本章目标:理解加速器内部的内存层级(HBM → Cache → 计算单元),以及数据搬运如何成为性能瓶颈。
对应原书:Chapter 2 (TPU internals) + Chapter 12 (GPU memory)
改写范围:原书侧重 TPU 内部数据流;GPU memory hierarchy、PCIe 和推理内存预算是工程补充。 优先级:⭐⭐⭐ 高 | 建议时间:Day 3, 约 2 小时
3.1 数据搬运的层级
无论 GPU 还是 TPU,数据在使用前都必须经过多层”搬运”:
HBM(主内存,大但慢)
↓ HBM 带宽 ~1-9 TB/s
VMEM / L2 Cache(片上缓存,小但快)
↓ 内部带宽 ~20-40 TB/s
MXU / Tensor Core(计算单元)
📋 背景知识:为什么需要内存层级?
计算机硬件有一个根本矛盾:容量大的内存必然慢,速度快的内存必然小。
层级 类比 容量 速度 寄存器 手边的便签纸 几 KB 最快 SMEM/VMEM 桌上的文件夹 几十-几百 KB 非常快 L2 Cache 抽屉里的文件 几十 MB 快 HBM 房间里的书架 几十-几百 GB 中等 CPU DRAM 隔壁仓库 几百 GB-TB 慢 矩阵乘法需要大量数据(权重 + 激活),但计算单元一次只能处理很小的 tile。内存层级的目标是让计算单元永远不等待数据——通过逐级 prefetch 和流水线。
TPU 的数据流
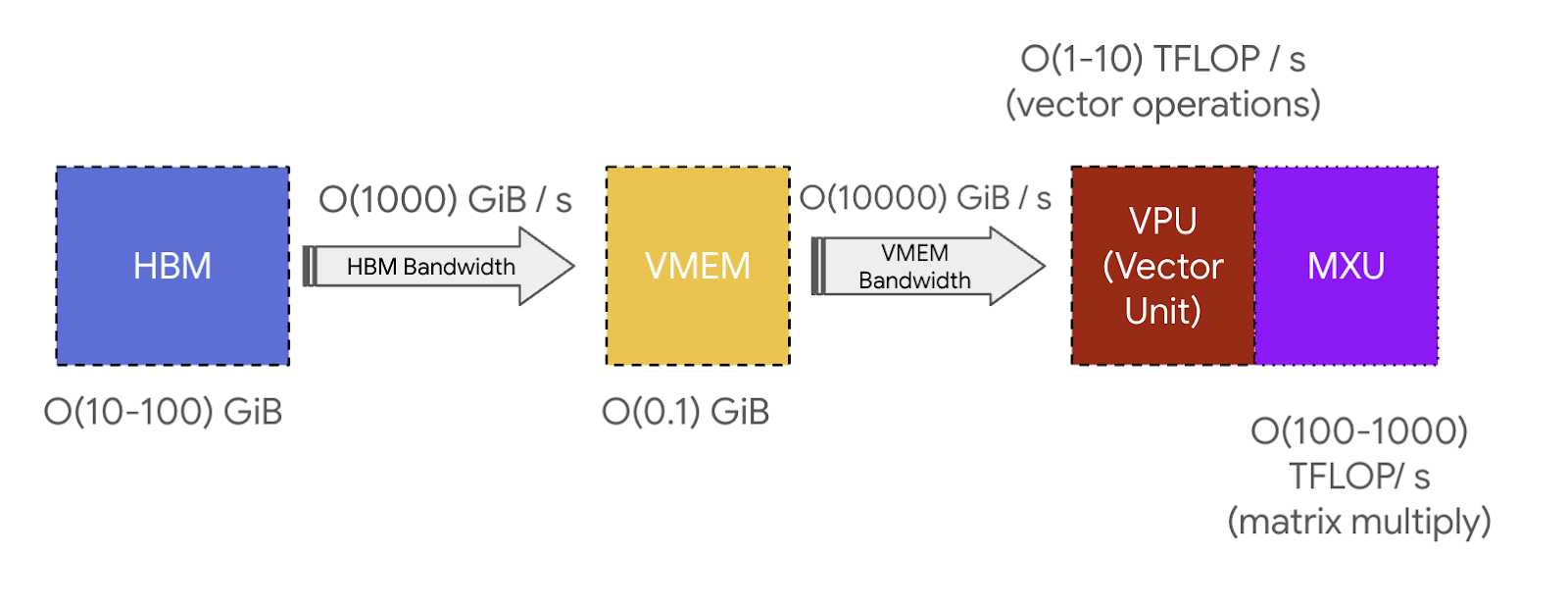
- 权重和激活值存储在 HBM 中
- 计算前,数据从 HBM 流式传入 VMEM(128 MB 片上缓存)
- 从 VMEM 加载到 VREGs(向量寄存器),再送入 MXU
- MXU 结果写回 VREGs → VMEM → HBM
关键:这个过程是流水线化(pipelined) 的 — 不需要等全部数据加载完才开始计算。
📋 背景知识:流水线(Pipelining)的概念
如果你需要处理一个很大的矩阵:
- 不用流水线:等全部数据从 HBM 搬到 VMEM,然后计算,再全部写回 → 时间 = T_load + T_compute + T_store
- 用流水线:边搬第 1 块边计算第 0 块边写回第 -1 块 → 时间 ≈ max(T_load, T_compute, T_store)
流水线是让计算和通信重叠的关键技术。如果 T_compute > T_load,MXU 不会空闲。
Double Buffering:为了让流水线不间断,VMEM 中通常分配两个 buffer——当 MXU 从 buffer A 读取数据计算时,DMA 引擎同时把下一个 chunk 从 HBM 加载到 buffer B。交替使用,永不停歇。
GPU 的数据流
GPU 的内存层级更深、更复杂:
HBM (80-192 GB, 3.35-9 TB/s)
↓
L2 Cache (50-126 MB, ~5.5 TB/s on H100, 全 SM 共享)
↓
SMEM / L1 Cache (256 kB/SM, 极高带宽, 程序员可控)
↓
Registers (256 kB/SM, 每个 thread 最多 256 个)
↓
Tensor Core / CUDA Core
GPU vs TPU 的关键差异:
| 特性 | TPU VMEM | GPU SMEM | GPU L2 Cache |
|---|---|---|---|
| 容量 | 128 MB | 32 MB (总) | 50-126 MB |
| 控制方式 | 程序员直接控制 | 程序员直接控制 | 硬件自动管理 |
| 带宽 | ~22× HBM | 极高(SM 本地) | ~1.6× HBM (5.5 TB/s) |
| 独立性 | 全芯片共享 | 每 SM 独立 | 全 SM 共享 |
TPU 的 VMEM 大且快(2× GPU L2 容量,10× GPU L2 带宽),这让 TPU 在某些推理场景中可以把整层权重放在 VMEM 里,极大减少 HBM 访问。
GPU 的 L2 Cache 是硬件自动管理的,程序员无法直接控制——一种 “spooky action at a distance”。你需要精心设计内存访问模式来利用 L2 cache,但 132 个 SM 同时竞争共享的 50 MB L2,很容易互相 evict。这也是为什么 GPU 编程中 coalesced memory access(合并内存访问)如此重要。
📋 背景知识:Coalesced Memory Access
