本章目标:掌握 Roofline 模型——用一个简单框架判断任何算法在硬件上是”算力瓶颈”还是”带宽瓶颈”,并通过大量习题建立定量分析直觉。
对应原书:Chapter 1 (All About Rooflines)
改写范围:基本沿原书 Roofline 主线展开,额外加入 GPU、MFU 和推理系统里的使用方式。 建议时间:Day 2, 约 3-4 小时(含习题)
2.1 核心问题:时间都去哪了?
一个深度学习模型本质上是一堆矩阵乘法,每个矩阵乘法由浮点乘加运算(FLOPs)组成。当我们在加速器上运行一个算法时,时间消耗来自两个根本来源:
2.1.1 计算时间
加速器的速度决定了计算需要多长时间:
\[T_{\text{math}} = \frac{\text{总 FLOPs}}{\text{加速器 FLOPs/s}}\]具体数字:
- NVIDIA H100:约
9.89×10¹⁴bf16 FLOPs/s(注意:官方标称的1.979×10¹⁵是带 structured sparsity 的,实际密集计算约为一半) - TPU v6e:约
9.1×10¹⁴bf16 FLOPs/s - TPU v5e:约
1.97×10¹⁴bf16 FLOPs/s
例如,在 H100 上执行 1×10¹² FLOPs:1e12 / 9.89e14 ≈ 1.01ms
2.1.2 通信时间
数据搬运也需要时间。通信发生在两个层面:
芯片内通信:张量需要在 HBM(高带宽内存)和计算核心之间传输。
- H100 HBM 带宽:
3.35 TB/s - TPU v6e HBM 带宽:
1.6 TB/s - TPU v5e HBM 带宽:
0.82 TB/s
芯片间通信:当模型分布在多个加速器上时,张量需要在芯片之间传输。
- TPU v5e ICI(芯片间互联):
~45 GB/s每方向 - H100 NVLink:
~450 GB/s(双向 900 GB/s)
无论哪种通信,时间估算公式相同:
\[T_{\text{comms}} = \frac{\text{总搬运字节数}}{\text{带宽 (bytes/s)}}\]2.1.3 重叠与边界
关键洞察:计算和通信通常可以重叠(通过流水线化)。这意味着:
\[T_{\text{lower bound}} = \max(T_{\text{math}}, T_{\text{comms}})\] \[T_{\text{upper bound}} = T_{\text{math}} + T_{\text{comms}}\]在实践中,我们以 lower bound 为优化目标,因为:
- 代数更简单
- 通过精心设计 pipeline,通常可以接近这个下界
- 即使无法完美重叠,上下界之间最多差 2 倍:$T_{\text{math}} + T_{\text{comms}} \leq 2 \times \max(T_{\text{math}}, T_{\text{comms}})$
当 $T_{\text{math}} > T_{\text{comms}}$ 时,硬件被充分利用,称为 compute-bound。
当 $T_{\text{comms}} > T_{\text{math}}$ 时,计算单元在等待数据,称为 communication-bound(或 memory-bound)。
📋 背景知识:流水线(Pipeline)重叠
“重叠”是指在硬件层面同时执行计算和数据搬运。类比:
- 你在洗碗(计算),同时洗衣机在运转(通信)——两件事并行进行
- 如果洗碗要 10 分钟,洗衣机要 8 分钟,总时间是 10 分钟(不是 18 分钟)
在 GPU/TPU 上,这通过 DMA 引擎实现:当计算核心在处理当前 tile 时,DMA 引擎可以同时从 HBM 预取下一个 tile 的数据。这就是为什么我们用 max 而不是 sum 来估算时间。
但完美重叠需要精心设计的 software pipeline(如 double buffering),否则实际时间会介于 max 和 sum 之间。
🔗 与 MFU 的联系
MFU(Model FLOPs Utilization)= 实际吞吐 FLOPs/s ÷ 硬件峰值 FLOPs/s。
- MFU = 100% 意味着完美 compute-bound,硬件每个周期都在做有用计算
- MFU = 30% 意味着 70% 的时间硬件在等待数据
- 业界优秀的训练系统 MFU 通常在 40-60%(因为还有 optimizer step、gradient sync 等开销)
Roofline 模型就是理解 MFU 为什么不是 100% 的分析工具。
2.2 算术强度(Arithmetic Intensity)
判断一个算法是 compute-bound 还是 memory-bound 的关键指标是算术强度(也叫操作强度):
\[\text{Arithmetic Intensity} = \frac{\text{总 FLOPs}}{\text{总搬运 Bytes}}\]它衡量的是:每搬运 1 byte 数据,能做多少次浮点运算。
判断规则
每个硬件都有一个临界算术强度(critical arithmetic intensity):
\[\text{临界 AI} = \frac{\text{峰值 FLOPs/s}}{\text{带宽 Bytes/s}}\]- 如果算法的 AI > 硬件的临界 AI → Compute-bound(好!算力被充分利用)
- 如果算法的 AI < 硬件的临界 AI → Memory-bound(差!算力在空转等数据)
各硬件的临界算术强度:
| 硬件 | 峰值 FLOPs/s (bf16) | HBM 带宽 | 临界 AI |
|---|---|---|---|
| TPU v5e MXU | 1.97×10¹⁴ | 8.2×10¹¹ B/s | 240 FLOPs/Byte |
| H100 SXM | ~1.0×10¹⁵ | 3.35×10¹² B/s | ~298 FLOPs/Byte |
| TPU v6e | 9.1×10¹⁴ | 1.6×10¹² B/s | ~569 FLOPs/Byte |
📋 背景知识:为什么不同硬件的临界 AI 不同?
