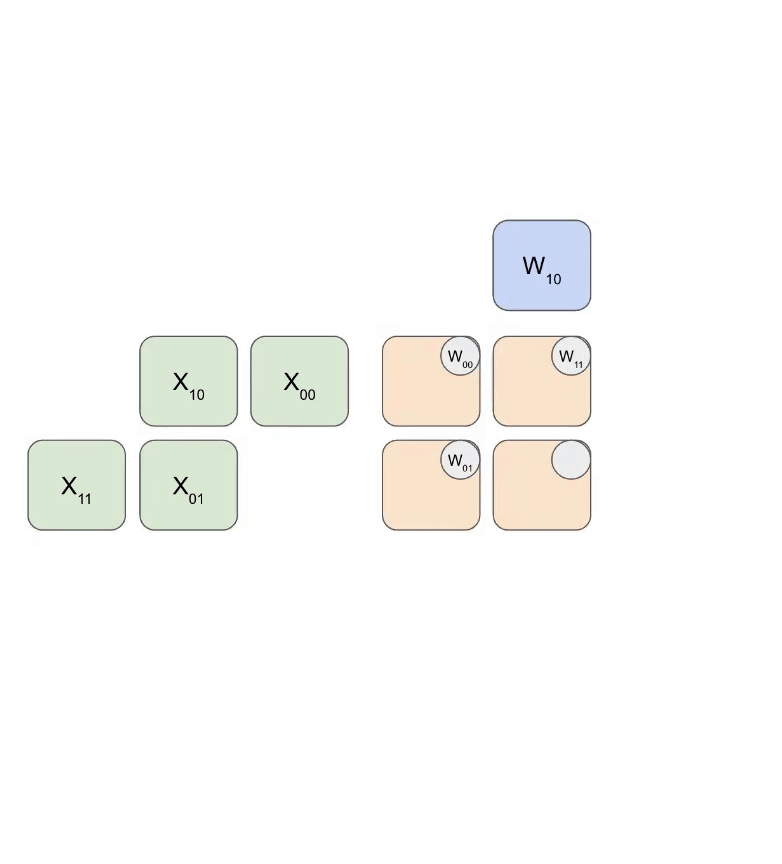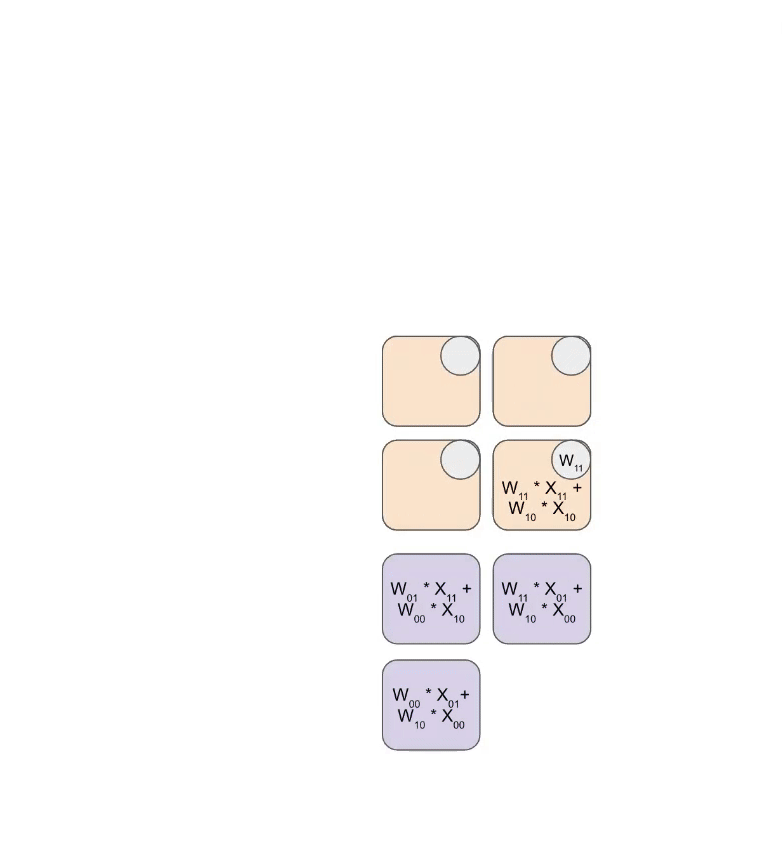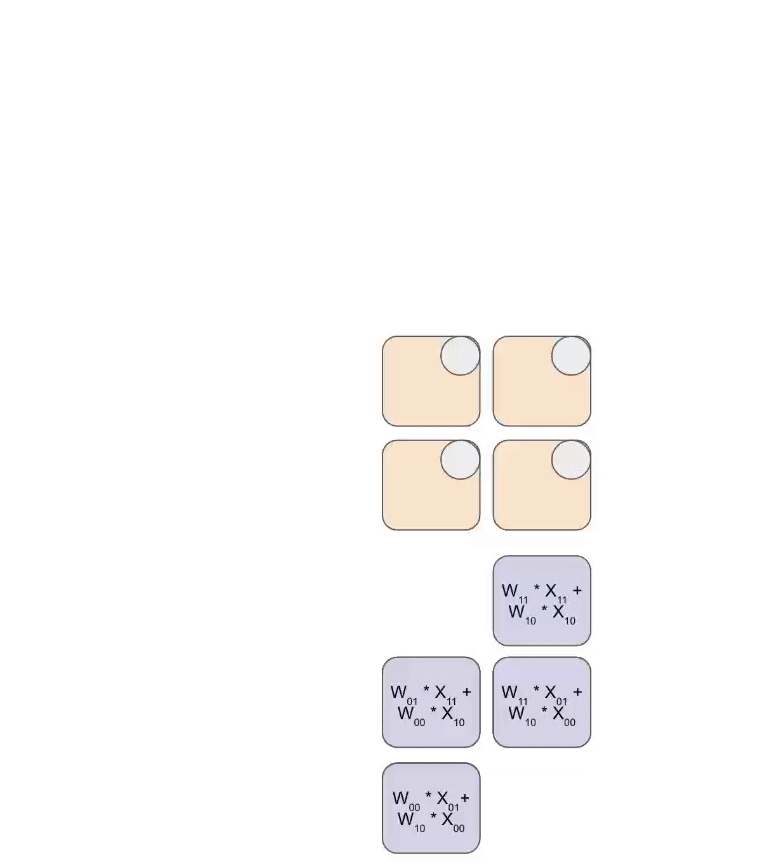
📋 背景知识:什么是脉动阵列(Systolic Array)
脉动阵列是一种专门为矩阵乘法设计的硬件结构。想象一个 128×128 的计算单元网格:
- 矩阵 A 的行从左侧流入
- 矩阵 B 的列从上方流入
- 每个计算单元做一次乘加(multiply-accumulate)并将结果传给下一个
- 数据像心跳一样”脉动”式地流过整个阵列
关键优势:每个数据元素被加载一次,但被使用多次(被整行/列的计算单元共享),这就是为什么矩阵乘法的算术强度可以很高。
VPU(Vector Processing Unit)— 向量处理单元
- 负责非矩阵乘法的操作:ReLU、LayerNorm、Softmax、逐元素加法等
- 类似 CPU 的 SIMD 单元,对向量做相同操作
- 比 MXU 慢很多(FLOPs/s 低一个数量级)
VMEM(Vector Memory)— 快速片上缓存
- 大小:TPU v5e 为 128 MiB
- 带宽极高(约为 HBM 的 22×)
- 程序员可控的 scratchpad(不像 CPU cache 那样自动管理)
- 数据必须先从 HBM 搬到 VMEM,MXU 才能使用
HBM(High Bandwidth Memory)— 主内存
- 存储模型权重、梯度、激活值
- 容量:TPU v5e 为 16 GiB,v5p 为 96 GiB
- 带宽:约 0.8-2.8 TB/s(取决于代次)
VMEM 与算术强度
VMEM 带宽约为 HBM 的 22×。这意味着如果能把数据放在 VMEM 中,matmul 只需要约 10-20 的算术强度就能达到峰值 FLOPs 利用率(而非 HBM 的 240+)。这对推理尤其重要:如果权重足够小(或分片后足够小)可以放进 VMEM,Generation 阶段的 memory-bound 问题就大大缓解。
VMEM Prefetching:在 Transformer 中,可以在 attention 计算期间预先将 FFN 权重加载到 VMEM 中,从而隐藏权重加载的开销。前提是单层权重分片后能放进 VMEM。
TPU 芯片 = 2 个 TensorCore(Megacore)
自 TPU v4 起,一颗 TPU 芯片通常包含 2 个 TensorCore,共享 HBM,可以视为一个大加速器(称为”megacore”配置)。更早的 TPU v3 的两个 core 内存独立,被视为两个独立加速器。推理芯片(如 TPU v5e)每芯片只有 1 个 core。
芯片、Tray 和 Host 的层级
Host (CPU)
├── PCIe 连接