GPU 中,同一个 warp(32 个线程)的内存访问会被合并。如果 32 个线程访问连续的 32 个 float,硬件将其合并为一次 128 字节的事务。但如果 32 个线程访问随机位置,则需要 32 次独立事务——带宽利用率降到 1/32!
这就是为什么 GPU 代码中数据布局(AoS vs SoA)如此重要。
3.2 TPU 内部架构
TensorCore 的三大组件
TPU 本质上是一个专门做矩阵乘法的机器。每个 TPU 芯片包含 1-2 个 TensorCore,每个 TensorCore 有三个核心组件:
┌─────────────────────────────────────────────┐
│ TensorCore │
│ │
│ ┌─────────────┐ ┌────────┐ ┌──────────┐ │
│ │ MXU ×4 │ │ VPU │ │ VMEM │ │
│ │ (矩阵乘法) │ │(向量op)│ │ (128 MB) │ │
│ │ 128×128 │ │8×128×4 │ │ │ │
│ │ systolic │ │ ALUs │ │ 高BW │ │
│ └─────────────┘ └────────┘ └──────────┘ │
│ ↑ ↑ ↑ │
│ └────────────────┴──────────┘ │
│ VREGs (256 KB) │
└─────────────────────────────────────────────┘
↕ HBM 带宽 (0.8-2.8 TB/s)
┌─────────────────────────────────────────────┐
│ HBM (16-96 GB) │
└─────────────────────────────────────────────┘
MXU(Matrix Multiply Unit):核心矩阵乘法引擎。
- 128×128 的 systolic array(TPU v6e 为 256×256)
- 每 8 个时钟周期完成一次
bf16[8,128] × bf16[128,128] → f32[8,128]乘法 - TPU v5e 单芯片 2 个 MXU → ~2×10¹⁴ bf16 FLOPs/s
- 这是 TPU 95%+ 的有效算力来源
VPU(Vector Processing Unit):向量运算引擎。
- 处理 ReLU、LayerNorm、softmax 等逐元素操作
- 2D SIMD 架构:8(sublane)× 128(lane)× 4 ALUs
- FLOPs 能力约为 MXU 的 1/14(~1.4×10¹³ FLOPs/s)
- 包括 reduction(求和、求最大值)操作
VMEM(Vector Memory):片上高速缓存。
- 128 MB(TPU v5e)— 比 GPU 的 SMEM 大 4×
- 带宽 ~22× HBM 带宽
- 程序员直接控制(不像 GPU L2 是自动缓存)
- 所有数据必须先到 VMEM 才能被 MXU/VPU 使用
Scalar Core(标量核心)
Scalar Core 是 TPU 的控制单元:
- 取指令、派发工作给 MXU 和 VPU
- 执行 HBM → VMEM 的 DMA 传输调度
- 单线程——每周期只能发起一个 DMA 请求
💡 TPU 的架构极端简单:一个 Scalar Core 控制 4 个 MXU + 1 个 VPU + 所有 DMA。这使得编译器的负担很重(必须精确安排所有流水线),但硬件效率极高。
3.3 Systolic Array 工作原理
MXU 的核心是一个 128×128 的 systolic array——16,384 个 ALU 排列成网格,每个 ALU 只做乘加(multiply-accumulate)。
工作流程
权重 W(RHS, 128×128)从上方逐对角线加载:
↓ ↓ ↓ ↓
┌──┬──┬──┬──┐
→ │ │ │ │ │ ← 输入 X(LHS, 8×128)从左方逐行送入
→ │ │ │ │ │
→ │ │ │ │ │
└──┴──┴──┴──┘
↓ ↓ ↓ ↓
结果从下方流出
每个 ALU 的操作:
- 从左边接收一个激活值 $x$
- 从上方接收部分和 $\text{partial_sum}$
- 计算 $\text{partial_sum} + x \times w$(其中 $w$ 是预加载的权重)
- 将新的部分和向下传递
- 将激活值向右传递
流水线效率
时间步: T0 T1 T2 T3 T4 T5 T6 ...
