本章目标:掌握现代 LLM 推理引擎的核心优化技术,理解它们各自解决什么问题,以及如何设计一个高效的推理系统。
对应原书:Chapter 7 (All About Transformer Inference) 下半部分
改写范围:承接原书 inference engine 设计部分,额外补入 vLLM/SGLang、PagedAttention、RadixAttention、量化和 speculative decoding 等现代 serving 实践。 优先级:⭐⭐⭐ 高 | 建议时间:Day 10-11, 约 4-5 小时(含习题)
11.1 推理的三大挑战
- 内存:模型权重 + KV cache 占满 HBM → 限制并发请求数
- 延迟:每个 token 都要加载全部权重 → 单请求延迟高
- 吞吐量:如何同时服务大量请求 → 利用 batching 提升硬件利用率
以下优化技术分别或同时解决这些问题。
Generation 阶段的分片约束
在 Ch10 中我们分析了 Prefill 和 Generation 的性能特性。这里我们深入讨论 Generation 阶段可以使用哪些分片策略。
关键约束——与训练完全不同:
-
FSDP 通常不适合优化单请求 decode latency:Generation 是 memory-bound(被 HBM 带宽限制),如果每步都通过 ICI 搬运权重,往往会把 HBM 瓶颈换成更慢的网络瓶颈。对单个模型副本来说,通常应该搬运较小的激活值,而不是频繁重组完整权重。
-
Data Parallelism 的含义变了:DP 复制参数到多个模型副本,适合扩展服务总吞吐和做请求隔离;但对单个请求的 decode 步时间没有帮助,因为每个副本仍然要从自己的 HBM 读取完整参数。
-
序列并行空间很小:Generation 每步只有 1 个新 token,沿新 token 维度没什么可切;长上下文主要体现在 KV cache 上,通常用 KV/head/batch 维度的 cache 分片来处理。
结论:如果目标是降低单个模型副本的 decode latency,核心手段通常是 Model Parallelism(Tensor Parallelism) 及其变体;如果目标是扩展服务吞吐,再在外层复制多个模型副本。
超越 ICI Bound 的 Model Parallelism
在训练中,当 TP degree 超过某个阈值时我们变成 communication-bound(因为 FLOPs 时间 < 通信时间)。但在 Generation 中情况不同:
如果我们已经是 memory-bound(HBM 加载时间 > FLOPs 时间),增加 model parallelism 可以持续改善延迟!
原因:更多芯片 = 更多 HBM 带宽 → 参数加载更快。只要 ICI 通信时间不超过 HBM 加载时间,增加 TP 就有收益。
\[T_{\text{HBM}} = \frac{2DF}{Y \cdot W_{\text{hbm}}} \quad\quad T_{\text{ICI}} = \frac{2BD}{W_{\text{ici}}}\]ICI 成为瓶颈的条件:
\[T_{\text{ICI}} > T_{\text{HBM}} \implies Y > \frac{F}{B \cdot \beta}\]其中 $\beta = W_{\text{hbm}} / W_{\text{ici}}$(HBM 和 ICI 的带宽比,TPU v5e 和 v6e 约为 8)。
例子:$F = 16384$,$B = 32$,$\beta = 8$:
\[Y_{\text{max}} = \frac{16384}{32 \times 8} = 64\]这意味着我们理论上可以做 64-way TP 而不受通信约束!远超训练时的 4-8 way 限制。
📋 背景知识:为什么训练和推理的 TP 限制不同
- 训练:compute-bound → TP 的 ICI 通信与 FLOPs 时间竞争 → 约 4-8 way
- 推理 Generation:memory-bound → TP 的 ICI 通信与 HBM 加载时间竞争 → 可以更大
直觉:推理时 FLOPs 时间很短(因为 batch 小),通信时间主要和 HBM 加载时间比较。只要通信比 HBM 快,TP 就有收益。
11.2 推理引擎设计模式
在讨论具体优化技术之前,我们先理解推理引擎的整体架构。根据 prefill 和 generation 的组织方式,有三种主要设计模式:
模式 1:Batched Prefill + Generate
最简单的实现:
1. 收集一批请求
2. 批量 prefill 所有 prompt
3. 批量 generate 直到所有请求完成
4. 回到步骤 1
缺点:
- TTFT 随 batch size 增长(必须等所有 prefill 完成)
- 短请求被长请求阻塞(”等最慢”问题)
- Prefill 需要 padding 到最长序列(浪费计算)
- Prefill 和 Generation 共享相同的分片策略(无法分别优化)
适用场景:单用户边缘设备、快速原型开发
模式 2:Interleaved(交替式)
循环:
1. 如果有空闲 slot 且有等待的请求 → 执行一次 prefill(batch=1)
2. 执行一轮 generation(对所有活跃请求)
3. 移除已完成的请求
优点:
- TTFT 大幅改善(prefill 是 batch=1,不需要等其他请求)
- Generation 可以使用大 batch(高吞吐)
- 不需要 padding
缺点:
- Prefill 和 Generation 仍在同一硬件上 → 互相干扰
- 一个用户的 prefill 会暂停其他用户的 generation
模式 3:Disaggregated(分离式)
Prefill 服务器:
- 专门处理 prefill
- 产生 KV cache → 通过网络发送到 Generate 服务器
Generate 服务器:
- 专门处理 generation
- 接收 KV cache,加入 batch
- Continuous batching
优点:
- 用户的请求不会互相阻塞
- 可以独立优化和扩展 prefill/generation
- 可以为两者使用不同的分片策略
缺点:
- 需要网络传输 KV cache(额外延迟)
- 系统复杂度更高
适用场景:延迟敏感的高吞吐生产服务
11.3 Continuous Batching(连续批处理)

问题:静态 Batching 的浪费
传统做法:将多个请求组成一个 batch,等所有请求都生成完毕才释放。
请求 A:生成 10 个 token → 第 10 步完成
请求 B:生成 50 个 token → 第 50 步完成
请求 C:生成 20 个 token → 第 20 步完成
静态 batch:全部等到第 50 步才能接新请求
→ 请求 A 在第 10-50 步白白占着 GPU 资源
解决方案:Continuous Batching
- 每个 decode 步骤后检查:有请求完成了吗?有新请求到了吗?