临界 AI 反映了硬件设计的”平衡点”:
- TPU v5e(240):计算和带宽比较均衡,适合中等 batch 的训练
- H100(~298):计算能力极强,需要更大的 batch 才能喂饱
- TPU v6e(~569):计算能力大幅提升但带宽没有同比增长,对 batch size 要求更高
这就是为什么新一代硬件虽然 FLOPs/s 更高,但如果你的 workload 不够大,反而可能利用率更低。
例子:向量点积
计算 x · y,其中 x, y ∈ bf16[N]:
- 加载:
2N + 2N = 4Nbytes(两个向量) - 计算:
N次乘法 +N-1次加法 =2N-1FLOPs - 写回:
2bytes
算术强度只有 0.5 FLOPs/Byte,远低于任何硬件的临界值(240+)。这意味着向量点积永远是 memory-bound——无论向量多长,计算核心大部分时间都在等数据。
这就是为什么 LayerNorm、ReLU、Softmax 等逐元素操作虽然 FLOPs 占比很小,但可能占据不少时间——它们的算术强度极低,除非能和其他操作 fuse 在一起。
2.3 Roofline 图的可视化
Roofline 图是一个对数-对数坐标图,将算术强度和可达性能的关系可视化:
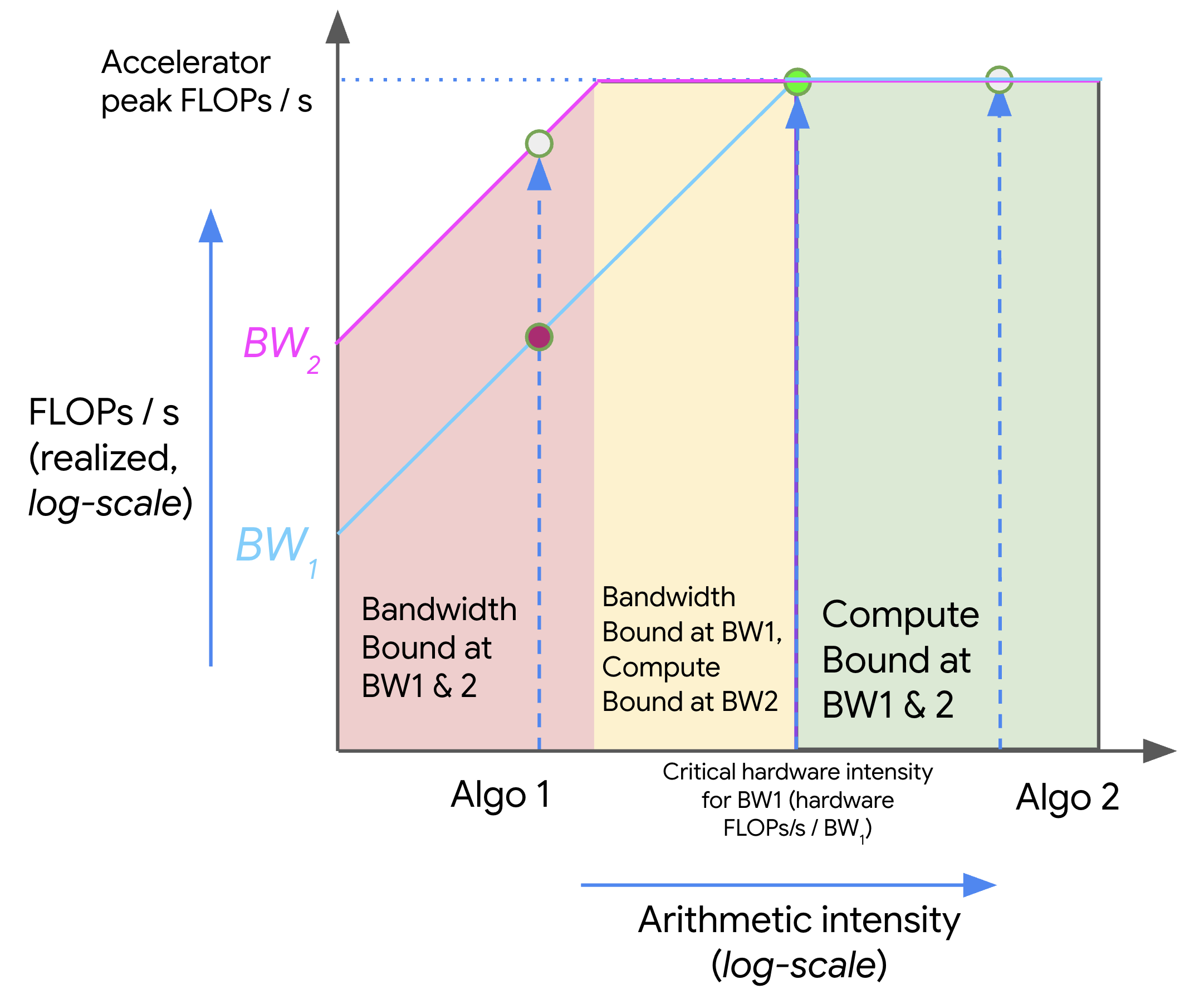
图的解读:
- X 轴(对数):算法的算术强度(FLOPs/Byte)
- Y 轴(对数):算法能达到的实际吞吐量(FLOPs/s)
- 水平线(”屋顶”):硬件的峰值 FLOPs/s,这是不可逾越的上限
- 斜线(”墙壁”):带宽限制线,斜率 = 带宽(Bytes/s)
三个区域:
- 红色区域(低 AI):在所有带宽下都是 bandwidth-bound,算力严重浪费
- 黄色区域(中等 AI):在低带宽下 bandwidth-bound,在高带宽下可能 compute-bound
- 绿色区域(高 AI):在所有带宽下都是 compute-bound,硬件被充分利用
如何改善性能:
- 增加算术强度(增大 batch size、使用更高效的算法)→ 向右移动
- 增加带宽(使用更高带宽的内存层级,如 VMEM/SRAM)→ 斜线变陡,黄色区域缩小
🛠️ 实践:如何画 Roofline 图
import matplotlib.pyplot as plt import numpy as np # 硬件参数 peak_flops = 1.97e14 # TPU v5e bf16 FLOPs/s hbm_bw = 8.2e11 # TPU v5e HBM bandwidth # 算术强度范围 ai = np.logspace(-1, 4, 1000) # 0.1 到 10000 FLOPs/Byte # Roofline: min(peak_flops, ai * bandwidth) achievable_flops = np.minimum(peak_flops, ai * hbm_bw) plt.figure(figsize=(10, 6)) plt.loglog(ai, achievable_flops, 'b-', linewidth=2) plt.axhline(y=peak_flops, color='r', linestyle='--', alpha=0.5, label='Peak FLOPs/s') plt.axvline(x=peak_flops/hbm_bw, color='g', linestyle='--', alpha=0.5, label=f'Critical AI = {peak_flops/hbm_bw:.0f}') plt.xlabel('Arithmetic Intensity (FLOPs/Byte)') plt.ylabel('Achievable FLOPs/s') plt.title('TPU v5e Roofline') plt.legend() plt.grid(True, alpha=0.3) plt.show()
2.4 矩阵乘法的 Roofline 分析
矩阵乘法是深度学习中最核心的操作。让我们详细分析它的算术强度。
基本分析
对于 $X \cdot Y \rightarrow Z$,其中 $X \in \text{bf16}[B, D]$,$Y \in \text{bf16}[D, F]$,$Z \in \text{bf16}[B, F]$:
- 加载字节数:$2BD + 2DF$ bytes(X 和 Y 各元素 2 bytes)
- FLOPs:$2BDF$(每个输出元素需要 D 次乘法 + D-1 次加法 ≈ 2D FLOPs,共 BF 个输出元素)
- 写回字节数:$2BF$ bytes
关键简化
在 Transformer 中,通常 $B$(token batch size)远小于 $D$ 和 $F$(隐藏维度通常 > 8000)。此时分母中 $DF$ 项占主导:
\[\text{AI} \approx \frac{BDF}{DF} = B\]这给出了一个极其简洁的规则:
矩阵乘法的算术强度 ≈ batch size(token 数)