┌────┐
W 加载: │load│ (对角线加载权重,需要 128 周期)
└────┘
┌────┐┌────┐┌────┐┌────┐
X 流入: │ ││ X0 ││ X1 ││ X2 │... (每 8 周期一组新输入)
└────┘└────┘└────┘└────┘
┌────┐┌────┐
结果流出: │ Y0 ││ Y1 │...
└────┘└────┘
- 初始气泡:加载权重 + 第一组输入 ≈ 128+8 = 136 周期
- 稳态:之后每 8 周期产出一组
[8,128]的结果 - 矩阵必须 ≥ 128:如果矩阵某维度 < 128,systolic array 部分空闲 → 需要 padding
📋 背景知识:为什么 Systolic Array 如此高效?
矩阵乘法是极少数 $O(n^3)$ 计算 / $O(n^2)$ 数据 的算法之一。每个权重值被 8 个输入复用(沿行方向),每个输入值被 128 个权重复用(沿列方向)。这意味着:
- 一旦权重加载到 systolic array 中,就可以被多次使用而无需重新加载
- 数据在 ALU 之间直接传递(不经过内存),极大减少了内存访问
- 这也是为什么 matmul 天然适合做到 compute-bound——只要 batch 足够大
TPU v6e(Trillium)的变化
TPU v6e 将 systolic array 扩大到 256×256:
- FLOPs/周期 = 4×(面积翻倍 × 每个更大 tile 复用更多)
- 但也意味着张量的最小维度需要 ≥ 256 才能充分利用
- 适合更大的模型和 batch size
3.4 GPU SM 架构
SM(Streaming Multiprocessor)结构
GPU 的 SM 类似 TPU 的 TensorCore,但 数量多、单体小:
H100 GPU(132 个 SM):
┌─────────── SM ×132 ─────────────┐
│ ┌──────────────────────────┐ │
│ │ 4 × SM Subpartition │ │
│ │ ┌─────┐ ┌──────┐ ┌───┐ │ │
│ │ │ TC │ │32×FP32│ │Reg│ │ │
│ │ │ │ │CUDA │ │16K│ │ │
│ │ │8×8×8│ │Cores │ │ │ │ │
│ │ └─────┘ └──────┘ └───┘ │ │
│ └──────────────────────────┘ │
│ ┌──────────────────────────┐ │
│ │ SMEM / L1 Cache (256KB) │ │
│ └──────────────────────────┘ │
└─────────────────────────────────┘
↕ L2 Cache (50 MB, 共享)
↕ HBM (80 GB, 3.35 TB/s)
| 组件 | TPU 对应物 | H100 数量 | 功能 |
|---|---|---|---|
| SM | TensorCore | 132 | 计算单元容器 |
| Tensor Core | MXU | 528 (4/SM) | 矩阵乘法 |
| CUDA Core | VPU ALU | 16,896 | 向量运算 |
| SMEM | VMEM | 32 MB (总) | 片上快速缓存 |
| Register | VREGs | 32 MB (总) | 最快的存储 |
Tensor Core vs MXU
| 方面 | GPU Tensor Core | TPU MXU |
|---|---|---|
| 每芯片数量 | 528 (H100) | 2-4 |
| 单个算力 | ~7.5 TFLOPs/s | ~50 TFLOPs/s |
| Matmul 粒度 | ~8×8×8 | 8×128×128 |
| 总算力/芯片 | 990 TFLOPs/s | 197-460 TFLOPs/s |
GPU 有更多更小的 matmul 单元 → 更灵活(可以同时做不同大小的 matmul),但也更难达到峰值利用率。
CUDA Core 与 Warp 调度
📋 背景知识:SIMT vs SIMD
- SIMD(TPU VPU):所有 ALU 执行完全相同的操作,完全同步
- SIMT(GPU CUDA Core):每个线程有自己的程序计数器(PC),但一个 warp(32 线程)同时执行相同指令
SIMT 的优势:可以优雅地处理条件分支(divergence)——不同线程走不同分支时,硬件自动 mask 不活跃的线程。代价:如果 32 个线程走了不同的 if/else 分支,两个分支都要执行(时间翻倍)。
这也是为什么 GPU 代码要避免 warp divergence——让同一个 warp 的线程尽量走相同路径。
每个 SM 可以有多达 64 个 resident warps(2048 线程),但每周期只执行其中几个。当一个 warp 等待内存时,调度器自动切换到另一个 warp → 用 warp 切换隐藏内存延迟(类似 CPU 的超线程但更极端)。
Occupancy(占用率)与性能
SM 的占用率定义为:
\[\text{Occupancy} = \frac{\text{Resident Warps}}{\text{Max Warps per SM}} = \frac{\text{Resident Warps}}{64}\]高占用率让调度器有更多 warp 可切换,更好地隐藏内存延迟。但占用率受限于三个因素:
| 限制因素 | 每 SM 总量 | 过多使用的后果 |
|---|---|---|