├── Tray 0: 4 颗 TPU 芯片
└── Tray 1: 4 颗 TPU 芯片(v5e 有 2 个 tray/host = 8 chips)
- Tray:4 颗 TPU 芯片组成一个 tray,通过 PCIe 连接到 CPU host
- Host:一个 CPU host 管理 1-2 个 tray(训练芯片 1 个 tray = 4 chips,v5e 2 个 tray = 8 chips)
- PCIe 带宽有限:TPU v4 的 PCIe 仅 16 GB/s 每方向,约为 HBM 带宽的 1/100
📋 背景知识:HBM vs 普通 DDR 内存
HBM(High Bandwidth Memory)是一种 3D 堆叠的 DRAM:
- 多层 DRAM 芯片垂直堆叠,通过硅通孔(TSV)连接
- 带宽比普通 DDR5 高 5-10×(TB/s 级别 vs 几十 GB/s)
- 容量比 SRAM 大得多,但带宽比片上 SRAM/VMEM 低
- 物理上紧贴计算芯片(通过 interposer 连接)
你可以把它想象成:VMEM 是 L1 cache(小但超快),HBM 是主内存(大但相对慢)。
1.3 GPU 的核心组件
GPU(以 NVIDIA H100 为例)结构类似,但更”模块化”:
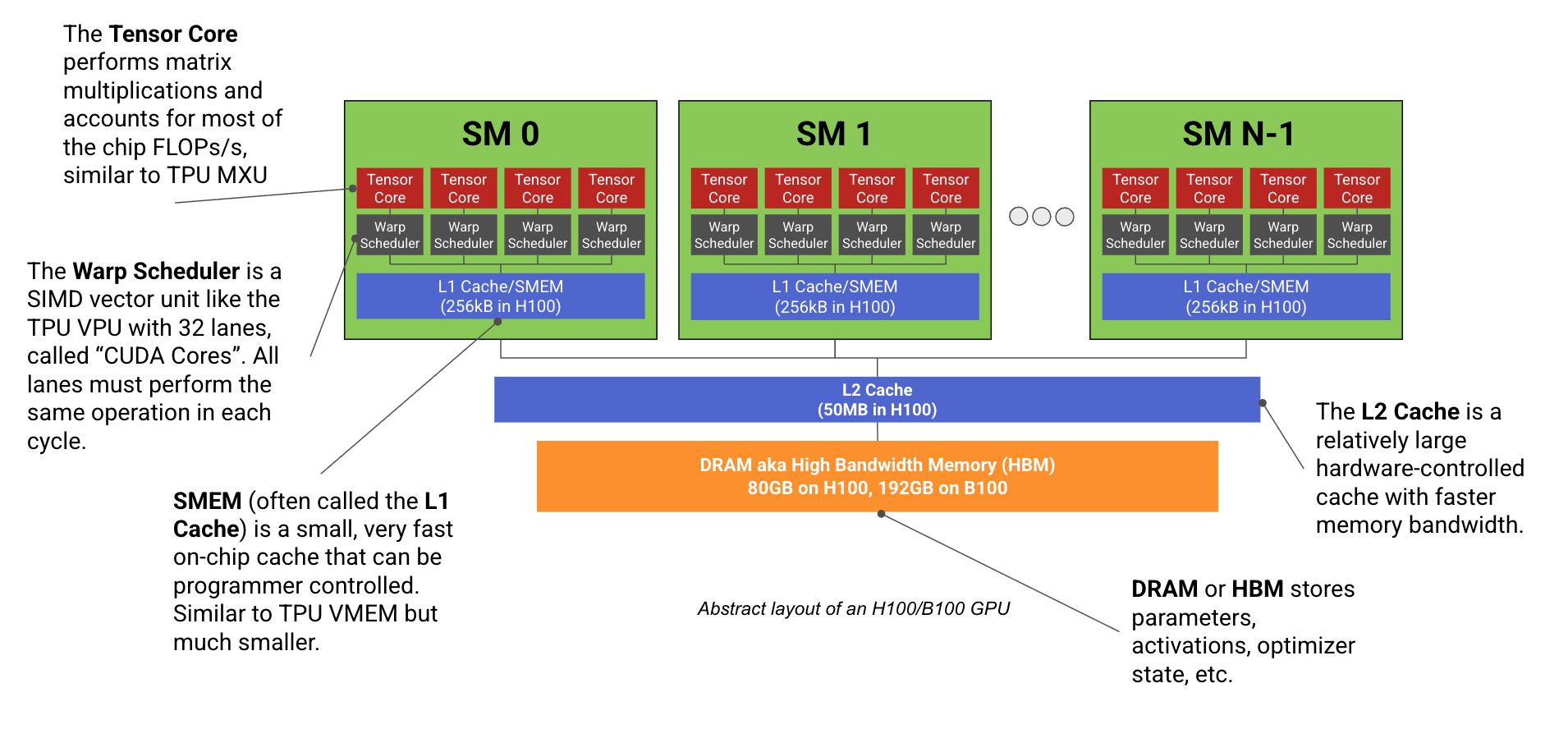
SM(Streaming Multiprocessor)— 流式多处理器
- GPU 由 132 个 SM 组成(H100)
- 每个 SM 是一个独立的计算单元,可以并行执行不同任务
- 对比:TPU 只有 1-2 个大的 TensorCore
Tensor Core — 张量核心(矩阵乘法单元)
- 每个 SM 有 4 个 Tensor Core
- 功能等价于 TPU 的 MXU
- H100 总算力:~990 bf16 TFLOP/s
CUDA Core — 通用计算核心
- 每个 SM 有 128 个 fp32 CUDA Core
- 负责向量运算(类似 TPU 的 VPU)
- 使用 SIMT(Single Instruction Multiple Threads)模型,比 TPU 的 SIMD 更灵活
内存层级
| 层级 | 容量/SM | 全芯片总量 | 带宽 | 可编程性 |
|---|---|---|---|---|
| Registers | 256 kB | ~33 MB | 即时 | 自动分配 |
| SMEM/L1 | 256 kB | ~33 MB | ~19 TB/s | 程序员可控 |
| L2 Cache | 共享 | ~50 MB | ~5.5 TB/s | 硬件管理 |
| HBM | — | 80-192 GB | 3.35-9 TB/s | 主内存 |
📋 背景知识:GPU “显存”就是 HBM 吗?