因此,对于 TPU v5e(临界 AI = 240):
\[\text{Compute-bound} \iff B > 240 \text{ tokens}\]对于 H100(临界 AI ≈ 298):
\[\text{Compute-bound} \iff B > 298 \text{ tokens}\]📋 背景知识:这里的 B 是 token 数,不是 sequence 数
假设你的训练配置:
- Global batch size = 512 sequences
- Sequence length = 4096 tokens
- 总 token 数 = 512 × 4096 = 2,097,152 tokens
- 使用 128 张卡做 Data Parallelism
- Per-replica batch = 2,097,152 / 128 = 16,384 tokens
- 16,384 » 240,所以训练时矩阵乘法是 compute-bound ✓
但在推理的 generation 阶段:
- 每次只处理 1 个新 token(per request)
- 即使 batch 了 64 个请求,也只有 64 tokens
- 64 < 240,所以 generation 是 memory-bound ✗
这就是训练和推理性能特性完全不同的根本原因。
Tile Size 的影响
上面的分析假设我们一次性加载整个矩阵。但实际上,大矩阵乘法需要被分解成小的 tile 来适配片上高速内存(TPU 的 VMEM、GPU 的 Shared Memory/TMEM)。
考虑 $(m, k) \times (k, n)$ 的矩阵乘法,tile 大小为 $bm \times bk$ 和 $bk \times bn$:
- 令 $tm = m/bm$,$tn = n/bn$,$tk = k/bk$
- 总 FLOPs = $2 \cdot tm \cdot tn \cdot tk \cdot bm \cdot bn \cdot bk$
- 总加载字节 ≈ $2 \cdot tm \cdot tn \cdot tk \cdot (bm \cdot bk + bk \cdot bn)$
简化后的算术强度:
\[\text{AI}(\text{tiled matmul}) \approx \frac{bm \cdot bn}{bm + bn}\]这意味着 tile 越大,算术强度越高。例如:
- tile = 128×128:AI ≈ 64
- tile = 256×256:AI ≈ 128
- tile = 512×512:AI ≈ 256
这就是为什么 TPU 的 MXU(128×128)和 GPU 的 Tensor Core 都设计了较大的矩阵运算单元——更大的 tile 意味着更高的数据复用率。
🛠️ 实践:Megatron-LM 中的 Batch Size 选择
Megatron-LM 训练大模型时,per-replica batch size 的选择直接影响 MFU:
# Megatron-LM 典型配置(LLaMA 70B) # 假设 TP=8, PP=4, DP=16 (总共 512 张 H100) global_batch_size = 2048 # sequences seq_len = 4096 total_tokens = 2048 * 4096 = 8,388,608 per_replica_tokens = total_tokens / DP = 8,388,608 / 16 = 524,288 # 524,288 >> 298,compute-bound ✓但如果 global batch size 太小(比如 32 sequences):
per_replica_tokens = 32 * 4096 / 16 = 8,192 # 仍然 >> 298,没问题实际上训练时很少遇到 memory-bound 的矩阵乘法。问题更多出在:
- Tensor Parallelism 引入的芯片间通信
- Pipeline Parallelism 的 bubble
- Gradient AllReduce 的通信开销
2.5 网络通信的 Roofline
前面讨论的都是芯片内的 memory-bandwidth roofline。但在分布式训练/推理中,更重要的往往是芯片间的 network-bandwidth roofline。
例子:2-chip 分片矩阵乘法
将 $X[B, D] \times Y[D, F]$ 沿 D 维度切成 2 份,分别在 2 个 TPU 上计算:
Step 1:每个 TPU 计算一半
- TPU 0:$A = X[:, :D/2] \times Y[:D/2, :]$
- TPU 1:$B = X[:, D/2:] \times Y[D/2:, :]$
Step 2:交换部分和(partial sums),相加得到最终结果 $Z = A + B$
计算时间(每个 TPU 做一半的工作):
\[T_{\text{math}} = \frac{2BDF}{2 \times \text{FLOPs/s}} = \frac{BDF}{1.97 \times 10^{14}}\]通信时间(需要发送 partial sum $Z \in \text{bf16}[B, F]$):