| 寄存器 | 65,536 个 32-bit reg | 线程数被迫减少 |
| SMEM | 228 KB(可配置) | block 数被迫减少 |
| Thread blocks | 最多 32 个 | block 太少则 warp 不够 |
🛠️ 实践:理解 GPU kernel 的 Occupancy
在 Megatron-LM 或 SGLang 中使用 Flash Attention kernel 时,可以用 NVIDIA 的 Occupancy Calculator 分析:
# 使用 ncu (Nsight Compute) 分析 kernel 的 occupancy ncu --metrics sm__warps_active.avg.pct_of_peak_sustained_active \ --metrics sm__maximum_warps_per_active_cycle_pct \ python train.py # 典型 Flash Attention kernel 的 occupancy: # - 理论 occupancy: ~50% (受限于 SMEM 使用量) # - 实际 achieved occupancy: ~45% # - 但性能仍然很好,因为 compute-bound 操作不需要高 occupancy关键洞察:Compute-bound 的操作(如 matmul)不需要高 occupancy——计算单元已经满负荷了,不需要靠 warp 切换来隐藏延迟。Memory-bound 操作(如 LayerNorm)才需要高 occupancy 来隐藏 HBM 延迟。
3.5 VMEM 预取与流水线重叠
权重预取策略
TPU 的 VMEM 预取是一个关键优化。在 Transformer 层的执行中:
时间 →
┌────────────────┬────────────────┬────────────────┐
│ Attention │ FFN │ Attention │
│ (计算) │ (计算) │ (计算) │
├────────────────┼────────────────┼────────────────┤
│ 预取 FFN 权重 │ 预取 Attn 权重 │ 预取 FFN 权重 │
│ HBM→VMEM │ HBM→VMEM │ HBM→VMEM │
└────────────────┴────────────────┴────────────────┘
效果:当 Attention 计算完成时,FFN 权重已经在 VMEM 里了 → FFN 的 matmul 可以立即开始,不需要等 HBM 加载。
前提条件:
- 权重必须足够小(或经过分片)才能放进 VMEM(128 MB)
- Attention 的计算时间必须 ≥ FFN 权重的加载时间
VMEM 与算术强度
VMEM 带宽 ≈ 22× HBM 带宽。这意味着:
- 从 HBM 读取时:compute-bound 的临界算术强度 = FLOPs/s ÷ HBM BW ≈ 240
- 从 VMEM 读取时:compute-bound 的临界算术强度 = FLOPs/s ÷ VMEM BW ≈ 11
如果能把数据放在 VMEM 里,batch size 只需 11(而非 240)就能达到 compute-bound! 这对推理特别有意义——小 batch 的推理通常是 memory-bound,但如果权重在 VMEM 中,就可以在极小 batch 下也达到 compute-bound。
GPU 的对应机制:L2 Cache Residency
GPU 没有 VMEM 预取的直接等价物,但 L2 cache 提供了类似的功能:
- L2 带宽 ≈ 1.6× HBM(5.5 TB/s vs 3.35 TB/s on H100)
- 但容量只有 50 MB → 只能缓存非常小的权重
NVIDIA 提供了 cudaAccessPolicyWindow API 让程序员”暗示”哪些数据应该留在 L2 中,但效果远不如 TPU 的 VMEM 直接控制。
🛠️ 实践:Megatron-LM 与内存层级
Megatron 中利用内存层级的关键配置:
--use-flash-attn # Flash Attention: 利用 SMEM 做 attention tiling --recompute-activations # 重计算代替存储(trade compute for memory) --distribute-saved-activations # 将激活分布到多卡 --sequence-parallel # 减少每卡激活量Flash Attention 的本质就是利用内存层级差异:
- 标准 Attention:QK^T(N×N 矩阵)写入 HBM → softmax → 读回 → ×V → 写入 HBM
- Flash Attention:在 SMEM 中 tiling 完成 QK^T + softmax + ×V → 只写最终结果到 HBM
- 减少 HBM 访问量从 O(N²) 到 O(N)!
3.6 PCIe:CPU 与加速器之间的桥梁
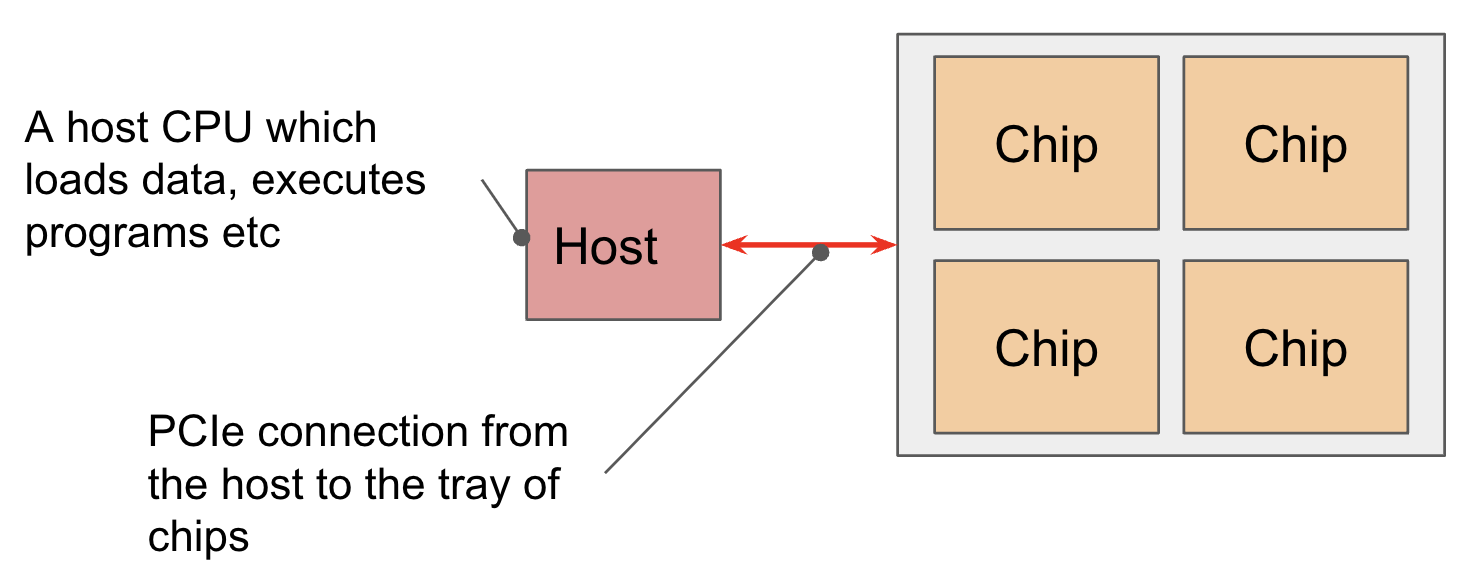
加速器通过 PCIe 连接到 CPU 主机。这是整个带宽层级中最慢的环节之一。
带宽对比
| 链路 | 带宽 | 相对 HBM | 说明 |
|---|---|---|---|
| HBM ↔ 计算 | 3.35 TB/s (H100) | 1× | 主内存 |
| NVLink | 900 GB/s | 0.27× | 节点内 GPU-GPU |
| PCIe 5.0 x16 | ~50 GB/s | 0.015× | CPU-GPU |