严格说,显存(VRAM) 是泛指 GPU 的专用内存,不限定技术类型;HBM 是其中一种实现技术。消费级 GPU(如 RTX 4090)使用 GDDR6X 作为显存,而数据中心 GPU(A100 / H100 / H200 / B200)使用 HBM。在大模型训练和推理语境下,所用 GPU 几乎都是 HBM 卡,因此”GPU 显存容量”和”HBM 容量”可以互换使用。
📋 背景知识:GPU L2 Cache vs TPU VMEM
GPU 的 L2 Cache(~50 MB)和 TPU 的 VMEM(128 MB)大小相近,但有本质区别:
- VMEM:程序员可控的 scratchpad,带宽 ~40 TB/s,可以精确控制什么数据何时驻留
- L2 Cache:硬件自动管理,带宽 ~5.5 TB/s(VMEM 的 1/7),程序员只能间接影响(通过修改访问模式)
- 这导致 GPU 编程有”spooky action at a distance”:一个 SM 的内存访问模式可能影响其他 SM 的 cache 命中率
- Blackwell(B200)新增了 TMEM(Tensor Memory,256 kB/SM),因为 Tensor Core 变大后输入已无法放进 SMEM
1.4 GPU vs TPU:关键对比
| 组件 | GPU | TPU | 说明 |
|---|---|---|---|
| 计算单元 | SM (×132) | TensorCore (×2) | GPU 更模块化 |
| 矩阵乘法 | Tensor Core | MXU | 功能相同 |
| 向量运算 | CUDA Core | VPU | GPU 更灵活 |
| 快速缓存 | SMEM (32MB 总) | VMEM (128MB) | TPU 缓存更大 |
| 主内存 | HBM (80GB) | HBM (96GB) | 容量相近 |
| 编程模型 | SIMT(灵活) | SIMD(简单) | GPU 更通用 |
核心差异总结:
- TPU 更简单,GPU 更灵活:TPU 就是一个大矩阵乘法机器,GPU 是由上百个小处理器组成的阵列
- TPU 的快速缓存(VMEM)远大于 GPU 的 SMEM:这让 TPU 在推理时可以把权重放在 VMEM 里
- 单颗 GPU 通常更强大:H200 FLOPs/s 约是 TPU v5p 的 2×,但价格也是 2.5×
- TPU 靠集群取胜:TPU 的互联更便宜,可以 scale 到更大的集群
🛠️ 实践:Megatron
Megatron-LM 主要针对 NVIDIA GPU 设计。它假设:
- 节点内 8 卡通过 NVLink 高速互联(~900 GB/s bidirectional on H100)
- 节点间通过 InfiniBand 连接(~400 Gb/s per port)
- Tensor Parallelism 通常限制在节点内(因为需要高带宽)
- Pipeline/Data Parallelism 可以跨节点
当你配置
--tensor-model-parallel-size 8时,Megatron 会在同一节点的 8 张卡上做 TP,充分利用 NVLink 的高带宽。
🛠️ 实践:SGLang
SGLang 的推理也需要了解 GPU 内存层级:
- 模型权重常驻 HBM
- KV cache 也在 HBM 中,SGLang 通过 RadixAttention 高效管理
--mem-fraction-static参数控制为权重预留多少 HBM,剩余给 KV cache 动态分配- Tensor Core 的利用率决定了 prefill 的吞吐量
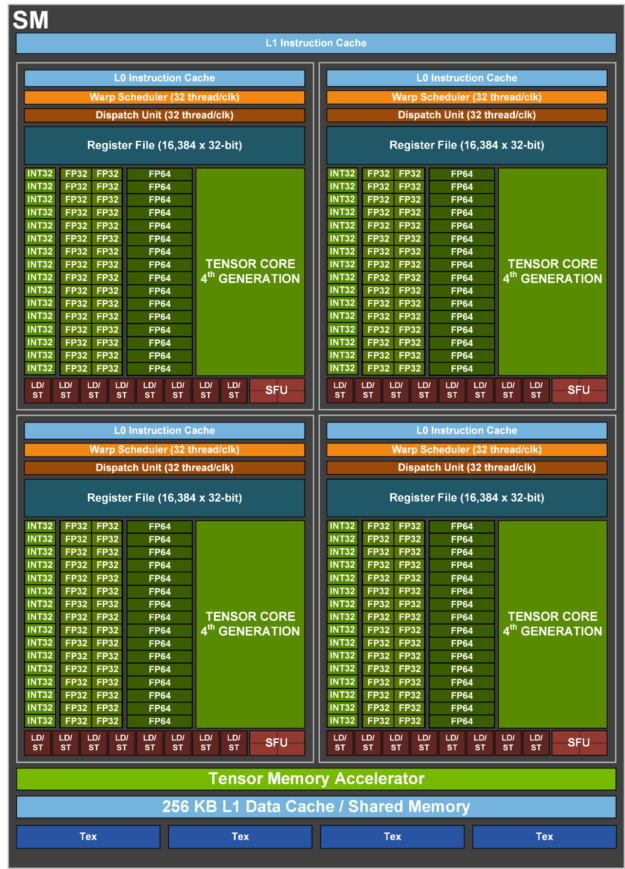
1.5 GPU 深入:SM 内部结构和编程模型
SM 内部详解
H100 的每个 SM 包含:
SM (Streaming Multiprocessor)
├── 4 个子分区(Sub-partition / Warp Scheduler)
│ ├── 1 个 Warp Scheduler + Dispatch Unit
│ ├── 16 个 FP32 CUDA Cores
│ ├── 16 个 INT32 Cores
│ ├── 1 个 Tensor Core (4th Gen)
│ └── 1 个 Load/Store Unit
├── Shared Memory / L1 Cache: 256 KB(可配置比例)
├── Register File: 256 KB
└── Texture Units
关键概念:
- Warp:32 个线程组成一个 warp,是 GPU 调度的最小单位
- SIMT:所有 warp 内的线程执行相同指令,但可以有不同的数据和控制流
- Occupancy:SM 上活跃 warp 数 / 最大 warp 数,影响延迟隐藏效果
线程层级:Grid → Block → Warp → Thread
GPU 的并行模型是一个四层层级结构:
Grid(整个 kernel 的所有线程)
├── Block 0 ──→ 映射到 SM 3
│ ├── Warp 0(Thread 0-31)
│ ├── Warp 1(Thread 32-63)
│ └── ...
├── Block 1 ──→ 映射到 SM 7
│ ├── Warp 0
│ └── ...
└── Block N ──→ 映射到 SM k
└── ...