- 完成的请求立即释放,新请求立即加入
- batch 大小在每步动态变化
效果:GPU 利用率大幅提升(2-10×),因为不再有”等最慢请求”的浪费。
实现核心:Orchestrator
Continuous batching 需要一个编排器(Orchestrator)来协调 prefill 和 generate:
class Orchestrator:
def __init__(self, max_batch_size, max_seq_len):
self.active_requests = {}
self.waiting_queue = []
self.max_batch_size = max_batch_size
def step(self):
# 1. 移除已完成的请求
for req_id in list(self.active_requests):
if self.active_requests[req_id].is_done():
self.active_requests.pop(req_id)
# 2. 填充空闲 slot
while (len(self.active_requests) < self.max_batch_size
and self.waiting_queue):
new_req = self.waiting_queue.pop(0)
kv_cache = self.engine.prefill(new_req.tokens)
self.active_requests[new_req.id] = ActiveRequest(new_req, kv_cache)
# 3. 执行一轮 generation
if self.active_requests:
batch = self.build_batch(self.active_requests)
tokens = self.engine.generate(batch)
self.update_requests(tokens)
📋 背景知识:为什么 Continuous Batching 在推理中至关重要
训练时 batch 中所有序列长度相同(通过 padding),不存在这个问题。 推理时每个请求的输出长度不同(有的回答 3 个字,有的写 2000 字),静态 batch 的资源浪费极大。 Continuous Batching 是所有现代推理引擎(vLLM、SGLang、TensorRT-LLM)的标配。
🛠️ 实践:SGLang
SGLang 原生支持 continuous batching:
- 每个 decode step 自动检查并调度新请求
- 支持 chunked prefill:长 prompt 的 prefill 被分成多个 chunk,穿插在 decode step 之间
--chunked-prefill-size 8192 # 每次最多 prefill 8192 tokens- 好处:避免一个长 prompt(如 100K tokens)的 prefill 阻塞所有 decode 请求数秒
11.4 PagedAttention(分页注意力)
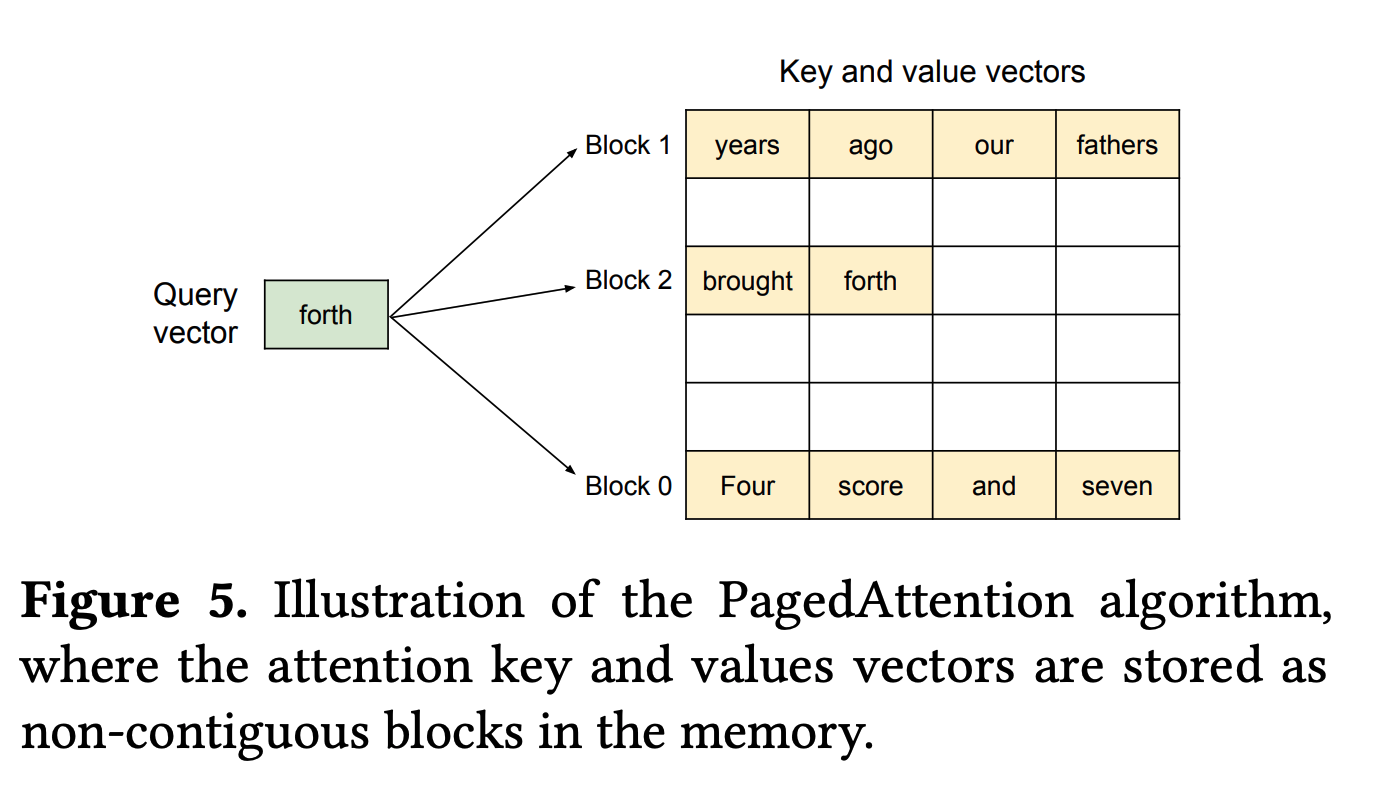
问题:KV Cache 内存碎片
传统 KV cache 为每个请求预分配固定大小的连续内存:
- 序列长度未知 → 必须按最大长度分配 → 大量浪费
- 请求结束后释放 → 内存碎片
解决方案:像操作系统管理虚拟内存一样管理 KV cache
PagedAttention(来自 vLLM):
- 将 KV cache 分成固定大小的”页”(如 16 tokens/页)
- 每个请求的 KV cache 不要求连续内存
- 使用”页表”映射逻辑位置到物理位置
- 按需分配,用完就释放
效果:
- 内存利用率从 ~40% 提升到 ~95%
- 相同 HBM 下可以支持 2-3× 的并发请求
🛠️ 实践:SGLang
SGLang 使用自己的高效内存管理(类似 PagedAttention 的思路):
- 基于 token-level 的内存分配
- 配合 RadixAttention 的前缀共享,共享 prefix 的 KV cache 只存一份
--mem-fraction-static参数控制为模型权重预留的 HBM 比例,剩余给 KV cache--mem-fraction-static 0.8 # 80% 给权重,20% 给 KV cache(默认会自动估算)