| IB 400G | ~50 GB/s | 0.015× | 节点间 |
| DCN (TPU) | ~6 GB/s | 0.002× | 跨 pod |
PCIe 比 HBM 慢 ~67×! 任何经过 PCIe 的操作都是潜在瓶颈。
PCIe 的用途
- 数据加载:CPU DRAM → GPU HBM(训练数据)
- Host Offload:把优化器状态/KV cache 卸载到 CPU 内存以节省 HBM
- 跨节点通信路径:GPU → PCIe → NIC → InfiniBand → NIC → PCIe → GPU
PCIe 的算术强度分析
如果某个操作需要通过 PCIe 加载数据,它的有效”PCIe Roofline”是:
\[\text{临界算术强度(PCIe)} = \frac{\text{FLOPs/s}}{\text{PCIe BW}} = \frac{9.9 \times 10^{14}}{5 \times 10^{10}} \approx 19,800\]这意味着任何需要经过 PCIe 的操作,算术强度必须 > 19,800 才能不被 PCIe 瓶颈!标准 matmul 的算术强度只有 batch_size 级别——说明从 CPU 加载权重做 matmul 是完全不可接受的。
💡 这就是为什么 GPU offloading(如 DeepSpeed ZeRO-Infinity)只在特殊场景有价值——PCIe 太慢,只有极大的 matmul(算术强度 > 20000)才不被 PCIe 拖慢。实际中主要用于优化器状态 offload(不在关键路径上)。
🛠️ 实践:SGLang 中的 CPU Offloading
SGLang 的 RadixAttention 通过将冷 KV Cache 卸载到 CPU 来节省 GPU HBM:
# SGLang 的 KV Cache offloading 策略 # 当 GPU HBM 满时,将最久未使用的 KV Cache 搬到 CPU # 关键约束:只有等下次该请求被调度时才需要搬回 # 搬回时间 = kv_size / PCIe_BW # # 例:1 个请求的 KV Cache (LLaMA 70B, seq=4096) # = 2 × 80 layers × 8 heads × 128 dim × 4096 × 2 bytes # = 1.28 GB # 搬回时间 = 1.28 GB / 50 GB/s = 25.6 ms # # 这 25.6 ms 可以和其他请求的 decode 计算重叠! # 所以 CPU offloading 在推理中比训练中更实用。训练中 PCIe offloading 只适合优化器状态(非关键路径),但推理中通过 scheduling 可以隐藏 PCIe 延迟。
3.7 内存容量约束
除了带宽,内存容量也是关键约束。训练/推理一个模型需要在 HBM 中同时存储多种数据。
训练时的内存占用
| 组件 | 每参数字节数 | 说明 |
|---|---|---|
| 模型参数(bf16) | 2 B | 前向/反向传播使用 |
| 梯度(bf16) | 2 B | 反向传播后累积 |
| Adam 一阶矩(fp32) | 4 B | 梯度的 EMA |
| Adam 二阶矩(fp32) | 4 B | 梯度平方的 EMA |
| Master weights(fp32) | 4 B | 优化器更新用的全精度副本 |
| 总计 | 16 B | 不含激活值 |
激活值的占用取决于模型架构、batch size 和序列长度:
\[\text{Activation Memory} \approx 2 \cdot L \cdot s \cdot b \cdot h \cdot (34 + 5 \frac{a \cdot s}{h})\]其中 $L$ = 层数,$s$ = 序列长度,$b$ = micro batch size,$h$ = hidden size,$a$ = attention heads。
LLaMA 70B 详细内存预算
| 组件 | 计算 | 大小 |
|---|---|---|
| 参数(bf16) | 70B × 2 B | 140 GB |
| 梯度(bf16) | 70B × 2 B | 140 GB |
| 优化器状态(fp32) | 70B × 12 B | 840 GB |
| 小计(不含激活) | 1,120 GB | |
| 激活值(估算) | seq=4096, mbs=1 | ~60 GB/layer × 80 层 ≈ 可忽略(有 checkpointing) |
单张 H100(80 GB)远远不够:
\[\lceil 1120 \text{ GB} / 80 \text{ GB} \rceil = 14 \text{ 张卡}\]这就是为什么训练 70B 模型至少需要 14 张 H100——仅存放权重和优化器状态!加上激活值和通信缓冲区,实际需要更多。
推理时的内存占用
推理时不需要梯度和优化器,但引入了 KV Cache:
| 组件 | 计算(LLaMA 70B, bf16) | 大小 |
|---|---|---|
| 模型参数 | 70B × 2 B | 140 GB |
| KV Cache(单请求) | $2 \cdot L \cdot 2 \cdot h_{kv} \cdot d \cdot s$ | 每 token ~1.3 MB |
| KV Cache(batch=256, s=4096) | 256 × 4096 × 1.3 MB | ~1.3 TB |
KV Cache 会随 batch size 和序列长度线性增长,很容易超过参数本身的内存占用!