\[T_{\text{comms}} = \frac{2BF}{\text{Network BW}} = \frac{2BF}{4.5 \times 10^{10}}\]Compute-bound 条件:
\[T_{\text{math}} > T_{\text{comms}} \iff \frac{BDF}{1.97e14} > \frac{2BF}{4.5e10}\] \[\iff \frac{D}{2} > \frac{1.97 \times 10^{14}}{4.5 \times 10^{10}} = 4377\] \[\iff D > 8755\]关键观察:在网络通信 roofline 中,决定是否 compute-bound 的是模型维度 D,而不是 batch size B!
为什么?因为 B 同时出现在分子和分母中被约掉了。直觉上:增加 batch size 同时增加了计算量和通信量(更大的 partial sum 需要传输),所以 B 不影响平衡点。而增加 D 只增加计算量(每个 TPU 做更多乘加),不增加通信量(partial sum 的大小只取决于 B×F)。
🛠️ 实践:Megatron-LM 的 Tensor Parallelism 设计
这个分析直接解释了 Megatron 中 TP 的核心设计原则:
为什么 TP 通常限制在单节点内(TP ≤ 8)?
- 节点内 NVLink 带宽:~450 GB/s → 临界 D ≈ 1e15 / 4.5e11 ≈ 2222
- 节点间 InfiniBand 带宽:~50 GB/s → 临界 D ≈ 1e15 / 5e10 ≈ 20000
对于 hidden_size = 8192 的模型:
- 节点内 TP:D/2 = 4096 > 2222 → compute-bound ✓
- 跨节点 TP:D/2 = 4096 < 20000 → communication-bound ✗
所以 Megatron 的策略是:
- TP 放在节点内(利用 NVLink 高带宽)
- DP/PP 放在节点间(通信量相对较小)
对于更小的模型(如 hidden_size = 4096):
- 即使节点内 TP=8,D/TP = 512,可能已经 communication-bound
- 此时应该减少 TP degree,增加 DP
通用网络 Roofline 公式
对于 N 个芯片的分片矩阵乘法,网络算术强度为:
\[\text{Network AI} = \frac{\text{每芯片 FLOPs}}{\text{每芯片通信 Bytes}}\]Compute-bound 条件:
\[\text{Network AI} > \frac{\text{每芯片 FLOPs/s}}{\text{网络带宽 Bytes/s}}\]2.6 低精度计算的 Roofline 影响
量化(Quantization)同时改变了 FLOPs/s 和搬运字节数,对 roofline 有复杂的影响。
纯 int8 矩阵乘法
使用 int8 代替 bf16:
- 每个参数 1 byte(而非 2 bytes)→ 加载字节数减半
- int8 OPs/s 通常是 bf16 的 2 倍(TPU v5e:
3.94×10¹⁴vs1.97×10¹⁴)
临界 AI = 3.94e14 / 8.2e11 = 480
由于字节数减半,AI 变为 $2B$(而非 $B$),所以临界 batch size = 480/2 = 240。
结论:int8 的临界 batch size 和 bf16 几乎一样!但绝对速度提升约 2×。
混合精度:int8 权重 + bf16 激活
实践中常见的配置:权重用 int8 存储,激活值保持 bf16,计算用 bf16 FLOPs:
bf16[B, D] × int8[D, F] → bf16[B, F]
- FLOPs:$2BDF$(bf16 速度:
1.97e14) - 加载字节:$2BD$(bf16 激活)+ $DF$(int8 权重)+ $2BF$(bf16 输出)
当 B 较小时:
\[\text{AI} \approx \frac{2BDF}{DF} = 2B\]Compute-bound 条件:$2B > 240$,即 $B > 120$。
这比纯 bf16 的临界 batch size(240)低了一半! 意味着混合精度量化在小 batch 场景下有额外优势——不仅减少了内存占用,还降低了 compute-bound 的门槛。
2.7 Worked Problems(习题与详解)
以下习题来自原书,附带完整解答和延伸讨论。建议先自己尝试,再看答案。
Problem 1:int8 矩阵乘法
题目:对于 matmul $X[B, D] \cdot_D Y[D, F] \rightarrow Z[B, F]$,使用 int8 精度(1 byte/参数)。假设 HBM 带宽 = 8.1×10¹¹ B/s,int8 峰值 = 3.94×10¹⁴ OPs/s。
- 需要从内存加载多少字节?写回多少字节?