11.5 Prefix Caching(前缀缓存)
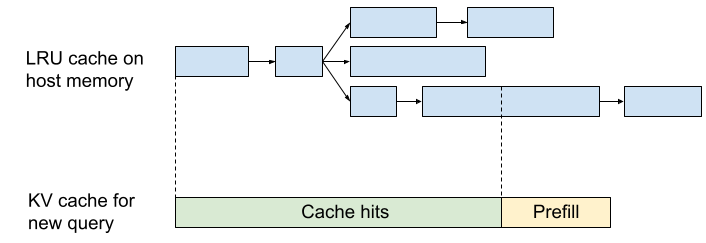
问题:重复 Prefill 相同的 System Prompt
很多应用场景中,大量请求共享相同的前缀:
- System prompt(如 “You are a helpful assistant…“)
- Few-shot examples
- 文档 context(RAG 场景)
每次重新 prefill 这些共享前缀 → 浪费计算和时间。
解决方案:缓存共享前缀的 KV cache
SGLang 的 RadixAttention:
- 将所有请求的 token 序列组织为 Radix Tree(基数树)
- 相同前缀的 KV cache 自动共享
- 新请求到来时,先查找树中最长匹配前缀 → 只 prefill 未匹配的部分
效果:
- 对共享前缀的场景,TTFT 大幅降低
- 内存节省(共享前缀的 KV cache 只存一份)
🛠️ 实践:SGLang
RadixAttention 是 SGLang 默认启用的,无需额外配置。
最大化 prefix caching 命中率的技巧:
- 将 system prompt 放在所有请求的最前面
- 使用
sgl.set_default_backend(...)设置后端时,prefix caching 自动生效- 在 multi-turn 对话中,历史消息自动成为共享前缀
- 监控:SGLang 的 metrics endpoint 会报告 cache hit rate
11.6 KV Cache 分片策略
在大规模推理中,KV cache 是一个需要特殊处理的数据结构。
Head 维度分片(Megatron 风格)
最简单的方法:沿 KV heads 维度分片。
\[\text{KV}[2, B, S, K, H] \rightarrow \text{KV}[2, B, S, K_Y, H]\]其中 $K_Y$ 表示每个芯片分到 $K/Y$ 个 KV heads。
限制:最大分片度 = KV heads 数量。对于 GQA(如 LLaMA 3 只有 8 个 KV heads),最多只能 8-way 分片。
Batch 维度分片
当需要超过 $K$-way 分片时,沿 batch 维度分片:
\[\text{KV}[2, B_Z, S, K_Y, H]\]每个芯片持有所有 heads 但只持有 $B/Z$ 个序列的 KV cache。
代价:需要 2 个额外的 AllToAll 通信操作:
- 将 Q 激活从 model sharding 转换到 batch sharding(做 attention 前)
- 将 attention 输出从 batch sharding 转回 model sharding
完整的 Attention 分片算法
假设 $Y$ 为 model parallelism degree,$Z$ 为 batch parallelism degree:
1. X[B, D] = ...(上一层的激活,未分片)
2. K[B_Z, S, K_Y, H], V[B_Z, S, K_Y, H] = ...(已有 KV cache,batch 分片)
3. Q[B, N_YZ, H] = X[B, D] × W_Q[D, N_YZ, H]
4. Q[B_Z, N_Y, H] = AllToAll_Z→B(Q[B, N_YZ, H])
5. Q[B_Z, K_Y, M, H] = Reshape(Q[B_Z, N_Y, H]) // M = N/(K*Z)
6. scores[B_Z, S, K_Y, M] = Q × K^T
7. scores = Softmax(scores)
8. O[B_Z, K_Y, M, H] = scores × V
9. O[B, K_Y, M_Z, H] = AllToAll_Z→M(O[B_Z, K_Y, M, H])
10. O[B, N_YZ, H] = Reshape(O)
11. X[B, D] {U_YZ} = W_O × O
12. X[B, D] = AllReduce(X[B, D] {U_YZ})
通信分析:
- AllToAll 操作的数据量:
B × N × H / Y(激活值,较小) - 避免了移动 KV cache:
B × S × K × H(通常大得多)
核心原则:移动小的激活值,保持大的 KV cache 不动。
11.7 量化(Quantization)
原理
用更少的 bit 表示模型权重:
| 配置 | 每参数 bytes | 70B 模型大小 | 相对速度 | Roofline 影响 |
|---|---|---|---|---|
| bf16 权重 + bf16 计算 | 2 | 140 GB | 1× | 临界 B ≈ 240 |
| fp8 权重 + fp8 计算 | 1 | 70 GB | ~2× | 临界 B 近似不变 |
| int8 权重 + bf16 计算(W8A16) | 1 | 70 GB | ~2× | 临界 B ≈ 120 |
| int8 权重 + int8 计算(W8A8) | 1 | 70 GB | ~2× | 临界 B 近似不变 |
| int4 权重 + bf16 计算(W4A16) | 0.5 | 35 GB | ~3-4× | 临界 B ≈ 60 |
为什么量化能加速推理
Generation 是 memory-bound。加速的关键是减少从 HBM 加载的字节数:
- int4 比 bf16 少 4×字节 → HBM 加载时间减少 4×
- 加上低精度的 FLOPs/s 可能更高 → 双重加速
Roofline 分析
回顾 Ch2 的混合精度 Roofline 分析:
W4A16(int4 权重 + bf16 激活 + bf16 计算):
- 加载字节:$0.5 \times DF$(int4 权重)+ $2BD$(bf16 激活)
- FLOPs:$2BDF$(bf16 速率)
- 当 $B \ll D$ 时:AI ≈ $\frac{2BDF}{0.5DF} = 4B$
临界条件:$4B > 240 \implies B > 60$
这比纯 bf16 的 B > 240 好了 4 倍! int4 量化不仅减少了内存占用,还大幅降低了 compute-bound 的门槛。
量化方法对比
| 方法 | 类型 | 精度影响 | 适用场景 |
|---|---|---|---|
| RTN | 朴素 round-to-nearest | 较大 | 不推荐生产使用 |
| GPTQ | 校准集 + 逐层补偿 | 中等 | int4 权重量化 |
| AWQ | 保护显著权重通道 | 较小 | int4,优于 GPTQ |
| SmoothQuant | 激活-权重平衡 | 小 | int8 权重+激活 |
| FP8 | 硬件原生支持 | 极小 | H100/B200 首选 |
代价:精度损失,可能影响模型质量。现代量化方法(GPTQ、AWQ、SmoothQuant)通过校准集最小化精度损失。
🛠️ 实践:SGLang
SGLang 支持多种量化方案:
# FP8 量化推理 python -m sglang.launch_server \ --model-path meta-llama/Llama-3-70B \ --quantization fp8 \ --tp-size 8 # AWQ 量化模型 python -m sglang.launch_server \ --model-path TheBloke/Llama-3-70B-AWQ \ --quantization awq \ --tp-size 4 # int4 模型更小,可能只需要 4 卡量化选择建议:
- FP8:精度损失最小,需要 H100/B200 硬件支持
- INT8 (SmoothQuant):通用性好,大部分硬件支持
- INT4 (AWQ/GPTQ):最大压缩比,适合资源受限场景
11.8 Speculative Decoding(投机解码)
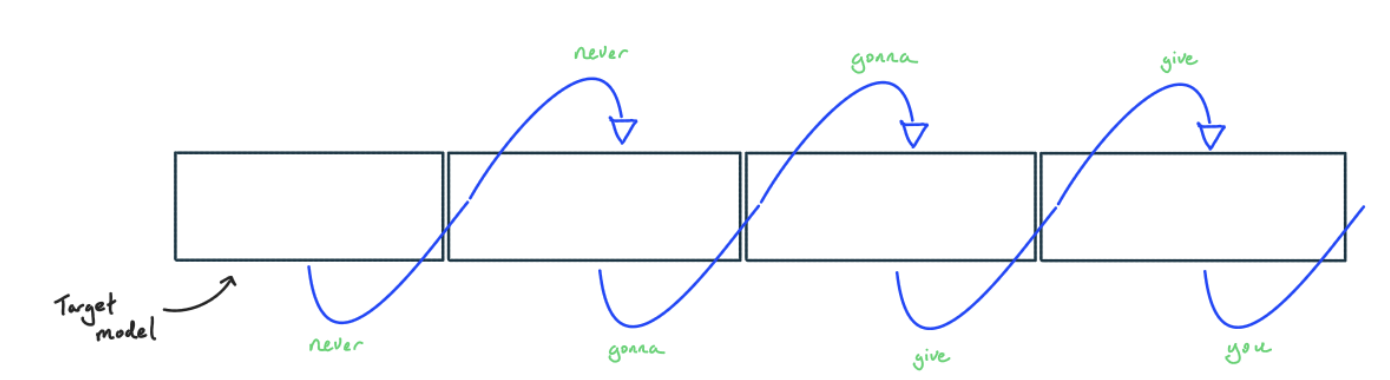
问题
Generation 每步只生成 1 个 token,但要加载全部权重 → memory-bound。硬件的 FLOPs 大量闲置。
核心思想
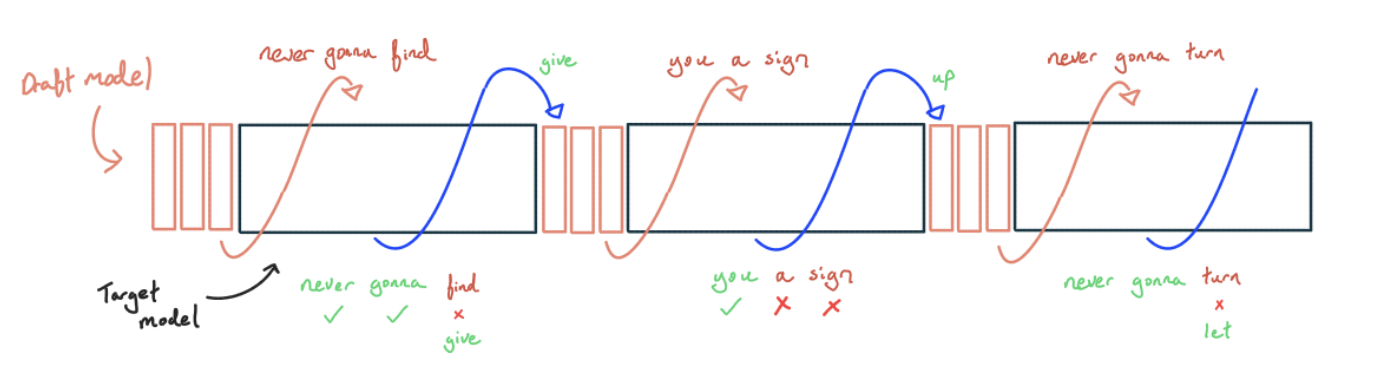
- 用一个小模型(draft model) 快速生成 k 个候选 token
- 用大模型一次性验证这 k 个 token(相当于 prefill,compute-bound)
