本章目标:理解 LLM 推理的两个阶段(Prefill 和 Generation)为何性能特性完全不同,掌握推理中的核心瓶颈和关键指标。
对应原书:Chapter 7 (All About Transformer Inference) 上半部分
改写范围:本章只保留推理性能模型主线:prefill/generation、KV cache、batching 和分片直觉;具体 engine 技术放到第 11 章,LLaMA serving sizing 放到第 12 章。 优先级:⭐⭐⭐ 高 | 建议时间:Day 9-10, 约 3 小时
10.1 推理 vs 训练的本质区别
🔗 与你的联系
训练时,你处理的是大 batch、长序列,全部 token 同时参与计算 → 天然 compute-bound。 推理时,你一次只生成 1 个 token,但需要重复数百次 → 每次都在加载全部权重但只做极少计算 → 天然 memory-bound。
这是推理 Infra 和训练 Infra 的根本差异。
| 特性 | 训练 | 推理(Generation) |
|---|---|---|
| Batch size/device | 大(数千 tokens) | 小(1-数百 tokens) |
| 瓶颈 | Compute-bound | Memory-bound |
| 优化目标 | 吞吐量(tokens/s) | 延迟 + 吞吐量 |
| 内存主角 | 参数 + 优化器 + 激活 | 参数 + KV Cache |
推理到底要优化什么?
在深入分析之前,有必要明确推理的优化目标。与训练只关心吞吐量不同,推理引入了一个全新的维度:延迟(latency)。
不同的应用场景对延迟和吞吐量有截然不同的需求:
| 场景 | 优化目标 | 延迟要求 | 吞吐量要求 |
|---|---|---|---|
| 离线批量推理(评测/数据生成) | 成本最低化 | 不关心 | 高 |
| 聊天界面/流式服务 | 低延迟 + 大规模 | TTFT 低 + token 生成速度超过人类阅读速度 | 中-高 |
| 边缘推理(笔记本/手机) | 单用户最低延迟 | 极低 | 不关心 |
📋 背景知识:TTFT vs ITL
- TTFT(Time to First Token):从用户发送请求到看到第一个 token 的时间。主要由 prefill 决定。
- ITL(Inter-Token Latency):相邻两个 token 之间的间隔。主要由 generation 的单步时间决定。
对聊天场景,TTFT < 500ms 和 ITL < 50ms 通常是可接受的体验(人类阅读速度约 200-300 words/min,约 5-8 tokens/s)。
训练时,最大化硬件利用率(MFU)等同于最小化成本。推理时,高硬件利用率可以降低成本和 TTFT,但不一定改善单个用户的体验。很多优化在延迟、吞吐量、上下文长度和模型质量之间做权衡。
10.2 Autoregressive Generation 的流程
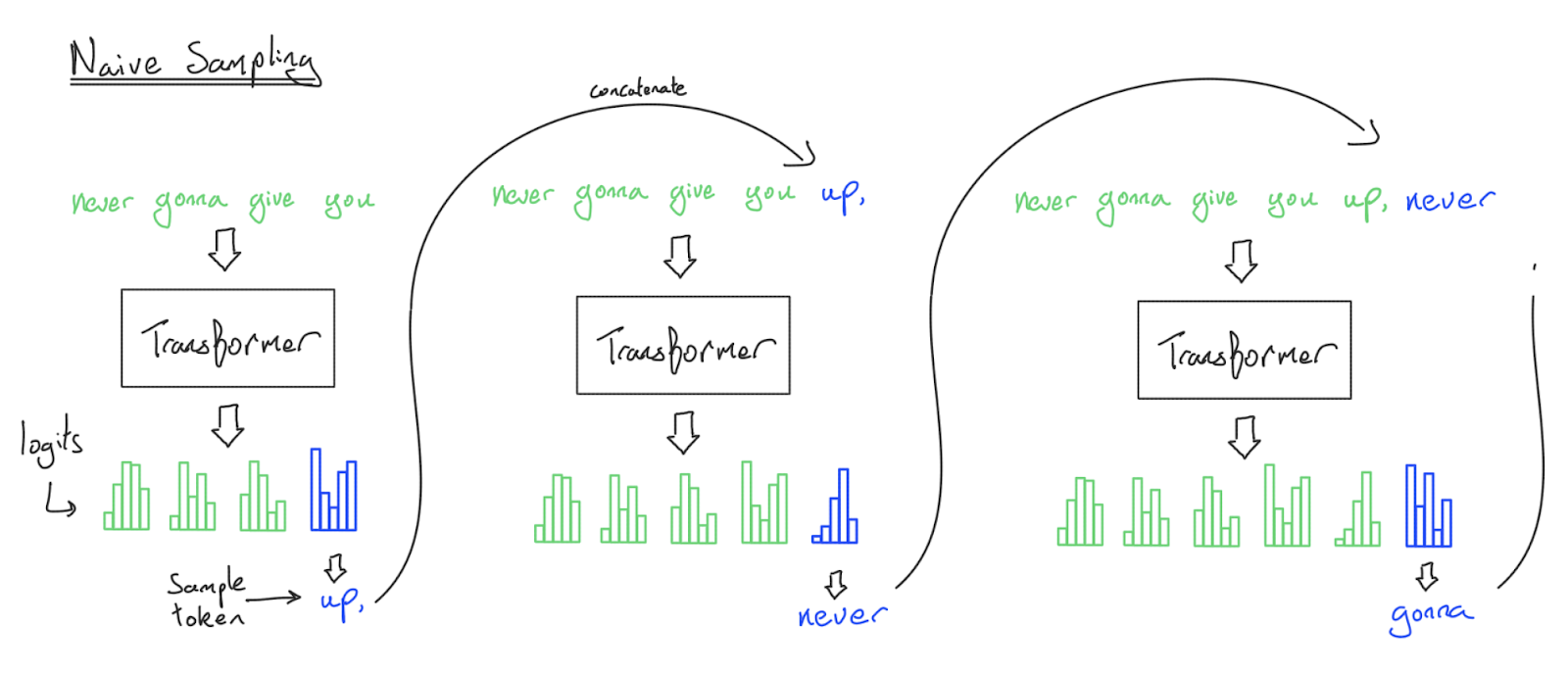
标准的自回归生成:
输入: [token₁, token₂, ..., tokenₙ](prompt)
输出: 逐个生成 token_{n+1}, token_{n+2}, ...