- 总共执行多少 OPs?
- 算术强度是多少?
- 估算 $T_{\text{math}}$ 和 $T_{\text{comms}}$,给出运行时间的上下界。
点击查看答案
-
字节数:int8 每个参数 1 byte,所以加载 $BD + DF$ bytes,写回 $BF$ bytes。
-
OPs:和 bf16 一样是 $2BDF$(运算次数不变,只是每次运算更快)。
-
算术强度:
当 $B \ll D, F$ 时:$\text{AI} \approx 2B$。 临界条件:$2B > 3.94e14 / 8.1e11 = 486$,即 $B > 243$。 注意这和 bf16 的 $B > 240$ 几乎一样!
- 时间估算:
- $T_{\text{math}} = 2BDF / 3.94 \times 10^{14}$
- $T_{\text{comms}} = (BD + DF + BF) / 8.1 \times 10^{11}$
- 下界:$\max(T_{\text{math}}, T_{\text{comms}})$
- 上界:$T_{\text{math}} + T_{\text{comms}}$
延伸:虽然临界 batch size 没变,但 int8 的绝对速度是 bf16 的 ~2×。所以 int8 量化的主要收益是”同样 compute-bound 的情况下跑得更快”,而不是”让更小的 batch 变成 compute-bound”。
Problem 2:混合精度 int8 权重 + bf16 激活
题目:权重用 int8 存储,激活和计算用 bf16。即 bf16[B, D] × int8[D, F] → bf16[B, F]。在什么 batch size 下变成 compute-bound?假设 bf16 FLOPs/s = 1.97×10¹⁴。
点击查看答案
当 $B \ll D, F$ 时:
- FLOPs = $2BDF$(bf16 速率)
- 加载字节 ≈ $DF$(int8 权重占主导,因为 $B$ 小)
Compute-bound 条件:$2B > 240$,即 $B > 120$。
这比纯 bf16 的 B > 240 好了一倍! 直觉:权重字节数减半(int8),但 FLOPs 不变(仍用 bf16 计算),所以算术强度翻倍。
实践意义:这就是为什么 W8A16(int8 weight, bf16 activation)在推理中如此流行——它让更小的 batch 就能达到 compute-bound,同时精度损失很小。
Problem 3:画 Roofline 图
题目:基于 Problem 2 的设置(int8 权重 + bf16 激活),画出 peak FLOPs/s vs. batch size B 的图,分别取 $F = D = 4096$ 和 $F = D = 1024$。使用精确的字节数(不用近似)。
点击查看答案
import matplotlib.pyplot as plt
import numpy as np
bs = np.arange(1, 512)
def roofline(B, D, F):
total_flops = 2 * B * D * F
flops_time = total_flops / 1.97e14
# int8 weights (1 byte) + bf16 activations (2 bytes) + bf16 output (2 bytes)
comms_time = (2 * B * D + D * F + 2 * B * F) / 8.2e11
total_time = np.maximum(flops_time, comms_time)
return total_flops / total_time
roofline_big = roofline(bs, 4096, 4096)
roofline_small = roofline(bs, 1024, 1024)
plt.figure(figsize=(8, 4))
plt.plot(bs, roofline_big, label='F=D=4096')
plt.plot(bs, roofline_small, label='F=D=1024')
plt.axhline(y=1.97e14, color='r', linestyle='--', alpha=0.5, label='Peak bf16 FLOPs/s')
plt.legend()
plt.xlabel('Batch size B (tokens)')
plt.ylabel('Achievable bf16 FLOPs/s on TPU v5e')
plt.title('Roofline: int8 weights + bf16 activations')
plt.grid(True, alpha=0.3)
plt.show()
观察:
- 两种模型最终都达到峰值 FLOPs/s,但 D=F=4096 更快达到(临界 B 更小)
- D=F=1024 的临界 batch size 几乎翻倍——因为当 D 不够大时,$BD$ 项在分母中不可忽略
- 这解释了为什么小模型需要更大的 batch size 才能高效利用硬件
精确计算(D=F=4096, B=120):
- FLOPs = 2 × 120 × 4096 × 4096 = 4.03×10⁹
- Bytes = 2×120×4096 + 4096×4096 + 2×120×4096 = 983,040 + 16,777,216 + 983,040 = 18,743,296
- AI = 4.03e9 / 1.87e7 = 215(< 240,还是 memory-bound)
- 精确临界 B ≈ 135(比近似的 120 稍大,因为 BD 项不完全可忽略)
Problem 4:Batched 矩阵乘法
题目:如果我们对每个 batch 元素使用不同的权重矩阵,即 int8[B, D] × int8[B, D, F] → int8[B, F](每个 batch 有独立的 D×F 权重)。算术强度是多少?