📋 背景知识:KV Cache 为什么这么大?
在自回归生成中,每个 token 的 Attention 需要访问所有之前 token 的 Key 和 Value。为避免重复计算,这些中间值被缓存。对于 LLaMA 70B:
- 80 层,每层 8 个 KV heads(GQA),head_dim = 128
- 每 token 的 KV = $2 \times 80 \times 8 \times 128 \times 2$ bytes = 327,680 bytes ≈ 320 KB
- 4096 个 token 的完整 KV Cache = 4096 × 320 KB ≈ 1.28 GB(每请求)
当 batch=256 时,KV Cache 总量 = 256 × 1.28 GB ≈ 328 GB——比模型权重(140 GB)还大!
内存优化策略总览
| 策略 | 减少什么 | 代价 |
|---|---|---|
| 混合精度(bf16/fp16) | 参数 & 激活 | 精度略降 |
| Gradient Checkpointing | 激活值(~10×) | 增加 ~33% 计算 |
| FSDP / ZeRO-3 | 参数 + 优化器分片 | 增加 AllGather 通信 |
| ZeRO-1 | 优化器状态分片 | 少量通信开销 |
| int8/int4 量化 | 参数(2-4×) | 精度损失,需校准 |
| GQA / MQA | KV Cache(4-8×) | 需要模型架构支持 |
| Paged Attention | KV Cache 碎片 | 实现复杂 |
| CPU Offloading | HBM 占用 | PCIe 成为瓶颈 |
🛠️ 实践:Megatron-LM 中的内存管理
Megatron-LM 提供了多种内存优化配置:
# ZeRO-1: 只分片优化器状态(最常用) --use-distributed-optimizer # Gradient Checkpointing: 只保留每层输入,反向时重计算 --recompute-activations --recompute-granularity full # 重计算整个 Transformer 层 --recompute-granularity selective # 只重计算 attention(更常用) # Sequence Parallelism: 沿序列维度分片激活值 --sequence-parallel # 混合精度 --bf16 # 使用 bf16 训练 --fp32-residual-connection # 残差连接保持 fp32实际内存占用估算(LLaMA 70B, 8×H100, TP=8):
- 参数:140 GB / 8 = 17.5 GB/卡
- 优化器:840 GB / 8 = 105 GB(不分片时放不下!需要 ZeRO-1 + DP 分片)
- 激活值(selective recompute, mbs=1, seq=4096):~8 GB/卡
- 总计:~30 GB/卡(含通信缓冲)→ 80 GB 足够
3.8 关键数字速记
你应该记住的几个量级(2024-2025 代硬件):
带宽层级
| 链路 | 带宽量级 | 相对 HBM | 延迟 |
|---|---|---|---|
| VMEM/SMEM → 计算单元 | ~20-40 TB/s | 10-20× | < 10 ns |
| HBM → 计算单元 | ~1-9 TB/s | 1× | ~100 ns |
| NVLink(节点内 GPU-GPU) | ~900 GB/s | 0.1-0.3× | ~1 μs |
| ICI(TPU 芯片间) | ~90 GB/s/轴 | 0.03× | ~1 μs |
| PCIe 5.0 x16 | ~50 GB/s | 0.015× | ~1 μs |
| InfiniBand 400G(节点间) | ~50 GB/s | 0.015× | ~2-5 μs |
| DCN(TPU 跨 pod) | ~6 GB/s | 0.002× | ~10-100 μs |
容量层级
| 存储层级 | 容量 | 说明 |
|---|---|---|
| Registers / VREGs | ~256 KB/SM or /TC | 最快但极小 |
| SMEM / VMEM | 32 MB (GPU) / 128 MB (TPU) | 程序员可控片上缓存 |
| L2 Cache | 50-126 MB (GPU) | 硬件管理,全芯片共享 |
| HBM | 80-192 GB (GPU) / 16-96 GB (TPU) | 主内存 |
| CPU DRAM | 512 GB - 2 TB | 通过 PCIe 访问 |
| NVMe SSD | 数 TB | 通过 CPU,极慢 |
计算能力
| 硬件 | bf16 FLOPs/s | int8 OPs/s | 临界 AI (HBM) |
|---|---|---|---|
| TPU v5e | 1.97×10¹⁴ | 3.94×10¹⁴ | 240 |
| H100 SXM | 9.9×10¹⁴ | 1.98×10¹⁵ | ~296 |
| TPU v6e | 9.1×10¹⁴ | 1.82×10¹⁵ | ~569 |
| B200 | ~2.25×10¹⁵ | ~4.5×10¹⁵ | ~281 |
记忆法:
- 带宽从上到下大约每级慢 10×
- 容量从上到下大约每级大 100-1000×
- 速度 × 容量 ≈ 常数(物理定律的体现)
💡 速算技巧
需要估算某操作是否 compute-bound?快速公式:
- 从 HBM 读取:临界 AI ≈ 240-570(取决于芯片)
- 从 VMEM 读取:临界 AI ≈ 11(TPU)
- 从网络读取:临界 AI ≈ FLOPs/s ÷ 网络 BW(通常 2000-20000)
- 从 PCIe 读取:临界 AI ≈ 20000(几乎不可能达到)
3.9 Worked Problems(习题与详解)
Problem 1:Flash Attention 的 HBM 访问量
题目:考虑标准 Attention 和 Flash Attention 对 HBM 的访问量。假设序列长度 $N = 4096$,head dimension $d = 128$,batch size $B = 1$,单个 attention head。所有数据为 bf16。
- 标准 Attention 的 HBM 读写字节总量是多少?