每步:
1. 输入当前 token(或全部历史)
2. 经过所有 Transformer 层
3. 得到 logits,采样下一个 token
4. 重复
问题:如果每步都重新计算所有历史 token 的 attention,复杂度是 O(n²)。
解决方案:KV Cache。
10.3 KV Cache
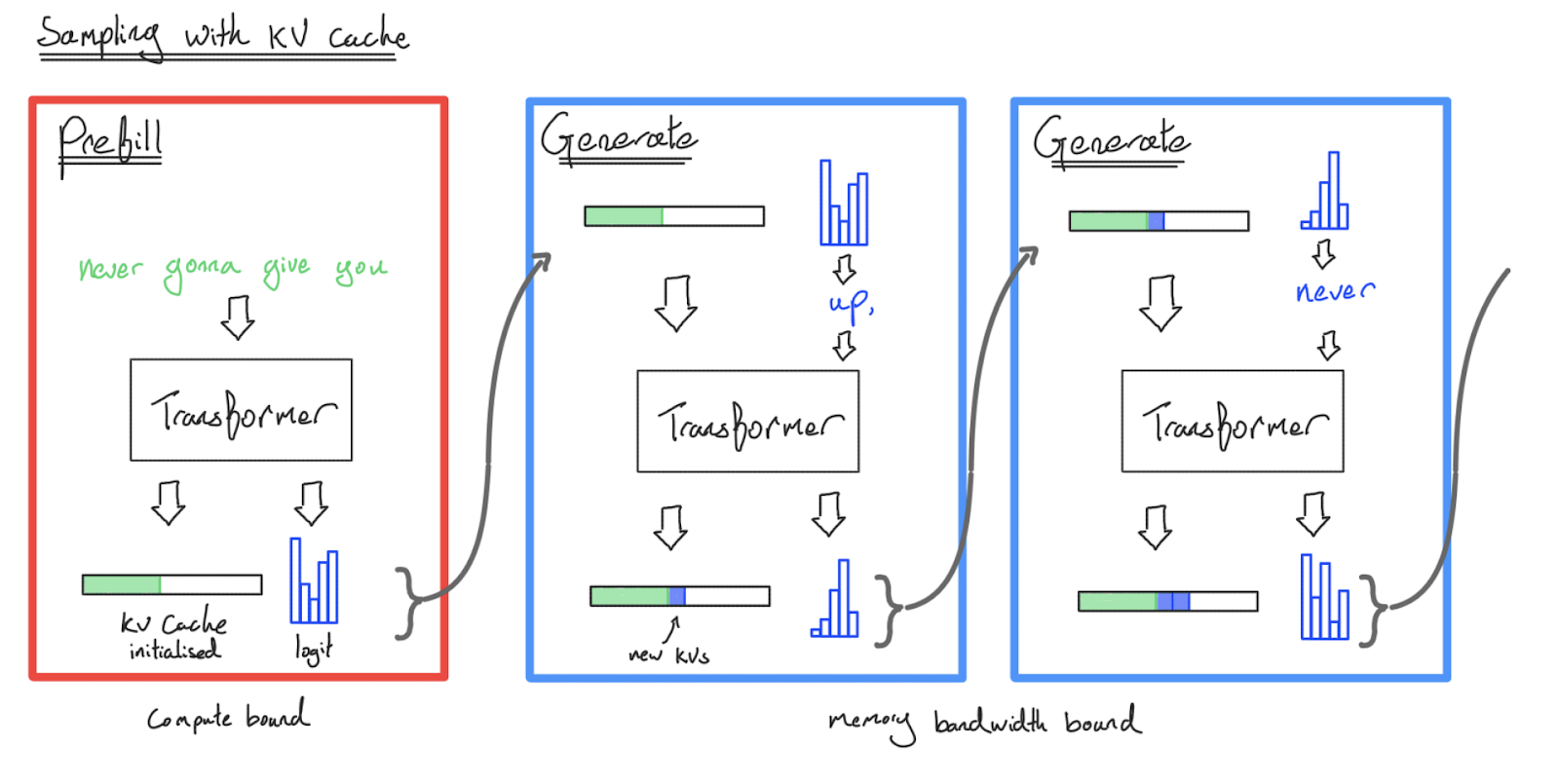
核心思想:Attention 层中,历史 token 的 K 和 V 向量不会变化。只需计算一次并缓存,后续步骤直接使用。
步骤1(Prefill):
- 一次性处理全部 prompt tokens
- 计算并缓存所有层的 K, V 矩阵
步骤2+(Generation/Decode):
- 每步只输入 1 个新 token
- 新 token 的 Q × 所有历史的 K → attention scores
- 将新 token 的 K, V 追加到 cache
KV Cache 大小(每序列):
\[\text{KV size} = 2 \times L \times \text{Kv\_heads} \times K \times S \times 2 \text{ (bf16)}\]LLaMA 70B,序列长度 4096:
2 × 80 × 8 × 128 × 4096 × 2 = 1.34 GB/序列
这很大!如果你想同时 serve 256 个并发请求:256 × 1.34 GB = 343 GB 仅 KV cache。
10.4 两个阶段的性能分析
Prefill 阶段
- 输入:完整 prompt(数百到数千 tokens)
- 计算模式:和训练前向传播几乎相同
- 性能特性:batch_tokens 大 → Compute-bound
- 关键指标:Time to First Token (TTFT)
其中 S 是 prompt 长度。
Generation(Decode)阶段
- 输入:每步只有 1 个新 token
- 计算模式:加载全部权重,但只对 1 个 token 做 matmul
- 性能特性:batch_tokens = 1 → 严重 Memory-bound
- 关键指标:Time Per Output Token (TPOT) 或 Inter-Token Latency (ITL)
(每步需要从 HBM 加载一次完整的模型权重)
📋 背景知识:为什么 Generation 是 Memory-bound
回顾 Roofline:matmul
X[B,D] × W[D,F]的算术强度 ≈ B。
- Prefill:B = prompt_length(数百-数千)→ 远大于临界值 240 → Compute-bound
- Generation:B = 1(单 token)→ 远小于 240 → Memory-bound
在 Generation 阶段,模型做的是
x[1, D] × W[D, F],加载了整个 W 但只做了 DF 次 FLOPs(而非训练时的 B×D×F 次)。绝大部分时间花在从 HBM 读取权重上。
量化对临界 Batch Size 的影响
上面推导的 $B_{\text{crit}} = 240$(TPU v5e)假设权重和激活都是 bf16。但实际推理中常使用量化,这会改变临界值。
回顾算术强度的推导:
\[\text{AI} \approx \frac{2BDF}{\text{bytes}(W) + \text{bytes}(X)} \approx \frac{2BDF}{\text{bits\_param}/8 \cdot DF}\]定义 $\beta = \text{bits per param} / \text{bits per activation}$,则:
\[B_{\text{crit}} = \beta \cdot \alpha_{\text{hbm}} = \beta \cdot \frac{C}{W_{\text{hbm}}}\]| 配置 | 权重精度 | 激活精度 | FLOPs 精度 | β | B_crit (TPU v5e) |
|---|---|---|---|---|---|
| bf16/bf16 | bf16 | bf16 | bf16 | 1 | 240 |
| int8 权重 + bf16 激活 | int8 | bf16 | bf16 | 0.5 | 120 |
| int8 权重 + int8 激活 | int8 | int8 | int8 | 1 | 240* |
| int4 权重 + bf16 激活 | int4 | bf16 | bf16 | 0.25 | 60 |
*注:int8×int8 在 TPU v5e 上提供 400 TOPs/s(是 bf16 的 2×),所以 α_hbm 加倍,B_crit 仍为 240。
关键洞察:
- int8 权重量化将 $B_{\text{crit}}$ 从 240 降到 120 → 更容易 compute-bound → 更少的请求就能打满硬件
- int4 权重量化将 $B_{\text{crit}}$ 降到 60 → 效果更显著
- 但如果 FLOPs 也用低精度(如 int8×int8),额外的算力会抵消收益
🛠️ 实践:Megatron-LM 的推理量化
Megatron-LM 支持在推理时使用量化:
# FP8 推理(需要 H100/B200) --fp8-format hybrid \ --fp8-amax-compute-algo max \ --use-te # 使用 Transformer EngineMegatron 的 FP8 推理利用 H100 的 FP8 Tensor Core,FLOPs/s 翻倍的同时权重字节减半。这意味着 $B_{\text{crit}}$ 不变(FLOPs 和带宽同时翻倍),但每步的绝对延迟减半。
10.5 Attention 的特殊性
在 Generation 阶段,Attention 也有不同的性能特性:
\[Q[1, D] \times K^T[D, S] \rightarrow \text{scores}[1, S]\]- 这是一个
[1, D] × [D, S]的 matmul,算术强度 ≈ 1 - 加载 K cache 的量 ∝ 序列长度 S
- 随着生成的 token 越来越多,Attention 的开销线性增长
这就是为什么长序列推理特别昂贵:KV cache 内存和 attention 计算时间都随 S 线性增长。
Attention 的 Roofline 分析
让我们详细分析 Attention 在 Generation 阶段的性能特性。对于单个 token 的 attention 计算:
Q × K^T 阶段(计算 attention scores):
- 输入:
Q[1, N, H](新 token 的 query)和K[S, N, H](历史 KV cache) - FLOPs:
2 × N × H × S(N 个 head,每个 head 做[1, H] × [H, S]的 matmul) - 加载字节数:
2NH + 2NHS(Q 和 K,bf16 格式) - 算术强度:
当 S 足够大时(通常 S » 1),分母中 2NHS 项占主导,算术强度趋近于 1 FLOPs/Byte。
Softmax 阶段:
- 对
[N, S]的 scores 做 softmax - FLOPs:约
5NS(exp、sum、div) - 加载/写回:
4NSbytes - 算术强度:约 1.25 FLOPs/Byte
Scores × V 阶段:
- 输入:
scores[1, N, S]和V[S, N, H] - FLOPs:
2 × N × S × H - 加载字节数:
2NS + 2NSH - 算术强度:约 1 FLOPs/Byte(当 H 不太大时)
结论:Attention 的所有阶段算术强度都在 1-2 FLOPs/Byte 之间,远低于临界值 240(TPU v5e)或 298(H100)。这意味着:
Attention 在 Generation 阶段永远是 memory-bound,无论 batch size 多大。
这与 linear layers 形成鲜明对比:
- Linear layers:AI ≈ B(可以通过增大 batch 变成 compute-bound)
- Attention:AI ≈ 1(无法通过 batch 改善,因为 S 同时出现在分子和分母)
长序列的性能影响
随着序列长度 S 增长,Attention 的时间开销:
\[T_{\text{attn}} \approx \frac{2NHS \times 3}{\text{HBM BW}} = \frac{6NHS}{\text{HBM BW}}\]对于 LLaMA 70B(N=64, H=128),序列长度 S=4096:
- 每层 attention 加载:
6 × 64 × 128 × 4096 × 2 = 402 MB - 在 H100(3.35 TB/s)上:
402e6 / 3.35e12 ≈ 0.12 ms/层 - 80 层总计:
0.12 × 80 = 9.6 ms
而 linear layers(假设 batch=1):
- 加载权重:
2 × 70B = 140 GB(bf16) - 在 H100 上:
140e9 / 3.35e12 ≈ 42 ms
所以在 batch=1 时,linear layers 仍然占主导(42ms vs 9.6ms)。但当序列长度增长到 32K:
- Attention 时间:
9.6 × (32K/4K) = 76.8 ms - Linear layers 时间:仍然 42 ms(不随 S 变化)
此时 Attention 成为瓶颈! 这就是为什么长上下文推理需要特殊优化(Flash Attention、Paged Attention 等)。
10.6 理论延迟和吞吐量建模
单步延迟的理论下界
在 Generation 阶段,每步的理论最小延迟由以下公式决定:
\[T_{\text{min step}} = \frac{\text{Batch Size} \times \text{KV Cache Size} + \text{Parameter Size}}{\text{Total Memory Bandwidth}}\]这个公式的直觉:
- 分子:需要从 HBM 加载的总字节数
- 参数:每步都要加载完整模型(2P bytes,bf16)
- KV Cache:每步要读取所有历史 token 的 K 和 V(用于 attention)
- 分母:硬件的总内存带宽(所有芯片的 HBM 带宽之和)
LLaMA 2-13B 的实际建模
让我们用一个具体例子来演示。假设模型参数:
| 超参数 | 值 |
|---|---|
| L (层数) | 40 |
| D (d_model) | 5,120 |
| F (FFN 维度) | 13,824 |
| N (Q heads) | 40 |
| K (KV heads) | 40 |
| H (head_dim) | 128 |
| V (词表大小) | 32,000 |
参数量计算:
- MLP 参数:
L × D × F × 3 = 40 × 5120 × 13824 × 3 = 8.5B - Attention 参数:
L × 2 × D × H × (N + K) = 40 × 2 × 5120 × 128 × 80 = 4.2B - Embedding:
D × V = 5120 × 32000 = 0.16B - 总计:约 12.9B 参数(bf16 下 25.8 GB)
KV Cache 大小(每 token):
\[\text{KV size/token} = 2 \times L \times K \times H \times 2 = 2 \times 40 \times 40 \times 128 \times 2 = 819 \text{ KB}\]对于序列长度 S=2048:
\[\text{KV cache/sequence} = 819 \text{ KB} \times 2048 = 1.68 \text{ GB}\]单卡推理(H100)
假设在单张 H100(HBM 带宽 3.35 TB/s)上推理,batch size = 1:
\[T_{\text{step}} = \frac{1 \times 1.68e9 + 25.8e9}{3.35e12} = \frac{27.5e9}{3.35e12} \approx 8.2 \text{ ms}\]吞吐量:1 / 0.0082 ≈ 122 tokens/s(单请求)
如果增大 batch size 到 16(假设内存足够):
\[T_{\text{step}} = \frac{16 \times 1.68e9 + 25.8e9}{3.35e12} = \frac{52.7e9}{3.35e12} \approx 15.7 \text{ ms}\]吞吐量:16 / 0.0157 ≈ 1019 tokens/s(总吞吐量提升 8.4×)
多卡推理(4×H100,TP=4)
使用 Tensor Parallelism 将模型分片到 4 张 H100:
- 每卡参数:
25.8 GB / 4 = 6.45 GB - 每卡 KV cache:
1.68 GB / 4 = 0.42 GB(假设 KV 也分片) - 总带宽:
3.35 TB/s × 4 = 13.4 TB/s
吞吐量:16 / 0.0039 ≈ 4103 tokens/s
但这忽略了 TP 的通信开销!实际上每个 linear layer 需要一次 AllReduce:
\[T_{\text{comms}} = \frac{2 \times 16 \times 5120}{450e9} \approx 0.36 \text{ ms/层}\]80 层(40 层 × 2 个 linear layers/层):0.36 × 80 = 28.8 ms
实际总时间:3.9 + 28.8 = 32.7 ms(通信占主导!)