- 接受所有正确的 token,从第一个错误处截断
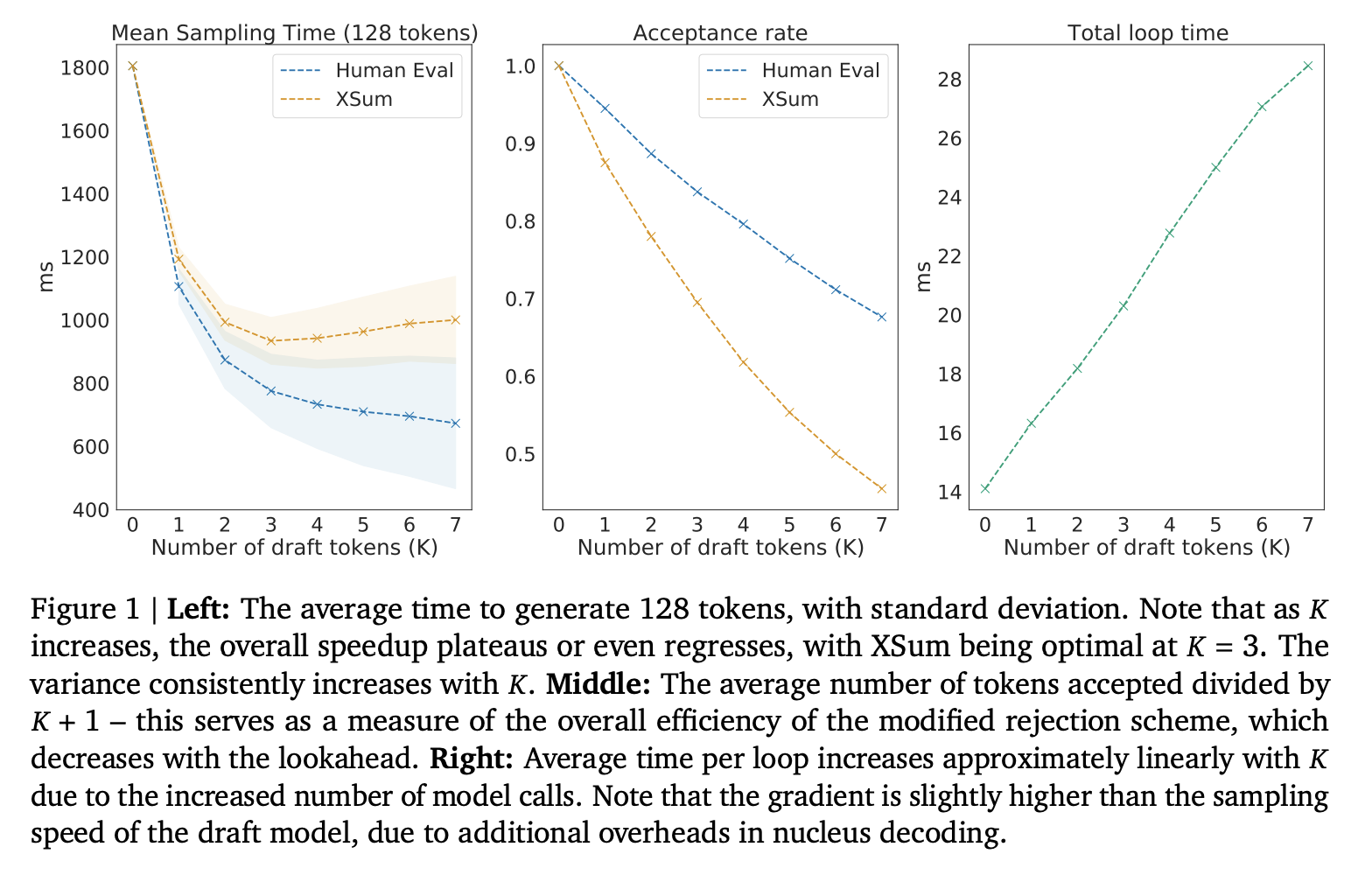
为什么这是延迟优势
正常 generation:每个 token 需要一次完整的权重加载 → token/s = 1/step_time
Speculative decoding:
- 小模型生成 k 个 token:很快(模型小,加载少)
- 大模型验证 k 个 token:一次前向传播,batch=k
由于验证时 batch=k > 1,我们利用了原本闲置的 FLOPs 来”免费”验证多个 token。每个被接受的 token 都相当于”赚到了”。
Greedy Decoding 的验证
对于 greedy decoding(选概率最高的 token),验证很简单:
def verify_greedy(draft_tokens, target_logits):
"""验证 draft model 的候选 token"""
accepted = []
for i, draft_token in enumerate(draft_tokens):
target_token = target_logits[i].argmax()
if draft_token == target_token:
accepted.append(draft_token)
else:
# 在第一个错误处截断,替换为正确 token
accepted.append(target_token)
break
# 如果全部正确,用最后一个 logit 多采样一个 token(bonus)
if len(accepted) == len(draft_tokens):
bonus_token = target_logits[-1].argmax()
accepted.append(bonus_token)
return accepted
Non-Greedy Decoding(Stochastic Verification)
对于 sampling(temperature > 0),需要使用类似 Metropolis-Hastings 的概率验证:
\[\text{Accept probability} = \min\left(1, \frac{P_{\text{target}}(\text{token})}{P_{\text{draft}}(\text{token})}\right)\]def verify_stochastic(draft_tokens, target_probs, draft_probs):
"""概率验证:保证采样分布不变"""
accepted = []
for i, token in enumerate(draft_tokens):
p_target = target_probs[i][token]
p_draft = draft_probs[i][token]
# Metropolis-Hastings 接受概率
accept_prob = min(1.0, p_target / p_draft)
if random.random() < accept_prob:
accepted.append(token)
else:
# 从修正分布中重新采样
residual = torch.clamp(target_probs[i] - draft_probs[i], min=0)
residual = residual / residual.sum()
new_token = torch.multinomial(residual, 1)
accepted.append(new_token)
break
return accepted
关键性质:这个算法保证最终的采样分布与直接从大模型采样完全相同(数学上等价),只是得到不同的具体 trajectory。
Draft Model 的选择
| Draft Model 类型 | 优点 | 缺点 |
|---|---|---|
| 独立小模型(如 LLaMA-2B for 70B) | 通用 | 可能不存在、接受率低 |
| 蒸馏模型 | 接受率高 | 需要额外训练 |
| 嵌入式 draft head(EAGLE/Medusa) | 共享参数、高接受率 | 模型特定 |
| N-gram/查表 | 极快、无需 GPU | 接受率低 |