- Grid:一次 kernel launch 创建的所有线程,按 Block 组织
- Block:被整体分配到某个 SM 上执行,同一 Block 内的线程共享该 SM 的 Shared Memory
- Warp:32 个线程组成的调度单位,是硬件实际执行的粒度
- Thread:最小的逻辑执行单元
Block 到 SM 的映射:一个 SM 可以同时驻留多个 Block(只要资源足够),但一个 Block 不会被拆分到多个 SM。Block 的数量通常远大于 SM 数量,硬件调度器负责将 Block 分配给空闲 SM。
Latency Hiding(延迟隐藏):GPU 的核心性能技巧。当一个 warp 发出内存请求后进入等待状态,warp scheduler 会立即切换到另一个就绪的 warp 继续执行——这个切换是零开销的(因为每个 warp 有独立的寄存器组,不需要保存/恢复上下文)。
Warp 0: [计算][计算][等内存...........................][计算][计算]
Warp 1: [计算][计算][等内存..............][计算]
Warp 2: [计算][计算][等内存..][计算]
↑ SM 始终在做有用的工作
这就是为什么 GPU 需要大量线程来保持高利用率:线程越多,可切换的 warp 越多,内存延迟越容易被隐藏。
🛠️ 实践:Flash Attention 中的 Block 大小选择
在 Flash Attention kernel 中,Block 大小(
BLOCK_M,BLOCK_N)直接影响 SM 资源利用:
- Block 太大 → 占用过多寄存器和 SMEM → 每个 SM 只能放 1 个 Block → 延迟隐藏不足
- Block 太小 → 数据复用率低 → 频繁读写 HBM
- 典型选择:
BLOCK_M=128, BLOCK_N=64,在两者之间取平衡
📋 背景知识:SIMT vs SIMD
- SIMD(TPU):一条指令操作一个完整向量,所有元素必须执行相同操作
- 优点:简单、高效
- 缺点:分支困难(if-else 导致 lane 浪费)
- SIMT(GPU):32 个线程组成 warp,共享指令但可以独立分支
- 优点:灵活,可以处理不规则计算(如 sparse attention)
- 缺点:分支导致 warp divergence,浪费计算
对于 LLM 训练/推理,大部分操作是规则的矩阵乘法,SIMD 和 SIMT 效率相当。 SIMT 的灵活性在写 custom kernel(如 Flash Attention、Paged Attention)时很有价值。
Tensor Core 的工作方式
H100 的 4th Gen Tensor Core:
- 每个时钟周期执行:
A[16,16] × B[16,16] + C[16,16](FP16/BF16) - 或:
A[16,16] × B[16,16] + C[16,16](FP8,TF32,INT8) - 输入:FP16/BF16/FP8/INT8
- 累加器:FP32(保持精度)
与 TPU MXU 的对比:
| Tensor Core (H100) | MXU (TPU v5e) | |
|---|---|---|
| 单元大小 | 16×16 | 128×128 |
| 数量 | 132×4 = 528 | 2 |
| 编程方式 | wmma 指令 | 编译器自动 |
| 灵活性 | 高(可混合精度) | 低(固定 pipeline) |
CUDA 编程模型(简述)
# 概念示意:GPU kernel 执行模型
# 每个 block 的 threads 共享 Shared Memory
# 不同 block 之间只能通过 Global Memory (HBM) 通信
# Grid (多个 blocks) → Block (多个 warps) → Warp (32 threads)
# Flash Attention 的高效秘密:
# 1. 将 Q, K, V 的 tile 加载到 Shared Memory
# 2. 在 Shared Memory 中做 attention 计算(避免反复读写 HBM)
# 3. 输出写回 HBM
Shared Memory 与 Bank Conflict
Shared Memory(SMEM)是 SM 内部的高速低延迟内存,是 GPU kernel 优化的核心战场。
32-Bank 结构:SMEM 被组织为 32 个 bank,每个 bank 宽 4 bytes。连续的 4-byte 字被交替分配到不同 bank:
地址 0x00 → Bank 0 地址 0x04 → Bank 1 ... 地址 0x7C → Bank 31
地址 0x80 → Bank 0 地址 0x84 → Bank 1 ... 地址 0xFC → Bank 31
...
Bank Conflict:当同一 warp 中的多个线程在同一时钟周期访问同一 bank 的不同地址时,这些访问必须串行化。例如:
| 访问模式 | 示例 | Bank Conflict |
|---|---|---|
| 连续访问 | Thread i 访问 addr[i] |
无(每线程命中不同 bank) |
| 跨步访问(stride=32) | Thread i 访问 addr[i*32] |
32-way(全部命中同一 bank) |
| 广播 | 所有线程读同一地址 | 无(硬件广播) |
避免 Bank Conflict 的方法:
- Padding:在每行末尾添加一个 dummy 元素,错开 bank 映射。例如将
float tile[32][32]改为float tile[32][33] - Swizzle:对地址进行位运算变换,使访问模式分散到不同 bank
🛠️ 实践:Flash Attention 中的 SMEM 布局
Flash Attention 需要在 SMEM 中暂存 Q、K、V 的 tile。如果
head_dim=128(每行 128 个 fp16 = 256 bytes = 64 个 bank 周期),stride 恰好是 bank 数的倍数,会导致严重 bank conflict。实际实现中通过 swizzle 或 padding 重排数据布局来避免这个问题。
Memory Coalescing(全局内存访问合并)
GPU 的全局内存(HBM)按 128-byte cache line 为单位读取。一次内存事务(memory transaction)加载一整条 cache line。
Coalesced Access(合并访问):当同一 warp 的 32 个线程访问连续的内存地址时,硬件将这些请求合并为最少的事务数:
Thread 0 → addr[0] ┐
Thread 1 → addr[1] │ 32 × 4 bytes = 128 bytes
... │ → 1 次 128-byte 事务
Thread 31 → addr[31] ┘
Uncoalesced Access(非合并访问):当线程访问不连续或跨步过大时,每个线程的请求可能触发独立事务:
Thread 0 → addr[0] → cache line 0
Thread 1 → addr[1024] → cache line 32
Thread 2 → addr[2048] → cache line 64
...
→ 最坏情况:32 次事务,带宽利用率仅 1/32(~3%)
实际影响:一个 H100 的 HBM 带宽为 3.35 TB/s,但非合并访问可能将有效带宽降至 ~100 GB/s,甚至不如 CPU 的内存带宽。
🛠️ 实践:KV Cache 的内存布局
LLM 推理中 KV cache 的内存布局直接影响 decode 性能:
- [batch, head, seq_len, head_dim]:对 attention 计算友好(连续读取同一 head 的 K/V)
- [batch, seq_len, head, head_dim]:对 prefill 友好但 decode 时跨步访问
vLLM 和 SGLang 采用的 Paged Attention 将 KV cache 分成固定大小的 block,每个 block 内部保持连续,既减少内存碎片又保持 coalesced access。
Occupancy 深入
Occupancy 衡量 SM 的线程利用程度:
\[\text{Occupancy} = \frac{\text{SM 上活跃的 warp 数}}{\text{SM 支持的最大 warp 数}}\]H100 每个 SM 最多支持 64 个 warp(= 2048 个线程)。Occupancy 受三个因素限制:
1. 寄存器用量
H100 每个 SM 有 65,536 个 32-bit 寄存器。如果每个线程使用 128 个寄存器:
\[\text{每 SM 最大线程数} = \lfloor 65536 / 128 \rfloor = 512 \text{ 线程} = 16 \text{ warps}\] \[\text{Occupancy} = 16 / 64 = 25\%\]2. Shared Memory 用量
H100 每个 SM 最多 228 KB SMEM。如果每个 Block 使用 114 KB:
\[\text{每 SM 最大 Block 数} = \lfloor 228 / 114 \rfloor = 2 \text{ Blocks}\]3. 每 Block 线程数
如果每个 Block 有 1024 线程(32 warps),则每 SM 最多 2 个 Block = 64 warps = 100%。 如果每个 Block 有 256 线程(8 warps),则每 SM 最多 8 个 Block = 64 warps = 100%(但会受前两个限制约束)。
最终 Occupancy 取三个限制中的最小值。
高 Occupancy ≠ 高性能
直觉上 Occupancy 越高越好,但实际并非总是如此:
| 策略 | Occupancy | 数据复用 | 实际性能 |
|---|---|---|---|
| 小 tile,多 warp | 高(~100%) | 低(频繁读 HBM) | 可能更慢 |
| 大 tile,少 warp | 低(~25-50%) | 高(SMEM 中复用) | 可能更快 |
Flash Attention 就是典型的”低 Occupancy 高性能”案例:它使用大量 SMEM 存储 Q/K/V tile,导致每 SM 只能放 1-2 个 Block(Occupancy ~25%),但因为几乎所有计算都在 SMEM 中完成,避免了反复读写 HBM,总体速度反而更快。
📋 背景知识:Occupancy 的”甜蜜区间”
经验上,大多数 kernel 在 Occupancy 50-75% 时性能最佳:
- 低于 50%:延迟隐藏不足,SM 容易 stall
- 高于 75%:寄存器溢出到 local memory(HBM),抵消了 occupancy 增加的收益
- 例外:compute-bound 的 matmul kernel 在低 occupancy 下也能跑满,因为计算本身就足以隐藏延迟
NVIDIA 提供
nsight compute工具分析 kernel 的 occupancy 和瓶颈。
Blackwell(B200)架构新特性
Blackwell 架构(B200/GB200)在 Hopper 基础上引入了多项关键改进:
TMEM(Tensor Memory)
Blackwell 每个 SM 新增 256 kB TMEM,专供 Tensor Core 使用:
Hopper (H100):
SMEM (256 kB) ──→ Tensor Core (4th Gen, 16×16)
↑ SMEM 够用
Blackwell (B200):
SMEM (256 kB) ──→ 非 Tensor Core 操作
TMEM (256 kB) ──→ Tensor Core (5th Gen, 更大 tile)
↑ 5th Gen Tensor Core 的输入尺寸更大,需要独立的高速 buffer
TMEM 是仅 Tensor Core 可见的存储,程序员通过专门的指令将数据从 SMEM 或 HBM 搬到 TMEM。这让 Tensor Core 的数据供给不再受 SMEM 端口竞争的影响。
FP4 精度支持
| 精度 | Blackwell 峰值 | 对比 Hopper |
|---|---|---|
| FP16/BF16 | 2.25 PFLOP/s | 990 TFLOP/s(~2.3×) |
| FP8 | 4.5 PFLOP/s | 2.0 PFLOP/s(~2.3×) |
| FP4 | 9.0 PFLOP/s | 不支持 |
FP4 将每个参数压缩到 4 bit,配合 FP4 量化技术可以在几乎不损失精度的情况下将推理吞吐量再翻倍。
Thread Block Cluster
Hopper 引入、Blackwell 增强的编程模型扩展:
传统模型:
Block 0 → SM 3(只能访问 SM 3 的 SMEM)
Block 1 → SM 7(只能访问 SM 7 的 SMEM)
↑ Block 之间只能通过 HBM 通信
Cluster 模型:
┌─── Cluster ───────────────────────┐
│ Block 0 → SM 3 ←──DSMEM──→ SM 7 ← Block 1 │
│ Block 2 → SM 8 ←──DSMEM──→ SM 9 ← Block 3 │
└───────────────────────────────────┘
↑ Cluster 内的 Block 可以直接访问彼此的 SMEM(Distributed Shared Memory)
- Cluster 最多包含 16 个 SM
- DSMEM(Distributed Shared Memory):Cluster 内的 SM 可以直接读写对方的 SMEM,延迟远低于经过 HBM
- 适用场景:需要跨 tile 通信的 kernel(如 all-reduce、halo exchange)
🛠️ 实践:Cluster 对 LLM 的意义
在 Tensor Parallel 中,matmul 后需要 all-reduce 聚合结果。传统做法是通过 NVLink(走 HBM),而 Cluster 允许在 SMEM 层级完成归约:
- 多个 SM 的部分和直接通过 DSMEM 汇总,无需写回 HBM 再读出
- 对小规模 all-reduce(如 TP=2 或 TP=4 的单节点场景)可以显著降低延迟
- CUTLASS 3.x 和 cuDNN 已开始利用 Cluster 加速 matmul + reduction 融合操作
第 5 代 Tensor Core
Blackwell 的 Tensor Core 相比 Hopper 有两个关键变化:
- 单次操作处理更大的 tile → 更高的数据复用
- 支持更多数据类型(FP4、FP6、block-scaled formats)→ 更灵活的量化策略
1.6 TPU 深入:Systolic Array 工作原理
MXU 的 Systolic Array 详解
TPU v5e 的 MXU 是一个 128×128 的 systolic array:
时间步 1: 数据开始流入
A 的第 0 行 → 从左侧进入第 0 行的 128 个 PE
B 的第 0 列 → 从上方进入第 0 列的 128 个 PE
时间步 2:
A[0] 向右传播到相邻 PE
B[0] 向下传播到相邻 PE
新的 A[1], B[1] 开始流入
时间步 3-128: 数据持续流动
每个 PE 做: accumulator += A_input × B_input
然后将 A_input 传给右边,B_input 传给下面
时间步 128+127: 最后一个结果完成
总时间:128 + 128 - 1 = 255 个时钟周期完成一次 128×128 的矩阵乘法。
关键指标:
- 128² = 16,384 个 PE
- 每个 PE 每周期做 1 次 bf16 乘加
- 每次完整 matmul:128³ × 2 = 4,194,304 FLOPs(2 是因为乘+加)
- 耗时 255 周期 → 有效利用率约 128/255 ≈ 50%(pipelining 可提升)
Systolic Array 的术语和数据流
在 TPU 文档中:
- RHS(Right Hand Side)= 权重矩阵 W(128×128),从上方流入
- LHS(Left Hand Side)= 激活/输入 X(8×128),从左侧流入
┌── RHS (权重 128×128) 从上方加载 ──┐
↓ ↓ ↓ ↓
LHS ──→ [PE] ──→ [PE] ──→ [PE] ──→ [PE] ──→ ...
(8×128) ↓ ↓ ↓ ↓
从左侧 [PE] ──→ [PE] ──→ [PE] ──→ [PE]
流入 ↓ ↓ ↓ ↓
... ... ... ...
↓ ↓ ↓ ↓
结果从下方流出 (8×128)
权重(RHS)沿对角线先部分加载,然后激活(LHS)也沿对角线流入。每个 PE 执行:accumulator += LHS_input × RHS_input,然后将 LHS 传给右邻居,RHS 传给下方邻居。
Pipelining:消除 Pipeline Bubble
单次 8×128 @ 128×128 matmul 需要 255 周期,其中前 127 周期是 pipeline fill(不是所有 PE 都在工作)。
关键优化:连续输入可以流水线化。当第一组 RHS/LHS 完成 fill 后,新的 RHS/LHS 可以立即开始加载,无需额外 bubble:
时间线:
|-- fill RHS₁ --|-- LHS₁ 流过 --|-- fill RHS₂(与 LHS₁ 重叠!)--|-- LHS₂ 流过 --|
↑ 无 bubble!