实际吞吐量:16 / 0.0327 ≈ 489 tokens/s(远低于理论值)
📋 背景知识:为什么 TP 在推理中效果不如训练
在训练中:
- Batch size 大(数千 tokens)→ 计算时间长 → 通信可以被计算掩盖
- 通信时间 ∝ B,计算时间 ∝ B → 比例不变
在推理中:
- Batch size 小(数十 tokens)→ 计算时间短 → 通信无法掩盖
- 每步都要通信,累积开销大
这就是为什么推理更倾向于用更少的 TP degree(TP=2-4),或者干脆不用 TP。
内存容量限制
单张 H100 有 80 GB HBM。能支持多大的 batch size?
- 模型参数:25.8 GB
- 每序列 KV cache(S=2048):1.68 GB
- 激活值(临时):约 0.5 GB/序列
实际上由于内存碎片和其他开销,通常只能达到理论值的 70-80%,所以实际 max batch ≈ 16-20。
10.7 GQA / MQA 的推理优势
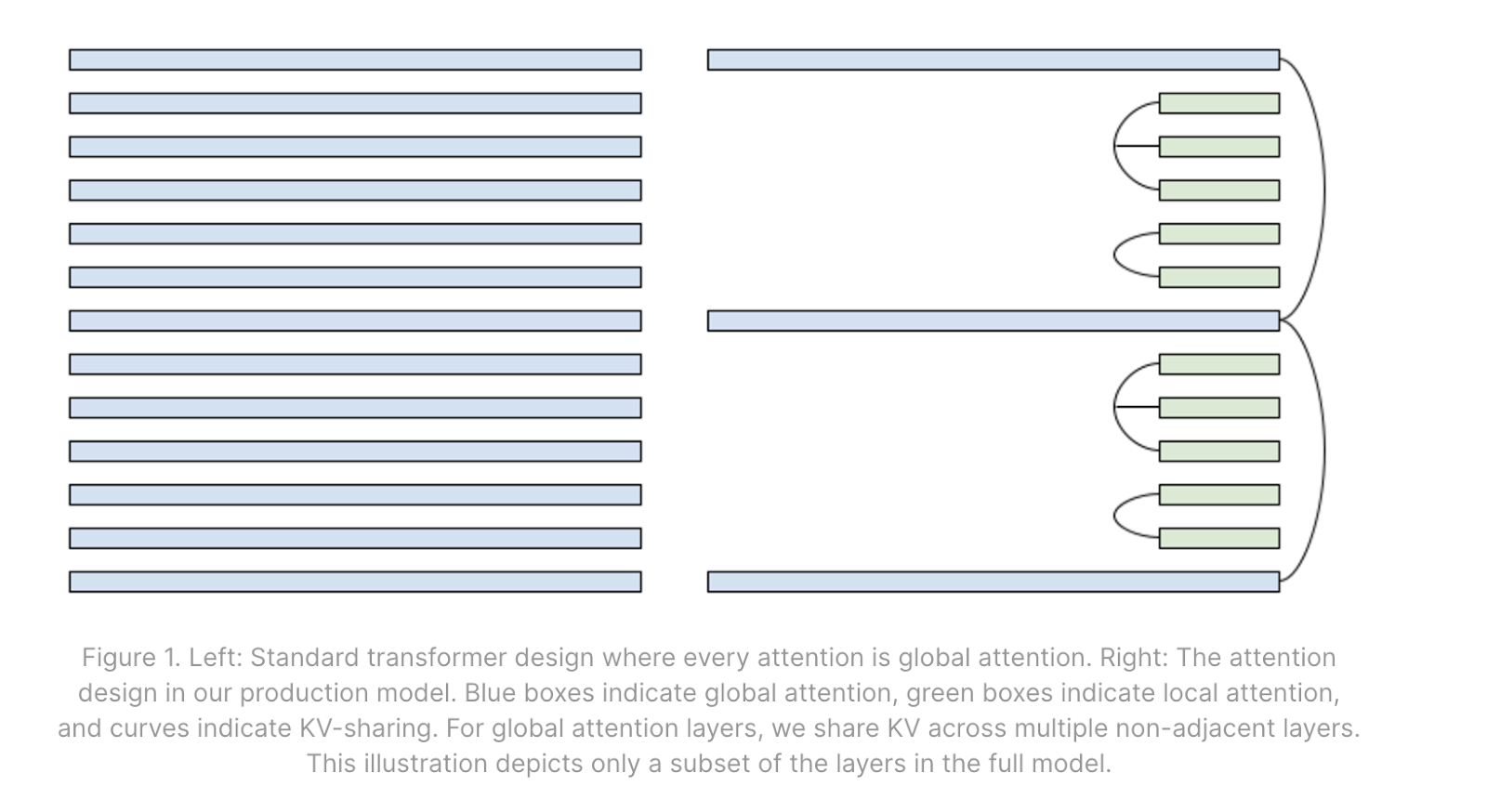
- MHA(Multi-Head Attention):每个 head 有独立的 KV → KV cache 最大
- GQA(Grouped Query Attention):多个 Q head 共享一组 KV → KV cache 缩小 H/Kv_heads 倍
- MQA(Multi-Query Attention):所有 Q head 共享一组 KV → KV cache 最小
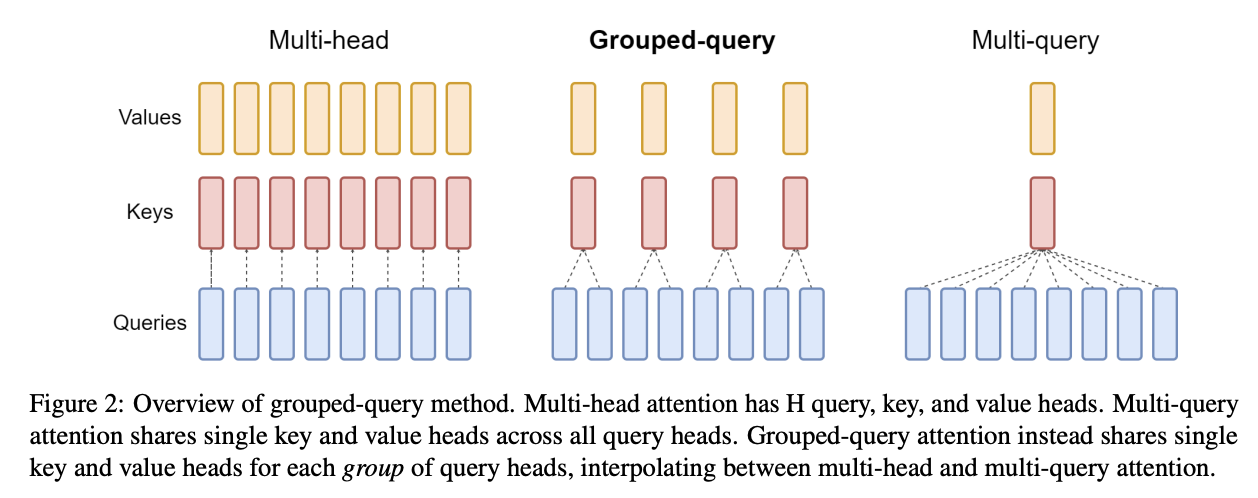
LLaMA 3 使用 GQA(64 Q heads, 8 KV heads)→ KV cache 只有 MHA 的 1/8。
GQA 对推理性能的量化影响
让我们用 LLaMA 2-13B 的参数,在 8×TPU v5e(128 GiB HBM,6.5 TiB/s 总带宽,1600 TF/s 总算力)上对比 MHA 和 GQA 的性能差异。
MHA 版本(K=40,和 Q heads 一样多):
KV cache/token = 2 × 40 × 40 × 128 × 2 = 819 KB,序列长度 8192 → KV cache/sequence = 6.7 GB。
| Batch Size | KV Cache (GiB) | 总内存 (GiB) | 理论步时 (ms) | 理论吞吐 (tokens/s) |
|---|---|---|---|---|
| 1 | 6.7 | 32.7 | 4.98 | 201 |
| 8 | 53.6 | 79.6 | 12.13 | 659 |
| 16 | 107.2 | 133.2 | 20.30 | 788 |
| 32 | 214.4 | 240.4 | 36.65 | 873 |
| 64 | 428.8 | 454.8 | 69.33 | 923 |
| 240 | 1,608 | 1,634 | 249.09 | 964 |
batch > 16 就 OOM 了! 128 GiB HBM 只能容纳约 16 个并发序列。吞吐量被 KV cache 内存卡在了 788 tokens/s。
GQA 版本(K=8,5:1 GMQA 比例):
KV cache/token = 2 × 40 × 8 × 128 × 2 = 164 KB,序列长度 8192 → KV cache/sequence = 1.34 GB(减少 5×)。
| Batch Size | KV Cache (GiB) | 总内存 (GiB) | 理论步时 (ms) | 理论吞吐 (tokens/s) |
|---|---|---|---|---|
| 1 | 1.34 | 27.34 | 4.17 | 240 |
| 8 | 10.72 | 36.72 | 5.60 | 1,429 |
| 16 | 21.44 | 47.44 | 7.23 | 2,212 |
| 32 | 42.88 | 68.88 | 10.50 | 3,048 |
| 64 | 85.76 | 111.76 | 17.04 | 3,757 |
| 240 | 321.6 | 347.6 | 52.99 | 4,529 |
GQA 的优势是全方位的:
- 延迟:batch=1 时从 4.98ms 降到 4.17ms(KV cache 加载更少)
- 最大 batch size:从 16 提升到 64+(相同 HBM 下)
- 吞吐量:从 788 提升到 3,757 tokens/s(batch=64 时提升 4.7×)
后来的 LLaMA-3 8B 采用了 32 Q heads + 8 KV heads 的 GQA 设计,正是基于这一分析。
🔑 关键要点