点击查看答案
分析:
- FLOPs:仍然是 $2BDF$(B 个独立的 $[D] \times [D, F]$ matmul)
- 加载字节:$BD + BDF + BF$(注意权重现在是 $[B, D, F]$,大了 B 倍!)
- 算术强度:
由于 $BDF$ 在分母中占主导:
\[\text{AI} \approx \frac{2BDF}{BDF} = 2\]算术强度是常数 2! 这意味着无论 batch size 多大,这个操作永远是 memory-bound。
直觉:普通 matmul 的高效来自于权重复用——同一个 $[D, F]$ 权重被 B 个 batch 元素共享。但 batched matmul 中每个 batch 有独立权重,没有复用,所以算术强度退化为常数。
实践意义:这就是为什么 Mixture of Experts (MoE) 中的 expert 计算效率较低——每个 expert 有独立权重,且分配到每个 expert 的 token 数量不均匀(有些 expert 只分到很少的 token),导致有效 batch size 很小。
Problem 5:GPU H100 的 Memory Roofline
题目:使用 NVIDIA H100 SXM 规格,计算 bf16 matmul 变成 compute-bound 的临界 batch size。注意:NVIDIA 标称的 Tensor Core FLOPs 包含了 structured sparsity(2:4 稀疏),实际密集计算需要除以 2。
点击查看答案
从 H100 规格表:
- 标称 bf16 Tensor Core:
1.979×10¹⁵FLOPs/s(带 sparsity) - 实际密集 bf16:
1.979e15 / 2 ≈ 9.9×10¹⁴FLOPs/s - HBM 带宽:
3.35×10¹²bytes/s
临界 batch size:
\[B_{\text{crit}} = \frac{9.9 \times 10^{14}}{3.35 \times 10^{12}} \approx 296\]结论:H100 的临界 batch size(~296)和 TPU v5e(~240)在同一量级。这不是巧合——硬件设计者会平衡计算能力和带宽,使得典型 workload 处于 roofline 的拐点附近。
延伸:不同 GPU 的对比
| GPU | 密集 bf16 FLOPs/s | HBM BW | 临界 B |
|---|---|---|---|
| A100 | 3.12×10¹⁴ | 2.0×10¹² | ~156 |
| H100 | 9.9×10¹⁴ | 3.35×10¹² | ~296 |
| B200 | ~2.25×10¹⁵ | 8.0×10¹² | ~281 |
注意 B200 的临界 B 反而比 H100 略低——因为 B200 的 HBM 带宽增长比例(2.4×)超过了 FLOPs 增长比例(2.3×),带宽相对更充裕。
Problem 6:Flash Attention 的算术强度
题目:标准 Attention 计算 $O = \text{softmax}(QK^T / \sqrt{d}) V$,其中 $Q, K, V \in \text{bf16}[B, N, d]$(B=batch, N=seq_len, d=head_dim)。忽略 softmax 的 FLOPs(远小于 matmul)。
- 标准 Attention 的总 FLOPs 和总 HBM 访问字节数是多少?算术强度?
- Flash Attention(SMEM tile size $M$)的 HBM 访问字节数是多少?算术强度?
- 在 H100 上(HBM 3.35 TB/s, 990 TFLOPs/s),标准 Attention 在什么 N 下变成 memory-bound?
点击查看答案
1. 标准 Attention:
FLOPs(两个 matmul):
- $QK^T$:$2BN^2d$ FLOPs
- $\text{attn} \times V$:$2BN^2d$ FLOPs
- 总计:$4BN^2d$
HBM 访问:
- 读 Q, K, V:$3 \times 2BNd = 6BNd$ bytes
- 写 $S = QK^T$($N \times N$ per batch/head):$2BN^2$ bytes
- 读 S(softmax):$2BN^2$ bytes
- 写 P(softmax 结果):$2BN^2$ bytes
- 读 P:$2BN^2$ bytes
- 写 O:$2BNd$ bytes
- 总计:$\approx 8BN^2 + 8BNd$ bytes
算术强度:
\[\text{AI} = \frac{4BN^2d}{8BN^2 + 8BNd} = \frac{4N^2d}{8N^2 + 8Nd} = \frac{Nd}{2N + 2d} \approx \frac{d}{2} \quad (N \gg d)\]当 $N \gg d$ 时,AI ≈ $d/2 = 64$(对于 $d=128$)。
2. Flash Attention:
Flash Attention 在 SMEM 中分块计算,不写出完整的 $S$ 和 $P$ 矩阵。
HBM 访问:
- 读 Q:$2BNd$ bytes(分块读取,每块只读一次)
- 读 K, V:每个 Q 块要遍历所有 K/V 块 → $\lceil N/B_c \rceil$ 次全量读取 → $2 \times 2BNd \times \lceil N/B_c \rceil / (N/B_c) = 4BNd$
- 更精确:$O(BN^2d^2 / M)$,其中 $M$ = SMEM 大小
- 写 O:$2BNd$ bytes
- 总计:$\approx O(BN^2d / \sqrt{M})$(对于典型 tile size)
简化近似($B_r = B_c = \sqrt{M/d}$):
\[\text{HBM 访问} \approx \frac{4BN^2d^2}{M}\]算术强度:
\[\text{AI(Flash)} = \frac{4BN^2d}{4BN^2d^2/M} = \frac{M}{d}\]对于 H100 SMEM = 228 KB = 228,000 bytes, $d = 128$:
\[\text{AI(Flash)} \approx \frac{228000}{128} \approx 1781\]远大于 H100 临界 AI(296)!Flash Attention 几乎总是 compute-bound。
3. 标准 Attention 的临界 N:
标准 Attention 的 AI ≈ $d/2 = 64$(当 $N \gg d$),始终 < 296。
但当 $N$ 很小时,AI ≈ $Nd/(2N+2d)$。令 AI = 296:
\[\frac{Nd}{2N + 2d} = 296 \implies N = \frac{296 \times 2d}{d - 2 \times 296} = \frac{592 \times 128}{128 - 592} < 0\]标准 Attention 永远是 memory-bound(因为 $d < 2 \times 296$)!这就是 Flash Attention 存在的根本原因。
2.8 MFU 与 Roofline 的实践测量
MFU 的精确定义
Model FLOPs Utilization 衡量硬件利用效率:
\[\text{MFU} = \frac{\text{实际模型 FLOPs/s}}{\text{硬件峰值 FLOPs/s}}\]注意这里的”模型 FLOPs”是理论最小 FLOPs(不包括重计算),而分母是硬件理论峰值。
MFU 的各级损耗
100% ← 硬件峰值
│
│ ─── Memory-bound 操作(LayerNorm, Softmax, Embedding)
│ 损失 ~5-10%
│
~90% ← 如果所有 matmul 都 compute-bound
│
│ ─── 通信开销(AllReduce, AllGather)
│ 损失 ~10-20%
│
~70-80% ← 单步训练的效率
│
│ ─── Pipeline Bubble
│ 损失 ~5-15%
│
~55-70% ← 典型大模型训练 MFU
│
│ ─── Gradient Accumulation 步骤开销
│ 损失 ~5%
│
~50-65% ← 端到端 MFU(含 optimizer step)
🛠️ 实践:Megatron-LM 的 MFU 测量
Megatron-LM 提供了内置的 MFU 计算:
# Megatron-LM 中的 MFU 计算逻辑(简化) def compute_mfu(model_params, batch_size, seq_len, time_per_step, num_gpus): """ 计算 Model FLOPs Utilization 基于公式: 6 * N * B * S (forward + backward 的 FLOPs) 其中 factor 6 = 2(matmul) * 3(fwd + bwd_data + bwd_weight) """ # 模型 FLOPs (不含重计算) model_flops = 6 * model_params * batch_size * seq_len # 加上 Attention 的 FLOPs: 12 * L * s^2 * h # (对于长序列这项不可忽略) attn_flops = 12 * num_layers * seq_len**2 * hidden_size total_flops = model_flops + attn_flops # 硬件峰值 hw_peak = num_gpus * 990e12 # H100 bf16 dense FLOPs/s # MFU achieved_flops_per_sec = total_flops / time_per_step mfu = achieved_flops_per_sec / hw_peak return mfu # 例:LLaMA 70B, 512 GPUs, GBS=2048, seq=4096 # model_flops = 6 * 70e9 * 2048 * 4096 = 3.5e18 # time_per_step ≈ 7s (实测) # achieved = 3.5e18 / 7 = 5e17 FLOPs/s # hw_peak = 512 * 990e12 = 5.07e17 FLOPs/s # MFU ≈ 5e17 / 5.07e17 ≈ 49%(典型值)MFU 诊断决策树:
- MFU < 30%:检查是否 batch size 太小 → memory-bound 的 matmul
- MFU 30-40%:检查通信开销 → TP/DP AllReduce 可能太慢
- MFU 40-50%:正常范围,检查 pipeline bubble
- MFU > 50%:优秀,接近最优
多层级 Roofline 对比
同一个操作在不同带宽层级下有不同的 Roofline:
| 场景 | 带宽 | 临界 AI (H100) | 典型 compute-bound 条件 |
|---|---|---|---|
| HBM → Compute | 3.35 TB/s | 296 | matmul B > 296 |
| SMEM → Compute | ~30 TB/s | ~33 | matmul B > 33 |
| NVLink(节点内) | 450 GB/s | 2200 | TP: D/2 > 2200 |
| InfiniBand(节点间) | 50 GB/s | 19800 | DP: batch > 19800 |
关键洞察:同一个操作可能在 HBM 层面是 compute-bound,但在 network 层面是 communication-bound。分布式训练的瓶颈通常不在单芯片的 HBM roofline,而在跨芯片的 network roofline。
2.9 SGLang 视角:推理中的 Roofline
🛠️ 实践:SGLang 中的 Roofline 分析
在 SGLang(以及 mini-sglang)的推理引擎中,roofline 分析直接指导了调度策略:
Prefill 阶段(处理整个 prompt):
- 一次处理所有 prompt tokens,B = prompt_length(通常 > 240)
- Compute-bound → 关注 FLOPs/s 利用率
- SGLang 的
scheduler.py会尽量将多个短 prompt 合并成一个大 batchDecode 阶段(逐 token 生成):
- 每次只处理 1 个新 token per request
- 即使 batch 了 N 个 request,有效 B = N(通常 < 240)
- Memory-bound → 关注带宽利用率
- SGLang 通过 continuous batching 尽量增大 N
Roofline 指导的调度决策:
# 简化的调度逻辑(参考 SGLang scheduler) if pending_prefills and can_batch_prefill(): # Prefill 是 compute-bound,尽量大 batch batch = merge_prefill_requests(max_tokens=8192) else: # Decode 是 memory-bound,尽量多 request batch = collect_decode_requests(max_batch=256)这就是为什么 SGLang 的 continuous batching 对推理吞吐如此重要——它通过增大有效 batch size 来缓解 decode 阶段的 memory-bound 问题。
🛠️ 实践:mini-sglang 中验证 Roofline 预测