多 MXU tiling:自 TPU v3 起有多个 MXU(v3: 2个, v4/v5: 4个),需要确保 tiling 维度 > 128 × MXU数量。例如 TPU v5p 有 4 个 MXU,tiling 维度应 > 512。
Trillium(TPU v6e)的变化
TPU v6e 的 systolic array 扩大到 256×256:
- 每周期 FLOPs 增加 4×
- 张量维度需要至少 256(而非 128)才能充分利用 MXU
- 每芯片 FLOPs/s 从 ~2×10¹⁴ 跃升到 ~9.2×10¹⁴
VMEM 的使用策略
TPU 的 VMEM(128 MiB on v5e)是程序员可控的高速缓存:
典型的 matmul 数据流:
1. HBM → VMEM:预取下一个 tile 的权重
2. VMEM → MXU:供给当前计算
3. MXU → VMEM:存储中间结果
4. VMEM → HBM:写回最终结果
Double Buffering:
- Buffer A:MXU 正在使用的数据
- Buffer B:DMA 引擎正在从 HBM 预取的下一批数据
- 交替使用,计算和数据搬运完美重叠
这就是为什么 VMEM 大小很重要:更大的 VMEM → 更大的 tile → 更高的数据复用 → 更高的 MFU。
1.7 VPU 深入:向量处理单元的内部结构
VPU 内部架构
VPU 是一个二维 SIMD 向量机,形状为 (8, 128):
- 128 是 lane 轴(每个 lane 是一个独立的处理位置)
- 8 是 sublane 轴
- 每个 (lane, sublane) 位置包含 4 个独立 ALU(TPU v5p)
VREGs(向量寄存器)
- TPU v5p 每个 core 有 64 个 32-bit VREGs
- 每个 VREG 大小:
8 × 128 × 4 bytes = 4KB - 总 VREG 内存/core:
64 × 4KB = 256KB(整芯片 2× = 512KB) - 每周期可从 VMEM 加载 3 个 VREG,写回 1 个 VREG
VPU 指令执行
所有 lane 和 sublane 在每个周期执行相同的指令(纯 SIMD),但每个 ALU 可以执行不同操作。所以一个周期可以同时做 1 个 vadd 和 1 个 vsub,各操作一整个 VREG。
典型 VPU 指令:{v2 = vadd.8x128.f32 v0, v1}
💡 Pop Quiz:计算 VPU 吞吐量
TPU v5p 的时钟频率约 1.75 GHz,每个 core 每周期可在 4 个 ALU 上各执行一条向量指令(
8 × 128宽)。计算 VPU 的 FLOPs/s(整芯片)。点击查看答案
每个周期、每个 core:
8 × 128 × 4 = 4096 FLOPs整芯片(2 core):
4096 × 2 = 8192 FLOPs/cycleVPU FLOPs/s =
8192 × 1.75e9 = 1.4×10¹³ FLOPs/s对比 MXU 的 ~4.6×10¹⁴ FLOPs/s → VPU 只有 MXU 的 ~3%(约 30× 差距)。
这就是为什么 Transformer 中非 matmul 操作(LayerNorm、Softmax、GeLU)虽然 FLOPs 少,但在 roofline 分析中可能成为瓶颈。
归约操作(Reductions)
- sublane 内归约(沿 8 维度):有 shuffle 操作,可在约 1 周期完成滚动。只需 shuffle 4→2→1 做 3 次加法即可完成归约。
- lane 间归约(沿 128 维度):需要专门的 XLU(Cross Lane Unit),速度慢且昂贵。
对于 GPU 使用者的类比:VPU 的每个 ALU ≈ CUDA Core,VPU 的一个 lane ≈ Warp Scheduler(32 个 CUDA Core 的 SIMD 组)。lane 内操作快,跨 lane 需要经过 VMEM/XLU/SMEM,类似 GPU 跨 warp 通信。
Scalar Core(标量核心)
Scalar Core 是 TPU 的控制单元:
- 取指、分发所有指令
- 控制 HBM → VMEM 的 DMA 传输
- 单线程:每个 core 每周期只能创建一个 DMA 请求
一个 Scalar Core 控制着:1 个 VPU(4096 ALUs)、4 个 MXUs、2 个 XLUs、多个 DMA 引擎。这种”少控制、多计算”的设计是硬件效率的来源,但也限制了数据依赖的向量化灵活性。
1.8 为什么矩阵乘法如此特殊
📋 背景知识
矩阵乘法
C[M,N] = A[M,K] × B[K,N]的特殊性:
- 计算量:O(M×K×N) = O(n³)(对方阵而言)
- 数据量:O(M×K + K×N + M×N) = O(n²)
- 比值:做 n³ 次运算只需要加载 n² 个数据 → 每加载一个数据可以做 ~n 次运算
这意味着只要矩阵够大,计算时间远大于数据加载时间 → compute-bound。 相比之下,逐元素操作(如 ReLU)是 O(n) 计算 / O(n) 数据 → 永远是 memory-bound。
这就是为什么 TPU/GPU 把绝大部分晶体管面积给了矩阵乘法单元。
硬件设计的平衡点
硬件设计者需要平衡三个资源:
- 算力(FLOPs/s):Tensor Core / MXU 的数量和速度
- 带宽(bytes/s):HBM 和片上缓存的数据通路
- 容量(bytes):能存多少模型参数和激活值
设计原则:让典型 workload(batch size ~256-1024 的矩阵乘法)恰好处于 compute-bound 的临界点。
| 硬件 | 算力/带宽比(FLOPs per Byte) | 含义 |
|---|---|---|
| TPU v5e | 240 | batch > 240 tokens 时 compute-bound |
| H100 | 295 | batch > 295 tokens 时 compute-bound |
| B200 | 281 | 带宽增长追上了算力增长 |
趋势:每一代硬件的 FLOPs/s 增长速度快于带宽增长,导致临界 batch size 逐代增大。这对推理不利(decode 阶段 batch 天然小)。
1.9 各代硬件规格速查表
TPU 规格
| 型号 | HBM 容量 | HBM 带宽 | bf16 FLOPs/s | int8 OPs/s |
|---|---|---|---|---|
| TPU v3 | 32 GB | 900 GB/s | 1.4×10¹⁴ | 1.4×10¹⁴ |
| TPU v5e | 16 GB | 810 GB/s | 2.0×10¹⁴ | 3.9×10¹⁴ |
| TPU v5p | 96 GB | 2.8 TB/s | 4.6×10¹⁴ | 9.2×10¹⁴ |
| TPU v6e | 32 GB | 1.6 TB/s | 9.2×10¹⁴ | 1.8×10¹⁵ |
GPU 规格
| 型号 | HBM 容量 | HBM 带宽 | bf16 FLOPs/s | fp8 OPs/s |
|---|---|---|---|---|
| A100 | 80 GB | 2.0 TB/s | 3.1×10¹⁴ | 6.2×10¹⁴ |
| H100 | 80 GB | 3.4 TB/s | 9.9×10¹⁴ | 2.0×10¹⁵ |
| H200 | 141 GB | 4.8 TB/s | 9.9×10¹⁴ | 2.0×10¹⁵ |
| B200 | 192 GB | 8.0 TB/s | 2.3×10¹⁵ | 4.5×10¹⁵ |
1.10 Worked Problems(习题与详解)
Problem 1:内存层级时间
题目:在 H100 上,从不同内存层级加载一个 bf16[128, 128] 的矩阵需要多久?
- Registers:假设即时可用
- Shared Memory:~19 TB/s 带宽
- L2 Cache:~12 TB/s
- HBM:3.35 TB/s
点击查看答案
矩阵大小:128 × 128 × 2 bytes = 32 KB
- Registers:0(已经在计算单元中)
- Shared Memory:
32e3 / 19e12 = 1.7 ns - L2 Cache:
32e3 / 12e12 = 2.7 ns - HBM:
32e3 / 3.35e12 = 9.6 ns
从 HBM 加载比从 SMEM 加载慢 5.6×。这就是为什么 Flash Attention 通过在 SMEM 中完成整个 attention 计算来避免反复访问 HBM。
Problem 2:MXU 利用率
题目:TPU v5e 的 MXU 是 128×128 systolic array。如果你的矩阵维度不是 128 的倍数(如 [100, 100] × [100, 100]),实际硬件利用率是多少?