KV cache 的大小不仅影响内存占用,更直接决定了推理的最终性能。通过 GQA/MQA 等架构设计和量化等运行时优化来控制 KV cache 大小,是推理优化的核心杠杆。
其他减少 KV Cache 的技术
除了 GQA/MQA,还有几种在模型架构和推理运行时层面减少 KV cache 压力的方法:
混合 Local/Global Attention 层:将部分 Transformer 层替换为 local attention(只关注最近 W 个 token)。local attention 层的 KV cache 有上限(= W),不随上下文长度增长。
跨层共享 KV cache:多个相邻层共享同一组 KV 投影(如 Character.ai 的实践)。注意:虽然减少了 KV cache 的内存占用,但共享的 KV 可能需要多次从 HBM 读取,不一定改善步时间。
Paged Attention:借鉴操作系统虚拟内存管理,将 KV cache 按”页”分配(如每页 16 tokens),避免预分配最大长度造成的浪费。这是 vLLM 的核心创新,将 KV cache 内存利用率从 ~40% 提升到 ~95%。
10.8 Batching 和吞吐量优化
单请求延迟
对于单个请求,端到端延迟为:
\[\text{Total latency} = T_{\text{prefill}} + n_{\text{output}} \times T_{\text{decode}}\]其中:
- $T_{\text{prefill}}$:Time to First Token (TTFT)
- $n_{\text{output}}$:生成的 token 数量
- $T_{\text{decode}}$:每个 token 的生成时间(Inter-Token Latency, ITL)
Batching 的效果
关键洞察:在 Generation 阶段,增加 batch size 的效果:
- 权重加载量不变:无论 batch 多大,模型参数只需加载一次
- KV cache 加载量线性增长:batch size × KV cache size
- 计算量线性增长:batch size × FLOPs
这意味着随着 batch size 增大,算术强度逐渐提升:
\[\text{AI}(B) = \frac{2BDF}{2P + B \times \text{KV size}}\]当 B 足够大时,分母中 KV cache 项占主导,AI 趋近于:
\[\text{AI} \approx \frac{2BDF}{B \times \text{KV size}} = \frac{2DF}{\text{KV size}}\]这是一个常数!意味着即使 batch 很大,Generation 仍然是 memory-bound(只是程度减轻了)。
吞吐量建模
系统的总吞吐量(tokens/s)取决于是 compute-bound 还是 memory-bound:
\[\text{Throughput} = \min\left(\frac{\text{FLOPs/s}}{2P}, \frac{\text{HBM BW}}{2P/B + \text{KV size}}\right) \times B\]临界 batch size(从 memory-bound 转为 compute-bound):
\[B_{\text{crit}} = \frac{\text{FLOPs/s}}{\text{HBM BW}} - \frac{\text{KV size}}{2P} \times \frac{\text{FLOPs/s}}{\text{HBM BW}}\]对于 TPU v5e(忽略 KV cache 项的简化):
\[B_{\text{crit}} \approx \frac{1.97 \times 10^{14}}{8.2 \times 10^{11}} \approx 240\]对于 H100:
\[B_{\text{crit}} \approx \frac{9.9 \times 10^{14}}{3.35 \times 10^{12}} \approx 295\]实践意义:
- Batch < 240:增大 batch 可以近似线性提升吞吐量
- Batch > 240:吞吐量增长放缓,受限于计算能力
- 但实际上由于 KV cache 的内存占用,很难达到这么大的 batch
💡 Pop Quiz
假设要在 TPU v5e 4×4 slice(16 芯片,每芯片 HBM 带宽 8.2×10¹¹ B/s,FLOPs 1.97×10¹⁴ bf16)上对一个 30B 参数的 dense 模型做 generation。使用 int8 权重 + bf16 计算,上下文 8192,KV cache 100 kB/token。
Q1:batch size = 4 时,延迟下界是多少? Q2:batch size = 256 时呢?