- Flash Attention(tile size $B_r = B_c = 256$)的 HBM 读写字节总量是多少?
- 在 H100 上(HBM 3.35 TB/s),仅考虑内存访问时间,两者各需多长时间?
点击查看答案
1. 标准 Attention HBM 访问量:
计算步骤:$S = QK^T$,然后 $P = \text{softmax}(S)$,然后 $O = PV$
- 读取 Q, K: $2 \times N \times d \times 2 = 2 \times 4096 \times 128 \times 2 = 2$ MB
- 写入 S($N \times N$): $4096 \times 4096 \times 2 = 32$ MB
- 读取 S(做 softmax): 32 MB
- 写入 P(softmax 结果): 32 MB
- 读取 P 和 V: $32 + 1 = 33$ MB
- 写入 O: $N \times d \times 2 = 1$ MB
总计:$\approx 2 + 32 + 32 + 32 + 33 + 1 = 132$ MB
主导项是 $N \times N$ 的注意力矩阵:$O(N^2)$ 字节。
2. Flash Attention HBM 访问量:
Flash Attention 在 SMEM 中分块完成所有计算,不需要写出完整的 $S$ 或 $P$ 矩阵。
- 读取 Q: 分 $T_r = N/B_r = 16$ 个块,每块读一次 → $N \times d \times 2 = 1$ MB
- 读取 K, V: 对于 Q 的每个块,遍历所有 K/V 块 → $T_r \times N \times d \times 2 \times 2 = 16 \times 4096 \times 128 \times 4 = 32$ MB
- 写入 O: $N \times d \times 2 = 1$ MB
总计:$\approx 1 + 32 + 1 = 34$ MB
更精确地说:$O(N^2 d^2 / M)$,其中 $M$ 是 SMEM 大小。
3. 时间比较:
- 标准 Attention: $132 \text{ MB} / 3.35 \text{ TB/s} = 39 \mu s$
- Flash Attention: $34 \text{ MB} / 3.35 \text{ TB/s} = 10 \mu s$
Flash Attention 快 ~4×!对于更长序列($N = 16384$),差距会更大(标准方法 $O(N^2)$ vs Flash $O(N)$)。
延伸:对于 $N = 16384$:
- 标准 Attention 的 S 矩阵:$16384^2 \times 2 = 512$ MB(可能放不进 HBM!)
- Flash Attention 读取量:$\approx T_r \times N \times d \times 4 = 64 \times 16384 \times 128 \times 4 = 512$ MB
比值从 4× 增长到 $N/d = 128×$,验证了 $O(N^2)$ vs $O(N^2/M)$ 的理论。
Problem 2:VMEM 预取的最大权重尺寸
题目:在 TPU v5e 上,VMEM 容量为 128 MB,HBM 带宽为 0.82 TB/s。
- 如果一个 Transformer 层的 FFN 有两个权重矩阵 $W_1[D, 4D]$ 和 $W_2[4D, D]$(bf16),D 的最大值是多少才能让两个矩阵都放进 VMEM?
- 如果 Attention 计算需要 $T_{attn}$ 时间,FFN 权重预取需要 $T_{prefetch}$ 时间,当 $D = 4096$ 时,batch size $B$ 至少为多少才能保证预取完全被计算隐藏?
点击查看答案
1. VMEM 容量限制:
FFN 两个权重总大小:
\[2 \times D \times 4D \times 2 = 16D^2 \text{ bytes}\]约束:$16D^2 \leq 128 \times 10^6$
\[D \leq \sqrt{128 \times 10^6 / 16} = \sqrt{8 \times 10^6} \approx 2828\]D 最大约 2828。对于 D=4096 的模型(如 LLaMA 7B),FFN 权重 = $16 \times 4096^2 = 256$ MB > 128 MB,放不进 VMEM,需要分块加载。
实际中会使用 Tensor Parallelism 将 D 维度切分。TP=2 时每芯片只需加载一半 → 128 MB 刚好够。
2. 预取被计算隐藏的条件:
当 $D = 4096$ 时,FFN 权重总量 = 256 MB。
预取时间:
\[T_{prefetch} = \frac{256 \times 10^6}{0.82 \times 10^{12}} = 0.312 \text{ ms}\]Attention 的计算时间(主要是 $Q K^T$ 和 $\text{attn} \times V$):
\[T_{attn} \approx \frac{2 \times 2 \times B \times S \times D}{1.97 \times 10^{14}} = \frac{4BSD}{1.97 \times 10^{14}}\](这里简化为 2 个 matmul,每个 $2BSD$ FLOPs,其中 $S$ 是序列长度)
对于 prefill($S = B$ 即 token batch 等于序列长度的场景):
需要 $T_{attn} \geq T_{prefetch}$:
\[\frac{4B^2 \times 4096}{1.97 \times 10^{14}} \geq 0.312 \times 10^{-3}\] \[B^2 \geq \frac{0.312 \times 10^{-3} \times 1.97 \times 10^{14}}{4 \times 4096} = 3.75 \times 10^6\] \[B \geq 1936 \text{ tokens}\]结论:batch size ≥ ~2000 tokens 时,FFN 权重的预取可以完全被 Attention 计算隐藏。这在训练(通常 B > 8000)中总是成立,但在推理 decode(B 可能 < 256)中通常不成立——这就是为什么推理需要其他优化策略(如量化减少权重大小)。
Problem 3:Systolic Array 利用率
题目:TPU v5e 有 128×128 的 systolic array。考虑以下矩阵乘法:
bf16[64, 256] × bf16[256, 128]:MXU 利用率是多少?bf16[8, 64] × bf16[64, 64]:MXU 利用率是多少?- 对于
bf16[8, D] × bf16[D, F],D 和 F 至少为多少才能达到 100% 利用率?