最佳实践:DeepSeek-V3 使用嵌入式 draft head(在倒数第 3 层加一个小 head),因为:
- 共享 99% 参数,几乎不增加模型大小
- 接受率高(因为浅层已经捕获了大量信息)
- 不需要额外的推理调用
效果
- 如果小模型猜对率高(如 70-80%),平均每步验证可接受 3-5 个 token
- 大模型的权重只加载一次就验证了多个 token → 有效算术强度提升
- 总体吞吐量提升 2-3×
- 长上下文额外收益:KV cache 加载也被共享,对长序列尤其有效
📋 背景知识:何时使用 Speculative Decoding
Speculative decoding 是一个延迟-吞吐量的权衡:
- 延迟优化:如果 batch size 受限(KV cache 太大),spec decoding 是纯收益
- 吞吐量权衡:大 batch 下,验证步骤的 FLOPs 增加可能抵消收益
最佳使用场景:
- 单用户/低并发(batch 小)
- 长上下文推理(KV cache 大,限制 batch)
- 模型输出可预测性高(代码生成、模板回复)
11.9 其他优化技术
FlashInfer / FlashDecoding
- 优化 decode 阶段的 attention kernel
- 传统 attention kernel 在 batch=1 时 GPU 利用率极低(一个 head 只占一个 SM)
- FlashDecoding 将 KV cache 分割成多块,利用多个 SM 并行处理
- 对长序列尤其重要:S=32K 时可以将 attention 分配到 32+ 个 SM
CUDA Graphs
- 将多个 GPU kernel 打包成一个”图”
- 消除 kernel launch 开销(每次 launch ~10μs,数百个 kernel 就是 ms 级别)
- 对小 batch 的 generation 特别重要(kernel 计算时间短,launch 开销占比高)
Kernel Fusion
- 将多个连续操作融合为一个 kernel(如 LayerNorm + Linear)
- 减少 HBM 读写次数(中间结果保留在 registers/shared memory)
- 对 memory-bound 操作效果显著
🛠️ 实践:SGLang
SGLang 内置了这些优化:
- FlashInfer:SGLang 默认使用 FlashInfer 的高效 attention kernel
- CUDA Graphs:SGLang 在 decode 阶段使用 CUDA Graphs 消除 launch 开销
--disable-cuda-graph # 调试时可禁用- Torch Compile:SGLang 支持用
--enable-torch-compile做 kernel fusion
11.10 Latency-Bound 通信(附录)
在推理的小 batch 场景下,通信不再受带宽限制,而是受延迟限制。
带宽 vs 延迟
集合通信(如 AllGather)的时间:
\[T_{\text{comms}} = \max\left(\frac{T_{\text{min}} \cdot |X|}{2}, \frac{B_{\text{bytes}}}{W_{\text{ICI}}}\right)\]其中:
- $T_{\text{min}}$:单跳延迟(约 1μs)
-
$ X $:芯片数量 - $B_{\text{bytes}}$:传输数据量
- $W_{\text{ICI}}$:ICI 带宽
当数据量很小时(推理中常见),第一项占主导 → 延迟受芯片数量限制,而非数据量。
何时变成 Latency-Bound
以 TPU v5e 为例,ICI 带宽 4.5×10¹⁰ B/s,单跳约 1μs:
\[\text{Latency-bound 条件}: \frac{\text{bytes}}{n_{\text{shards}} \times 4.5e10} < 1e-6\]即 buffer_size < 4.5×10¹⁰ × 1×10⁻⁶ = 45 KB/shard
对于 8-way Megatron TP:总 buffer < 360 KB。
实际推理中的数字:
- Batch=16, D=8192, int8:激活 =
16 × 8192 = 131 KB - 已经接近 latency-bound!