在 mini-sglang 项目中,我们可以实测验证 roofline 理论:
import torch import time def measure_matmul_throughput(B, D, F, dtype=torch.bfloat16, device='cuda'): """测量 matmul 的实际 FLOPs/s,验证 roofline 预测""" X = torch.randn(B, D, dtype=dtype, device=device) W = torch.randn(D, F, dtype=dtype, device=device) # Warmup for _ in range(10): _ = X @ W torch.cuda.synchronize() # Measure start = time.perf_counter() N_ITERS = 100 for _ in range(N_ITERS): _ = X @ W torch.cuda.synchronize() elapsed = time.perf_counter() - start flops = 2 * B * D * F * N_ITERS achieved_tflops = flops / elapsed / 1e12 # 理论预测 HBM_BW = 3.35e12 # H100 PEAK_FLOPS = 990e12 ai = B * D * F / (B * D + D * F + B * F) critical_ai = PEAK_FLOPS / HBM_BW predicted_bound = "compute" if ai > critical_ai else "memory" predicted_tflops = min(PEAK_FLOPS, ai * HBM_BW) / 1e12 print(f"B={B:6d} | AI={ai:.1f} | {predicted_bound:7s}-bound | " f"Predicted: {predicted_tflops:.0f} TF/s | " f"Achieved: {achieved_tflops:.0f} TF/s | " f"Efficiency: {achieved_tflops/predicted_tflops*100:.0f}%") # 验证不同 batch size 下的 roofline 转变 D = F = 8192 # LLaMA 7B hidden size for B in [1, 8, 32, 128, 256, 512, 1024, 4096]: measure_matmul_throughput(B, D, F) # 预期输出: # B= 1 | AI=1.0 | memory -bound | Predicted: 3 TF/s | Achieved: 2 TF/s # B= 128 | AI=127.5 | memory -bound | Predicted: 427 TF/s | Achieved: 380 TF/s # B= 512 | AI=504.0 | compute-bound | Predicted: 990 TF/s | Achieved: 820 TF/s # B= 4096 | AI=3641 | compute-bound | Predicted: 990 TF/s | Achieved: 850 TF/s观察:
- B < 300 时确实 memory-bound(FLOPs/s 随 B 线性增长)
- B > 300 时 compute-bound(FLOPs/s 趋于平坦)
- 实际效率约 85%(因为 kernel launch overhead、tiling 损耗等)
关键要点
- Roofline 模型:$T = \max(T_{\text{math}}, T_{\text{comms}})$(下界)到 $T_{\text{math}} + T_{\text{comms}}$(上界)
- 算术强度 = FLOPs / Bytes,与硬件临界 AI 比较判断 bound 类型
- bf16 Matmul 的 AI ≈ B(token batch size),临界 B ≈ 240(TPU v5e)/ 298(H100)
- 向量操作(LayerNorm、ReLU)AI ≈ 0.5,永远 memory-bound
- 网络 roofline 中,模型维度 D 决定 TP 是否划算(而非 batch size B)
- int8 量化不改变临界 B,但绝对速度 ~2×;W8A16 混合精度将临界 B 减半
- Batched matmul(独立权重)AI ≈ 2,永远 memory-bound(MoE 的效率挑战)
- Tile size 影响实际 AI:更大的片上 SRAM → 更大的 tile → 更高的 AI
- 标准 Attention AI ≈ d/2 ≈ 64,永远 memory-bound;Flash Attention AI ≈ M/d,几乎总是 compute-bound
- MFU 典型值:训练 40-55%,损耗来自通信 + pipeline bubble + memory-bound 操作
- 推理 decode 阶段天然 memory-bound(B=并发请求数),需要 continuous batching 提高效率
- 同一操作在不同层级有不同 Roofline:HBM(~300)、SMEM(~33)、NVLink(~2200)、IB(~20000)
进一步阅读
- 原书 Chapter 1: All About Rooflines
- Original Roofline Paper (Williams et al., 2009)
- Roofline: An Insightful Visual Performance Model
- Flash Attention 论文 (Dao et al., 2022) — IO-Complexity 分析
- Making Deep Learning Go Brrrr (Horace He) — PyTorch 视角的 Roofline 教程
- Megatron-LM 论文中的 MFU 计算方法
- NVIDIA H100 Whitepaper — 理解 GPU 的 roofline 参数
- TPU v5e 文档 — TPU 的带宽和算力规格
- HuggingFace Ultra-Scale Playbook — GPU 并行策略与 MFU