点击查看答案
Systolic array 必须填满 128×128 的方阵才能运行。100×100 的矩阵需要 padding 到 128×128。
- 有效计算:
100 × 100 × 100 × 2 = 2M FLOPs - 实际计算:
128 × 128 × 128 × 2 = 4.2M FLOPs - 利用率:
2M / 4.2M = 47.6%
这就是为什么 Transformer 的隐藏维度通常设为 128 的倍数(如 4096、8192、12288)——确保 MXU/Tensor Core 被完全利用。
Problem 3:Tensor Core vs MXU 对比
题目:H100 有 528 个 Tensor Core(132 SM × 4),每个每周期做 16×16×16 bf16 matmul。TPU v5e 有 2 个 MXU,每个是 128×128 systolic array。
哪个峰值 FLOPs/s 更高?假设 H100 时钟 1.83 GHz,TPU v5e 时钟 1.0 GHz。
点击查看答案
H100:
- 每 Tensor Core 每周期:
16 × 16 × 16 × 2 = 8,192 FLOPs - 528 个 Tensor Core:
528 × 8192 = 4.33M FLOPs/cycle - 峰值:
4.33e6 × 1.83e9 = 7.9×10¹⁴ FLOPs/s
(注:NVIDIA 官方标称 ~990 TF bf16,包含一些 micro-architecture 优化)
TPU v5e:
- 每 MXU 每周期:
128 × 128 × 2 = 32,768 FLOPs(每 PE 一次 MAC) - 2 个 MXU:
2 × 32768 = 65,536 FLOPs/cycle - 但 systolic array 需要 128 周期 fill + 128 周期 drain → 有效约 128/256 ≈ 50% 利用
- 峰值(理想):
65536 × 1e9 = 6.5×10¹³ - 加上 pipelining 优化:约 1.97×10¹⁴ FLOPs/s(官方值)
结论:H100 峰值约为 TPU v5e 的 5×,但价格也更高。
Problem 4:推理延迟下界
题目:你有一个 200B 参数的 bf16 模型,分片到 32 颗 TPU v4p 上。从 HBM 加载所有参数到 systolic array 需要多久?这对推理延迟意味着什么?
点击查看答案
总数据量:2 × 200e9 = 400 GB。32 颗芯片,每颗加载 400e9 / 32 = 12.5 GB。
TPU v4p 的 HBM 带宽为 1.2×10¹² B/s:
\[T = \frac{12.5 \times 10^9}{1.2 \times 10^{12}} \approx 10\text{ms}\]关键洞察:这是 Generation 阶段每步延迟的下界。每一步都需要从 HBM 加载全部参数,因此不可能比 10ms 更快。在小 batch 下,实际时间接近这个值。
Problem 5:TPU Pod 计算
题目:计算 TPU v5e 和 v5p 完整 Pod 的以下参数:CPU host 数量、TensorCore 数量、总 FLOPs/s、总 HBM 容量。
点击查看答案
TPU v5e Pod(16×16 = 256 chips):
- Host 数:每 host 连接 4×2=8 chips →
256 / 8 = 32个 host - TensorCore 数:每 chip 1 core → 256 个 TensorCore
- 总 FLOPs/s:
256 × 2e14 = 5.1×10¹⁶bf16 FLOPs/s - 总 HBM:
256 × 16 GB = 4 TB
TPU v5p Pod(16×20×28 = 8960 chips):
- Host 数:每 host 连接 2×2×1=4 chips →
8960 / 4 = 2,240个 host - TensorCore 数:每 chip 2 core → 17,920 个 TensorCore
- 总 FLOPs/s:
8960 × 4.59e14 = 4.1×10¹⁸bf16 FLOPs/s(4 EFLOPS!) - 总 HBM:
8960 × 96 GB = 860 TB
一个 v5p Pod 就是世界上最强大的超算之一。
Problem 6:PCIe 算术强度
题目:假设权重矩阵 bf16[D, F] 和激活 bf16[B, D] 存储在 host DRAM 中,通过 PCIe 加载到单颗 TPU v6e 上做 matmul。假设 B « D,F = 4D。PCIe 带宽 1.5×10¹⁰ B/s。要保持 compute-bound,B 最小需要多大?
点击查看答案
FLOPs = $2BDF$,TPU v6e 可做 9.2×10¹⁴ FLOPs/s。
通过 PCIe 需要传输:2(BD + DF + BF) bytes。
Compute-bound 条件(假设 F=4D, B«D):
\[\frac{2BDF}{9.2 \times 10^{14}} > \frac{2(BD + DF + BF)}{1.5 \times 10^{10}}\]简化(B«D → BD 项可忽略,DF 主导):
\[\frac{8BD^2}{9.2 \times 10^{14}} > \frac{8D^2}{1.5 \times 10^{10}}\] \[B > \frac{9.2 \times 10^{14}}{1.5 \times 10^{10}} \approx 61{,}000\]需要 batch > 61,000! PCIe 的带宽比 HBM 低 ~50×,所以临界 batch size 也高 ~250×。这就是为什么不应该从 host DRAM 做 matmul。
Problem 7:通用 Matmul 延迟分析
题目:在单颗 TPU v5e 上执行 int8[16384, 4096] × int8[B, 4096] matmul:
- 从 HBM 读取时,T 关于 B 的表达式是什么?临界 batch size 是多少?
- 如果从 VMEM 读取呢?
点击查看答案
(1) 从 HBM:
- FLOPs = $2 \times 4096 \times 16384 \times B = 1.3 \times 10^8 \times B$
- $T_{\text{math}} = 1.3\text{e}8 \times B / 3.94\text{e}14$
- 需要加载:$16384 \times 4096 + 4096 \times B = 6.7\text{e}7 + 4096B$ bytes(int8)
- 写回:$16384 \times B$ bytes
- $T_{\text{comms}} = (6.7\text{e}7 + 2\text{e}4 \times B) / 8.1\text{e}11$
Compute-bound 条件:
\[\frac{6.7\text{e}7 + 2\text{e}4 \cdot B}{8.1\text{e}11} < \frac{1.3\text{e}8 \cdot B}{3.94\text{e}14}\]解得 B > 271(比 bf16 的 240 稍大,因为考虑了完整的 D 和 F 影响)。
(2) 从 VMEM:
VMEM 带宽 ≈ 22× HBM。分母从 8.1e11 变为 1.78e13:
解得 B > 11。从 VMEM 做 matmul,仅需 B ≈ 11 就是 compute-bound!(实际约 20,因为不能独占全部 VMEM 带宽)
Problem 8:CUDA Core 计数与向量 FLOPs
题目:
- H100 和 B200 各有多少 fp32 CUDA Core?对比 TPU v5p 的 VPU ALU 数量。
- H100 运行在 1.59 GHz(boost 1.98 GHz),每 ALU 每周期做 1 次向量操作。计算向量 fp32 FLOPs/s。与 Tensor Core 的 matmul FLOPs/s 的比值?
点击查看答案
(1) CUDA Core 数量:
- H100:132 SM × 4 子分区 × 32 fp32 cores = 16,896 CUDA Cores
- B200:148 SM × 4 × 32 = 18,944 CUDA Cores
- TPU v5p:2 core × 4 ALUs × 8 × 128 = 8,192 ALUs
GPU 的向量 ALU 数量约为 TPU 的 2×,运行频率相近。
(2) 向量 FLOPs/s:
\[16896 \times 1.59\text{e}9 = 26.9 \text{ TFLOPs/s}\]boost:$16896 \times 1.98\text{e}9 = 33.5$ TFLOPs/s
(NVIDIA 官方标称 67 TFLOPs/s,因为算了 FMA 的 2 FLOPs,但这在大多数场景不实用)
向量 vs matmul 比值:33.5 / 990 ≈ 1/30。Tensor Core 的 matmul 能力是 CUDA Core 向量运算的 30×。
Problem 9:GPU Matmul 算术强度与运行时间
题目:
- H100 和 B200 的 fp16 matmul 算术强度(peak intensity = FLOPs/s ÷ HBM BW)是多少?