影响
- 在 latency-bound 区间,增加更多芯片反而会增加通信延迟(更多 hops)
- 对于非常小的 batch size,TP 的收益有上限
- 解决方案:使用更短的通信路径(如 2D mesh 而非 ring)
11.11 2D Weight Stationary 分片(附录)
对于大规模推理(64+ 芯片),传统的 1D Megatron TP(只分片 F 维度)变得低效。2D Weight Stationary 分片同时分片 D 和 F 维度。
算法
\[\text{Weights: } W_{\text{in}}[D_X, F_{YZ}], \quad W_{\text{out}}[F_{YZ}, D_X]\]1. In[B, D_X] = AllGather_YZ(In[B, D_XYZ])
2. Tmp[B, F_YZ] {U_X} = In[B, D_X] × W_in[D_X, F_YZ]
3. Tmp[B, F_YZ] = AllReduce_X(Tmp[B, F_YZ] {U_X})
4. Out[B, D_X] {U_YZ} = Tmp[B, F_YZ] × W_out[F_YZ, D_X]
5. Out[B, D_XYZ] = ReduceScatter_YZ(Out[B, D_X] {U_YZ})
通信量分析
\[T_{\text{2D comms}} = \frac{2BD}{X \cdot W_{\text{ici}}} + \frac{4BF}{YZ \cdot W_{\text{ici}}}\]假设 $F = 4D$(如 LLaMA),最优拓扑为 $X = \sqrt{N/8}$,$YZ = \sqrt{8N}$。
最优总通信:
\[T_{\text{2D comms}} = \frac{\sqrt{128} \cdot BD}{\sqrt{N} \cdot W_{\text{ici}}} \approx \frac{11.3 BD}{\sqrt{N} \cdot W_{\text{ici}}}\]何时优于 1D
1D Megatron 的通信:$T_{\text{1D}} = \frac{4BD}{3 \cdot W_{\text{ici}}}$
2D 更优的条件:
\[\frac{4BD}{3 \cdot W_{\text{ici}}} > \frac{11.3 BD}{\sqrt{N} \cdot W_{\text{ici}}} \implies N > 81\]当芯片数量超过约 81 个时,2D 分片开始优于 1D!
更重要的是:即使通信已经超过计算时间(communication-bound),2D 分片的通信量随 $\sqrt{N}$ 下降。这意味着可以持续增加芯片来降低延迟。
🛠️ 实践:ESTI 论文的应用
Google 的 ESTI 论文 首次提出了 2D weight stationary 分片:
- 用于 Chinchilla、PaLM 等模型的大规模推理
- TPU v4 的 2D torus 拓扑天然适合这种分片
- 核心洞察:权重保持不动(weight-stationary),只移动激活值
11.12 Worked Problems(习题与详解)
Problem 1:推理引擎设计选择
题目:你需要部署一个聊天服务,预期并发 200 个用户,平均 TTFT 要求 < 500ms,ITL 要求 < 50ms。模型是 LLaMA 3-70B(TP=8 on H100)。
应该选择哪种引擎设计模式?为什么?
点击查看答案
分析:
- 200 并发 → batch size 可能 200(很大)
- TTFT < 500ms → prefill 延迟要求严格
- ITL < 50ms → decode 延迟要求严格
Batched 模式:不行。200 个请求的 prefill 需要顺序处理,TTFT 可能是 200 × 50ms = 10s。
Interleaved 模式:勉强。Prefill batch=1 的 TTFT 约 200ms,满足要求。但每个 prefill 会暂停所有 200 个用户的 decode,造成 ITL 波动(每次 prefill 约 200ms 的抖动)。
Disaggregated 模式:最佳选择。
- Prefill 服务器:独立处理新请求,TTFT ≈ 200ms
- Decode 服务器:不受 prefill 干扰,ITL 稳定 ≈ 30ms
- 可以独立扩展 prefill/decode 容量
结论:选择 Disaggregated Serving,这也是实际生产中的主流选择。
Problem 2:Speculative Decoding 收益计算
题目:一个 70B 模型在 H100 上的单步延迟为 40ms(batch=1)。Draft model 是 7B,单步延迟 4ms。假设 draft 步数 k=5,接受率 75%。
- 正常解码的吞吐量是多少?
- Speculative decoding 的平均吞吐量是多少?
- 最优 k 是多少?