点击查看答案
batch=4:int8 权重占 30e9 bytes,KV cache/sequence = 100e3 × 8192 = 819 MB。
batch 小,memory-bound: \(T = \frac{4 \times 819e6 + 30e9}{16 \times 8.2e11} = \frac{33.3e9}{1.31e13} \approx 2.5 \text{ ms}\)
batch=256:MLP 已进入 compute-bound 区间(int8 权重 + bf16 的 B_crit = 120),attention 仍 memory-bound。
\[T \approx \underbrace{\frac{256 \times 819e6}{16 \times 8.2e11}}_{\text{attention (bandwidth)}} + \underbrace{\frac{2 \times 256 \times 30e9}{16 \times 1.97e14}}_{\text{MLP (compute)}} = 16.0 + 4.9 \approx 21 \text{ ms}\]
注意 batch=256 下,吞吐量 = 256/0.021 ≈ 12,200 tokens/s,而 batch=4 的吞吐量 = 4/0.0025 = 1,600 tokens/s。batch 增加 64×,吞吐量只增加 7.6× — 这就是 KV cache 带来的边际收益递减。 </details>
延迟-吞吐量权衡
增大 batch size 的权衡:
- ✅ 吞吐量提升:更多请求并行处理
- ❌ 延迟增加:每步处理更多 token,单步时间变长
- ❌ 内存压力:更多 KV cache 占用
典型的 Pareto 曲线:
| Batch Size | 单步延迟 (ms) | 吞吐量 (tokens/s) | 内存占用 (GB) |
|---|---|---|---|
| 1 | 8 | 125 | 27 |
| 4 | 10 | 400 | 32 |
| 16 | 16 | 1000 | 52 |
| 64 | 35 | 1829 | 132 |
| 256 | 95 | 2695 | 456 |
(基于 LLaMA 2-13B,H100,S=2048)
选择策略:
- 低延迟场景(聊天机器人):batch = 1-4
- 高吞吐场景(批量评估):batch = 64-256
- 平衡场景(生产服务):batch = 16-32
Batch Size > 240 真的是一个硬性分界线吗?
理论上 $B_{\text{crit}} = 240$ 是一个分界点,但实际情况会更平滑。下面是原书提供的经验数据(d_model=8192, d_ff=32768, 4-way TP):
经验观察:
- Batch < 240 时:步时间几乎不变(memory-bound,带宽是瓶颈,多一点计算不影响)
- Batch > 240 后:步时间开始线性增长(compute-bound,FLOPs 成为瓶颈)
- 吞吐量在 batch ≈ 240 处达到拐点,此后增长非常缓慢
为什么不是一个锐利的分界?
- XLA/CUDA 编译器不能完美地重叠 HBM 读取和计算
- 对分片模型,编译器也难以完美重叠 ICI 通信和计算(通常在 batch > 32 时开始看到延迟增加)
- 实际中 batch > $B_{\text{crit}}$ 后仍有少量吞吐量提升
Prefill 的分片策略
虽然 Generation 的分片受到严格限制(详见 Ch11),但 Prefill 几乎和训练一样灵活:
通用规则(假设单序列 prefill):
- Model Parallelism 优先:先做 Megatron 风格的 TP,直到 ICI-bound(通常 4-8 way,和训练时相同的阈值 $F / \alpha_{\text{ici}}$)
- Sequence Parallelism 补充:超过 TP 上限后,沿序列维度分片。类似训练中的 DP,但分片的是序列而非 batch。通信代价是 attention 中需要额外的 Ring Attention 或 AllGather。
这意味着 prefill 和 generation 的最优分片策略通常不同,这也是 Disaggregated Serving(下一节)将两者分离的另一个动机。
🛠️ 实践:Megatron-LM 的推理配置
Megatron-LM 的推理配置需要区分 prefill 和 generate 的特点:
# 推理时的典型配置 --tensor-model-parallel-size 8 \ # TP=8(推理常用更大的 TP) --pipeline-model-parallel-size 1 \ # 推理不用 PP(延迟太高) --micro-batch-size 1 \ # 推理通常小 batch --max-tokens-to-oom 4096 # 动态分配 KV cache 内存关键区别:训练时 PP 可以提升吞吐量,但推理时 PP 会增加每个 token 的延迟(需要经过多个 stage)。因此推理几乎从不使用 PP,而是用更大的 TP。
10.9 从性能模型到推理引擎
到这里为止,我们已经得到推理系统最重要的性能分解:
| 问题 | 本章给出的答案 | 后续展开 |
|---|---|---|
| 为什么 prefill 和 generation 要分开看 | prefill 更像训练前向,通常 compute-bound;generation 每步重读权重和 KV cache,通常 memory-bound | 第 11 章讲 engine 如何调度两类任务 |
| 为什么 batching 能提升吞吐 | linear 层的权重加载可以被更多请求摊薄,但 KV cache 会带来边际收益递减 | 第 11 章讲 continuous batching / chunked prefill |
| 为什么 KV cache 是核心瓶颈 | KV cache 同时限制并发数、attention 带宽和长上下文延迟 | 第 11 章讲 PagedAttention / Prefix Caching / KV cache 分片 |
| 为什么 serving sizing 不能只看最小可部署拓扑 | 最小拓扑能放下权重,但未必有足够 HBM 留给 batch 和 KV cache | 第 12 章用 LLaMA 3 做端到端 sizing |
一个自然推论是:prefill 和 generation 往往不该被同一种资源配置绑死。Prefill 喜欢高 FLOPs、大 token batch;generation 更关心 HBM 带宽、KV cache 容量和稳定的 per-token latency。这就是 disaggregated serving 的动机:让 prefill 侧专门处理 prompt,把生成好的 KV cache 交给 decode 侧继续逐 token 生成。
这里先只保留概念,不展开实现细节。真正的推理引擎设计会涉及 continuous batching、chunked prefill、PagedAttention、prefix caching、speculative decoding,以及 SGLang/vLLM 这类系统的具体调度策略,这些放到第 11 章统一讲;LLaMA 3-70B 该用几张卡、batch 能开多大、TTFT/ITL 怎么估,则放到第 12 章。
10.10 Worked Problems(习题与详解)
以下习题改编自原书,帮助你巩固推理性能分析的核心概念。
Problem 1:参数量和 KV Cache 计算
题目:假设一个模型有以下超参数:
| 超参数 | 值 |
|---|---|
| L (层数) | 64 |
| D (d_model) | 4,096 |
| F (FFN 维度) | 16,384 |
| N (Q heads) | 32 |
| K (KV heads) | 8 |
| H (head_dim) | 256 |
| V (词表大小) | 32,128 |
假设输入和输出 embedding 共享权重。
- 模型有多少参数?