- 在 B200 上执行
fp16[64, 4096] × fp16[4096, 8192]和fp16[512, 4096] × fp16[4096, 8192]各需要多久?
点击查看答案
(1) 算术强度:
- H100:
990e12 / 3.35e12 = 295 - B200:
2250e12 / 8e12 = 281
与 TPU v5e 的 240 相近。意味着 batch > ~280 时 matmul 是 compute-bound。
fp8 下强度翻倍(~590, ~562),但如果权重也用 fp8 加载则每 byte 的 FLOPs 不变。
(2) 运行时间:
B=64(memory-bound):总数据 = 2×64×4096 + 2×4096×8192 + 2×64×8192 = 69 MB
\(T = 69\text{e}6 / 8\text{e}12 = 8.6\mu s\)(实测约 10-12μs)
B=512(compute-bound):FLOPs = 2×512×4096×8192 = 3.44×10¹⁰
\(T = 3.44\text{e}10 / 2.3\text{e}15 = 15\mu s\)(实测约 20μs)
Problem 10:GPU L1/SMEM 容量对比
题目:H100 的总 L1/SMEM 容量是多少?加上 Register File 呢?和 TPU VMEM 对比如何?
点击查看答案
- SMEM:132 SM × 256 kB = 33 MB
- Registers:132 SM × 256 kB = 33 MB
- 总计:66 MB
对比 TPU v5p 的 VMEM = 128 MB(约 2×),加上 TPU 只有 256 KB VREG。
关键差异:TPU VMEM 延迟更低(spill/fill 到 VMEM 很便宜),所以 VREG 少不是大问题。GPU 的 register file 大但每线程只能用 256 个,高 occupancy 时更受限。
Problem 11:向量加法运行时间
题目:在 H100 上将两个 fp32[N] 向量相加。计算 $T_{\text{math}}$ 和 $T_{\text{comms}}$。对 N = 65,536 和 N = 1,073,741,824(1G)分别是多少?
点击查看答案
- FLOPs = N(一次加法)
- 数据量 = 读
4N × 2+ 写4N= 12N bytes - 算术强度 = N / 12N = 1/12(极低!)
向量 FLOPs/s = 33.5 TFLOPs/s(boost),HBM BW = 3.35 TB/s
\[T = \max\left(\frac{N}{33.5\text{e}12}, \frac{12N}{3.35\text{e}12}\right) = \frac{12N}{3.35\text{e}12} = \frac{N}{2.8\text{e}11}\]严重 memory-bound!
- N = 65,536:roofline ≈ 0.23μs(实测 ~1.5μs,latency-bound)
- N = 1G:roofline ≈ 3.84ms(实测 ~4.1ms,接近理论值)
Problem 12:ICI 传输时间
题目:TPU v5e 4×4 slice 上,将 bf16[8, 128, 8192] 从 TPU{0,0} 发送到 TPU{3,3}。单跳延迟 1μs。第一个字节何时到达?总传输需要多久?
点击查看答案
TPU v5e 4×4 没有环绕连接(需要轴 = 16 才有)。从 (0,0) 到 (3,3) 需要 6 跳(X 方向 3 跳 + Y 方向 3 跳)。
数据量:2 × 8 × 128 × 8192 = 16.8 MB
可以同时沿两个方向发送(各用一半数据),带宽 = 2 × 4.5e10 = 9e10 B/s:
- 第一个字节到达:6 跳 × 1μs = 6μs
- 总传输时间:约 188μs(带宽限制主导)
Problem 13:综合挑战题
题目:一个 int8[128×1024, 128×1024] 矩阵(~16 GB)均匀分片在 TPU v5e 4×4 slice 上,但卸载到了 host DRAM 中。你想把整个矩阵搬到 TPU{0,0} 并乘以 bf16[8, 128×1024]。需要多久?
点击查看答案
TPU v5e 4×4 有 2 个 host(每 host 管理 4×2=8 chips)。数组均匀分片,每 host 持有 8 GB。
方案选择:
- ❌ 通过 DCN 传到 host 0 再 PCIe 加载(DCN 太慢)
- ✅ 每颗 TPU 通过 PCIe 加载自己的 shard → 通过 ICI gather 到 TPU{0,0}
各阶段耗时:
-
PCIe 加载:16 GB / 16 chips = 1 GB/chip。16 条 PCIe 并行加载,每条 1.5×10¹⁰ B/s: \(T_1 = 1\text{e}9 / 1.5\text{e}10 = 66\text{ms}\)
-
ICI gather 到 TPU{0,0}:TPU{0,0} 只有 2 个 ICI 端口,需要接收 15 GB。 \(T_2 \geq 15\text{e}9 / (2 \times 4.5\text{e}10) = 167\text{ms}\)
(负载不均衡,实际可能 ~200ms)
-
HBM → MXU 加载:16 GB / 8.1×10¹¹ = 19ms
-
计算 FLOPs:$2 × 8 × 128^2 × 1024^2 = 2.7×10^{11}$ →
2.7e11 / 1.97e14 = 1.3ms
总时间 ≈ max(66, 167, 19, 1.3) ≈ 167ms(ICI gather 主导)。实际约 200ms(因重叠不完美)。
关键要点
- TPU = MXU(矩阵乘法)+ VPU(向量运算)+ VMEM(快速缓存)+ HBM(主内存)
- GPU = 多个 SM × (Tensor Core + CUDA Cores + SMEM) + L2 Cache + HBM
- TPU 芯片通常 = 2 个 TensorCore(megacore),通过 tray 连接到 CPU host
- TPU 的 MXU 是 128×128 Systolic Array,数据脉动式流过,最大化复用
- Systolic Array 的 pipelining 可以消除 pipeline bubble,连续 matmul 无额外开销
- GPU 的 Tensor Core 是 16×16 的小矩阵单元,但数量多(528 个)
- SIMT(GPU)比 SIMD(TPU)更灵活,适合写 custom kernel
- GPU 线程层级 Grid → Block → Warp → Thread,Block 整体映射到 SM,warp 是调度最小单位
- Latency Hiding 是 GPU 性能的关键:warp scheduler 零开销切换 warp,用计算掩盖内存延迟
- SMEM 有 32 bank,同一 warp 访问同一 bank 不同地址会产生 bank conflict,需要 padding/swizzle 避免
- 全局内存按 128-byte cache line 读取,非连续访问可能导致带宽利用率降至 1/32
- Occupancy 50-75% 通常是性能甜蜜区间;高 occupancy 不一定优于低 occupancy + 高数据复用
- Blackwell 新增 TMEM(Tensor Core 专用存储)、FP4 支持、Thread Block Cluster(跨 SM 的 DSMEM)
- VPU 的 FLOPs/s 只有 MXU 的 ~3%(约 30× 差距),非 matmul 操作可能成为瓶颈
- Double Buffering 让计算和数据搬运重叠,接近理论 roofline
- VMEM 带宽是 HBM 的 22×,权重放 VMEM 后只需 B ≈ 11 就能 compute-bound
- 矩阵乘法特殊在于 O(n³) 计算 / O(n²) 数据,天然适合被硬件加速
- 硬件设计的平衡点决定了临界 batch size(~240-300)
- 通过 PCIe 做 matmul 需要 B > 61,000 才是 compute-bound — 必须用 HBM
- 每一代硬件算力增长快于带宽,推理对 batch 要求越来越高
- 矩阵维度应为 128 的倍数(v6e 为 256)以充分利用 MXU/Tensor Core
- 在 Megatron 中,硬件拓扑直接决定并行策略的配置