点击查看答案
1. 正常解码:
- 每步 40ms,每步 1 token
- 吞吐量 = 1 / 0.040 = 25 tokens/s
2. Speculative decoding(k=5, 接受率 75%):
一个 speculation cycle 的时间:
- Draft 时间:5 × 4ms = 20ms
- Verify 时间:≈ 40ms(大模型前向,batch=5+1=6)
- 总时间:20 + 40 = 60ms
一个 cycle 平均接受的 token 数:
- 5 个 draft token,75% 接受率
- 期望接受长度 = $\frac{1-(0.75)^5}{1-0.75} = \frac{1-0.237}{0.25} = 3.05$
- 加上一个 bonus token(如果全部接受)或 correction token
- 实际约 3.05 + 0.237 = 3.3 tokens/cycle
吞吐量 = 3.3 / 0.060 = 55 tokens/s(提升 2.2×)
3. 最优 k:
增大 k:
- 收益:更多 token 可能被接受(但边际递减)
- 代价:draft 时间线性增长,verify 计算量增加
对于 75% 接受率,期望接受长度 = $\frac{1-0.75^k}{0.25}$:
- k=3:期望 2.3 tokens,时间 3×4+40=52ms → 44 tokens/s
- k=5:期望 3.3 tokens,时间 5×4+40=60ms → 55 tokens/s
- k=7:期望 3.7 tokens,时间 7×4+40=68ms → 54 tokens/s
- k=10:期望 3.9 tokens,时间 10×4+40=80ms → 49 tokens/s
最优 k ≈ 5(这与实践经验一致)。
Problem 3:量化的 Roofline 影响
题目:LLaMA 2-70B 在单张 H100 上推理。比较 bf16 和 int4 (AWQ) 的性能:
- 各自的理论最小 decode 延迟?
- 各自可以支持的最大 batch size?
- 在 batch=16 时,哪个方案的吞吐量更高?
点击查看答案
H100:HBM = 80GB,带宽 = 3.35 TB/s,bf16 FLOPs/s = 9.9×10¹⁴
1. 理论最小延迟(batch=1):
bf16(140 GB 参数):
\[T = 140e9 / 3.35e12 = 41.8 \text{ ms} \quad → 24 \text{ tokens/s}\]int4(35 GB 参数):
\[T = 35e9 / 3.35e12 = 10.4 \text{ ms} \quad → 96 \text{ tokens/s}\]int4 快 4×!
2. 最大 batch size(假设 KV cache/sequence = 1.34GB,S=4096):
bf16:(80 - 140) → 放不下! 需要至少 2 张卡。
如果用 TP=2(2×H100):
- 参数:140/2 = 70 GB/卡
- 剩余:(80-70) × 2 = 20 GB
- Max batch = 20 / 1.34 ≈ 14
int4(单卡):
- 参数:35 GB
- 剩余:80 - 35 = 45 GB
- Max batch = 45 / 1.34 ≈ 33
3. Batch=16 时:
bf16(TP=2):
- 加载:140e9 + 16 × 1.34e9 = 161.4 GB
- 时间:161.4e9 / (3.35e12 × 2) = 24.1 ms
- 吞吐量:16 / 0.0241 = 664 tokens/s
- 但还要加 TP 通信开销
int4(单卡):
- 加载:35e9 + 16 × 1.34e9 = 56.4 GB
- 时间:56.4e9 / 3.35e12 = 16.8 ms
- 吞吐量:16 / 0.0168 = 952 tokens/s
- 无通信开销
int4 单卡比 bf16 双卡还快! 且硬件成本仅一半。
Problem 4:KV Cache 分片
题目:一个模型有 8 个 KV heads,你需要在 32 个芯片上做 generation。如何分片 KV cache?
点击查看答案
约束:
- 只有 8 个 KV heads → 沿 head 维度最多分 8 份
- 需要 32 个芯片
方案:Head 分片 + Batch 分片
- Model parallelism Y = 8(沿 head 维度)
- Batch parallelism Z = 4(沿 batch 维度)
- 总芯片 = Y × Z = 32
每个芯片持有:
- 1 个 KV head
- 总 batch 的 1/4
通信开销:
- 每层需要 2 个 AllToAll:
- Q 从 model sharding → batch sharding
- Attention output 从 batch sharding → model sharding
- AllToAll 数据量:
B × N × H / Y(激活值)
替代方案:如果 batch 太小(< 4),可以改为 sequence 分片。
关键要点
- 单个模型副本的 Generation latency 主要靠 Model Parallelism 优化;外层 DP 仍可用于扩展服务吞吐
- Memory-bound 下可以超越训练的 ICI bound,更大的 TP 仍有收益
- 推理引擎三种模式:Batched、Interleaved、Disaggregated(生产推荐后者)
- Continuous Batching:动态增删请求,消除”等最慢”的浪费
- PagedAttention:分页管理 KV cache,内存利用率 40% → 95%
- Prefix Caching:共享前缀的 KV cache 复用(SGLang 的 RadixAttention)
- KV cache 分片:先 head 维度,不够再 batch 维度(需要 AllToAll)
- 量化:W8A16 / W4A16 同时降低权重加载量和 compute-bound 门槛;全低精度计算则通常让临界 batch 近似不变
- Speculative Decoding:利用闲置 FLOPs,最优 k ≈ 3-5,吞吐提升 2-3×
- Latency-bound 通信:小 batch 时通信受固定延迟限制,非带宽限制
- 2D Weight Stationary:81+ 芯片时优于 1D Megatron,通信随 √N 下降
- SGLang 内置 continuous batching + RadixAttention + FlashInfer + CUDA Graphs
进一步阅读
- 原书 Chapter 7: All About Transformer Inference(下半部分 + Appendix A-D)
- vLLM / PagedAttention 论文 (Kwon et al., 2023)
- SGLang / RadixAttention 论文 (Zheng et al., 2024)
- Speculative Decoding 论文 (Leviathan et al., 2023)
- Speculative Sampling 论文 (Chen et al., 2023)
- ESTI 论文 - 2D Weight Stationary
- EAGLE: Speculative Sampling with Embedded Drafter
- FlashDecoding
- JetStream 开源项目