- 每个 token 的 KV cache 大小是多少(int8 格式)?
- 对于序列长度 128K,每个序列的 KV cache 总大小是多少?
点击查看答案
1. 参数量计算:
- MLP 参数:
L × D × F × 3 = 64 × 4096 × 16384 × 3 = 12.9B- 每层有 3 个矩阵:
W_in[D, F],W_gate[D, F],W_out[F, D]
- 每层有 3 个矩阵:
- Attention 参数:
L × 2 × D × H × (N + K) = 64 × 2 × 4096 × 256 × (32 + 8) = 5.4B- 每层:
W_Q[D, N×H],W_K[D, K×H],W_V[D, K×H],W_O[N×H, D] - 注意 K 和 V 只有 8 个 heads(GQA)
- 每层:
- Embedding:
D × V = 4096 × 32128 = 0.13B
总计:12.9 + 5.4 + 0.13 = 18.4B 参数
2. KV cache/token:
\[\text{KV size/token} = 2 \times L \times K \times H \times 1 = 2 \times 64 \times 8 \times 256 = 262 \text{ KB}\](2 是因为有 K 和 V,1 byte 是 int8)
3. KV cache/sequence(S=128K):
\[262 \text{ KB} \times 128 \times 1024 = 33.5 \text{ GB}\]这非常大!单张 H100(80GB)只能容纳约 2 个这样的序列(加上模型参数)。
Problem 2:内存容量限制
题目:使用 Problem 1 的模型,在 TPU v5e 4×4 slice(16 个芯片,每个 16GB HBM)上推理。假设使用 int8 存储所有内容,并且可以完全分片 KV cache。
- 对于 128K 序列长度,最大 batch size 是多少?
- 如果将 KV heads 降低到 1(MQA),最大 batch size 是多少?
点击查看答案
总内存:16 × 16GB = 256GB
模型参数(int8):18.4B × 1 byte = 18.4GB
可用于 KV cache:256 - 18.4 = 237.6GB
每序列 KV cache:33.5GB(从 Problem 1)
最大 batch size:237.6 / 33.5 ≈ 7
如果 K=1(MQA):
- KV cache/token =
2 × 64 × 1 × 256 = 32.8 KB(减少 8 倍) - KV cache/sequence =
32.8 KB × 128K = 4.19 GB - 最大 batch size =
237.6 / 4.19 ≈ 56
结论:MQA 可以将 batch size 提升 8 倍!这就是为什么 MQA/GQA 对推理如此重要。
Problem 3:单步延迟估算
题目:使用 Problem 1 的模型,在单张 TPU v5e(HBM 带宽 8.2×10¹¹ B/s)上推理。假设 int8 格式,序列长度 2048,batch size = 1。
估算每步 generation 的理论最小延迟。
点击查看答案
需要加载的数据:
- 模型参数:
18.4B × 1 byte = 18.4GB - KV cache(S=2048):
262 KB × 2048 = 536 MB
总加载量:18.4 + 0.536 = 18.9GB
理论延迟:
\[T_{\text{step}} = \frac{18.9 \times 10^9}{8.2 \times 10^{11}} \approx 23 \text{ ms}\]吞吐量:1 / 0.023 ≈ 43 tokens/s
实际情况:
- 这是理论下界(假设完美利用带宽)
- 实际延迟通常是 1.2-1.5× 理论值(约 28-35ms)
- 还需要加上 attention 的计算时间(约 2-3ms)
Problem 4:Tensor Parallelism 的权衡
题目:使用 Problem 1 的模型,在 TPU v5e 4×4 slice 上推理。考虑两种配置:
- 配置 A:不使用 TP(每个芯片独立运行,batch=1)
- 配置 B:TP=16(所有芯片协作,batch=16)
假设 ICI 带宽 = 4.5×10¹⁰ B/s(单向),序列长度 2048。
- 配置 A 的单步延迟和总吞吐量是多少?
- 配置 B 的单步延迟(忽略通信)和通信时间是多少?
- 哪个配置更好?
点击查看答案
配置 A(无 TP):
- 每芯片延迟:23ms(从 Problem 3)
- 总吞吐量:
16 × 43 = 688 tokens/s - 优点:无通信开销,延迟低
- 缺点:每芯片只能 batch=1(内存限制)
配置 B(TP=16):
- 参数加载(分片):
18.4GB / 16 = 1.15GB/芯片 - KV cache(分片):
536MB / 16 = 33.5MB/芯片 - 总加载:
(1.15 + 0.0335) × 16 = 18.9GB(总量不变) - 总带宽:
8.2e11 × 16 = 1.31e13 B/s - 计算时间:
18.9e9 / 1.31e13 ≈ 1.4ms
通信时间(每层需要 AllReduce):
- 每层激活:
16 × 4096 × 1 byte = 65.5 KB(batch=16, D=4096, int8) - AllReduce 时间:
2 × 65.5e3 / 4.5e10 ≈ 2.9 μs/层 - 64 层 × 2 个 linear/层:
2.9 × 128 = 0.37ms
总延迟:1.4 + 0.37 = 1.77ms
吞吐量:16 / 0.00177 ≈ 9040 tokens/s
结论:配置 B 好得多!
- 延迟降低:23ms → 1.77ms(13×)
- 吞吐量提升:688 → 9040 tokens/s(13×)
- 原因:TP 增加了总带宽,且 batch=16 使得通信开销相对较小
Problem 5:MoE 模型的推理
题目:将 Problem 1 的模型改为 MoE,参数:
- E = 16(专家数)
- k = 2(每 token 激活的专家数)
- 其他参数不变
- 总参数量和激活参数量是多少?
- 在 TPU v5e 上,需要多大的 batch size 才能变成 compute-bound?
- KV cache 大小是否改变?
点击查看答案
1. 参数量:
MoE 将每层的 MLP 替换为 E 个专家:
- MLP 参数(MoE):
L × D × F × 3 × E = 64 × 4096 × 16384 × 3 × 16 = 206B - Attention 参数:不变,5.4B
- Embedding:不变,0.13B
- 总参数:
206 + 5.4 + 0.13 = 211.5B
激活参数(每 token 只用 k=2 个专家):
- MLP 参数(激活):
L × D × F × 3 × k = 64 × 4096 × 16384 × 3 × 2 = 25.8B - 总激活参数:
25.8 + 5.4 + 0.13 = 31.3B
2. Compute-bound 的 batch size:
MoE 的 HBM roofline 变化:
- 加载参数:增加 E/k = 16/2 = 8 倍
- FLOPs:只增加 k 倍(因为只激活 k 个专家)
- 临界 batch size:
240 × (E/k) = 240 × 8 = 1920
需要 1920 tokens 才能 compute-bound!这就是为什么 MoE 推理效率较低。
3. KV cache:
不变!MoE 只改变 FFN,不改变 attention。仍然是 262 KB/token。
Problem 6:MoE Expert Sharding
题目:使用 Problem 5 的 MoE 模型(211.5B 参数),在 TPU v5e 上做推理。FFN 权重形状为 [E, D, F] = [16, 4096, 16384],分片为 [E_Z, D_X, F_Y](X 只在训练时用于 FSDP)。
- 在 TPU v5e 8×16 slice(Y=8, Z=16)上,HBM 权重加载时间是多少?每个 TPU 有多少剩余 HBM?
- 能容纳该模型的最小 slice 是什么?
点击查看答案
1. 8×16 slice(128 芯片):
int8 参数总量:211.5e9 bytes = 211.5 GB。
每芯片参数:211.5 / 128 = 1.65 GB。
HBM 加载时间:1.65e9 / 8.2e11 = 2.0 ms
每芯片剩余 HBM:16 - 1.65 = 14.35 GB
总剩余 HBM:14.35 × 128 = 1836 GB(大量空间用于 KV cache!)
2. 最小 slice:
每芯片有 16 GB HBM。模型 int8 占 211.5 GB。
最少芯片数:⌈211.5 / 16⌉ = 14 芯片
TPU 拓扑限制:最小满足条件的 slice 是 4×4 = 16 芯片。
每芯片参数:211.5 / 16 = 13.2 GB,剩余 2.8 GB/芯片用于 KV cache。
KV cache/token = 262 KB。在 2.8 GB × 16 = 44.8 GB 总剩余 HBM 中:
- 序列长度 8192:KV/seq = 2.15 GB → 最大 batch =
44.8 / 2.15 ≈ 20 - 序列长度 128K:KV/seq = 33.5 GB → 最大 batch =
44.8 / 33.5 ≈ 1
Problem 7:推理分片设计(综合题)
题目:使用 Problem 1 的模型(18.4B 参数),在 TPU v5e 4×4 slice 上推理。使用 int8 权重和 int8 FLOPs。
考虑以下问题:
- 4×4 拓扑的 ICI 网络是什么样的?有多少带宽?
- 对于 prefill,如何分片?
- 对于 generation(batch=32),如何分片?generation 的大致步时间是多少?
点击查看答案
1. ICI 拓扑:
4×4 TPU v5e 是一个 2D torus mesh。每个芯片在 X 和 Y 方向各有 2 条 ICI link。
每条 link 带宽:45 GB/s(单向),每个方向总带宽约 90 GB/s。
2. Prefill 分片:
Prefill 是 compute-bound,和训练类似:
- Model parallelism 优先:Megatron TP 在 Y 方向。Roofline 的 ICI bound:
F / α = 16384 / 2200 ≈ 7.4。所以在一个方向最多约 8-way TP(4×4 的一个维度正好 4 way)。 - 使用 4-way TP(Y=4),剩下的 X=4 做 data/sequence parallelism。
- int8×int8 提供 400 TOPs/s/芯片 → 总 6.4 PF/s → 对 2048 token 的 prompt:
2 × 2048 × 18.4e9 / 6.4e15 ≈ 11.8 msTTFT
3. Generation 分片(batch=32):
Generation 是 memory-bound。可以超越训练的 ICI bound:
\[Y_{\max} = \frac{F}{B \cdot \beta} = \frac{16384}{32 \times (8.2e11 / 4.5e10)} = \frac{16384}{32 \times 18.2} = 28\]所以 16-way TP(用满所有 16 芯片)完全没问题!
分片方案:全部 16 芯片做 TP。
- 参数加载时间:
18.4e9 / (16 × 8.2e11) = 1.4 ms - KV cache 加载:每 token 262 KB,S=2048,每芯片
32 × 262e3 × 2048 / 16 = 1.07 GB- 加载时间:
1.07e9 / 8.2e11 = 1.3 ms
- 加载时间:
- 通信时间:
2 × 32 × 4096 / 4.5e10 ≈ 5.8 μs/层,128 个 linear →0.74 ms
总步时间 ≈ 1.4 + 1.3 + 0.74 ≈ 3.4 ms
吞吐量 = 32 / 0.0034 ≈ 9,400 tokens/s
注意:KV cache 有 8 个 heads(K=8),16-way TP 超过了 head 数量。需要同时沿 batch 维度分片:Y=8(head 分片),Z=2(batch 分片),这引入 AllToAll 通信。实际延迟会比上面的估算稍高。
关键要点
- 推理有两个阶段:Prefill(compute-bound)和 Generation(memory-bound)
- 推理的优化目标多样:离线推理关注成本,聊天关注延迟(TTFT + ITL),边缘关注单用户延迟
- Generation 是 memory-bound 因为每步只处理 1 个 token 但要加载全部权重
- 临界 batch size $B_{\text{crit}} = \beta \cdot \alpha_{\text{hbm}}$,量化可降低阈值(int8 权重 → $B_{\text{crit}}$ 减半)
- 理论最小延迟:
(Batch × KV Cache + Parameters) / Total HBM BW - Attention 的算术强度 ≈ 1,永远 memory-bound,且时间随序列长度线性增长
- KV Cache 大小:
2 × L × K × H × S × 2bytes(bf16) - GQA/MQA 大幅减少 KV cache 大小(K 倍),提升 batch size 上限和吞吐量(可达 4-5× 提升)
- 其他 KV cache 优化:Local attention、跨层 KV 共享、Paged Attention(第 11 章展开)
- Batching 可以提升吞吐量,但临界 batch size ≈ 240-300(之后增长放缓)
- Prefill 分片策略和训练类似(TP + Sequence Parallelism),Generation 几乎只能用 TP
- Disaggregated serving 的动机来自 prefill/generation 的性能差异,具体 engine 策略见第 11 章
- TP 在推理中的效果取决于 batch size 和通信开销的平衡
- MoE 模型需要更大的 batch size(E/k 倍)才能 compute-bound
进一步阅读
- 原书 Chapter 7: All About Transformer Inference(前半部分)
- GQA 论文 (Ainslie et al., 2023)
- Flash Attention 论文 (Dao et al., 2022)
- ESTI 论文 (Pope et al., 2022) — 推理 Roofline 和 Pareto 分析
- Megatron-LM Inference — NVIDIA 的分布式推理框架