点击查看答案
MXU 每 8 周期完成 bf16[8, 128] × bf16[128, 128] → f32[8, 128]。这意味着:
- LHS(左输入)的 K 维度需要是 128 的整数倍
- RHS(右输入/权重)需要是 128×128
1. bf16[64, 256] × bf16[256, 128]:
- LHS [64, 256]:沿 B=64 切成 8 组 [8, 256],沿 K=256 切成 2 块 [8, 128]
- RHS [256, 128]:沿 K=256 切成 2 块 [128, 128]
- 每组执行 2 次 MXU 操作,共 8 × 2 = 16 次 MXU 调用
- 每次 MXU 都是满载的 [8, 128] × [128, 128]
- 利用率 = 100%(所有维度都是 128 的倍数)
2. bf16[8, 64] × bf16[64, 64]:
- LHS [8, 64]:B=8 OK,但 K=64 < 128 → 需要 padding 到 [8, 128]
- RHS [64, 64]:需要 padding 到 [128, 128]
- 实际 MXU 计算:
[8, 128] × [128, 128],但只有 1/4 的计算是有效的- K 维度:64/128 = 50% 有效
- F 维度:64/128 = 50% 有效
- 利用率 = 50% × 50% = 25%
实际上更精确地说:有效 FLOPs = $2 \times 8 \times 64 \times 64 = 65,536$,MXU 做了 $2 \times 8 \times 128 \times 128 = 262,144$ FLOPs → 利用率 = 65,536 / 262,144 = 25%。
3. 100% 利用率条件:
- B 维度:MXU LHS 的 batch 固定为 8,所以 B 只需 ≥ 8(且为 8 的倍数)
- D 维度(K,contraction):必须是 128 的倍数 → D ≥ 128
- F 维度(N,输出列):必须是 128 的倍数 → F ≥ 128
所以 D ≥ 128 且 F ≥ 128(且均为 128 的整数倍)。
对于 TPU v6e(256×256 MXU),条件变为 D ≥ 256 且 F ≥ 256——这就是为什么 v6e 更适合大模型。
Problem 4:端到端 TPU 数据搬运问题
题目(改编自原书 Question 6):你有一个大矩阵 A: int8[128×1024, 128×1024](约 16 GB),均匀分片在 TPU v5e 4×4 slice(16 个芯片,2 个 host)上,存储在 host DRAM 中。你想把整个矩阵收集到 TPU{0,0} 并与一个向量 bf16[8, 128×1024] 相乘。
数据:PCIe 带宽 15 GB/s/链路,ICI 带宽 45 GB/s/方向/链路(双向 90 GB/s),HBM 带宽 820 GB/s,bf16 FLOPs/s = 1.97×10¹⁴。4×4 slice 中每个 TPU 有 2 条 ICI 链路。
- 最优的数据搬运方案是什么?
- 每一步需要多长时间?
- 总时间的下界和上界是多少?
点击查看答案
1. 最优方案:
方案 A:通过 DCN 把所有数据传到 host 0,再从 host 0 通过 PCIe 加载到 TPU{0,0} → DCN 太慢。
方案 B(最优):
- 每个 TPU 通过自己的 PCIe 链路加载本地分片到 HBM
- 通过 ICI gather 到 TPU{0,0}
- TPU{0,0} 从 HBM 加载到 MXU 执行 matmul
2. 每步时间:
Step 1 - PCIe 加载:
- 总量 16 GB 分布在 16 个 TPU 上,每 TPU 1 GB
- 16 条 PCIe 并行加载,每条 15 GB/s
- 时间 = 1 GB / 15 GB/s = 67 ms
Step 2 - ICI Gather:
- TPU{0,0} 需要接收来自其他 15 个 TPU 的数据,共 15 GB
- TPU{0,0} 只有 2 条 ICI 链路(4×4 拓扑中角落节点有 2 邻居)
- 每条链路单向 45 GB/s
- 下界时间 = 15 GB / (45 GB/s × 2) = 167 ms
- 实际可能更长(负载不均匀),约 200 ms
Step 3 - HBM 加载到 MXU:
- 加载 16 GB + 2 MB(向量,忽略)从 HBM
- 时间 = 16 GB / 820 GB/s = 19.5 ms
Step 4 - 计算 Matmul:
- FLOPs = $2 \times 8 \times 128 \times 1024 \times 128 \times 1024 = 2.75 \times 10^{11}$
- 时间 = $2.75 \times 10^{11} / 1.97 \times 10^{14}$ = 1.4 ms
3. 总时间:
- 上界(无重叠)= 67 + 167 + 19.5 + 1.4 ≈ 255 ms
- 下界(完美流水线)= max(67, 167, 19.5, 1.4) ≈ 167 ms
ICI gather 是瓶颈。实际时间大约在 170-250 ms 之间。
关键洞察:
- PCIe 并行加载是最优的(16 条链路比 1-2 条快 8-16×)
- ICI 拓扑限制了 gather 的速度(角落节点链路少)
- 最终 matmul 只要 1.4 ms——数据搬运时间是计算时间的 100-200×!
- 这就是为什么要尽量避免大规模数据搬运,尤其是从 host DRAM
关键要点
- 数据必须从 HBM → 片上缓存 → 计算单元,层层搬运;每层速度差 10×
- 流水线化让计算和搬运可以重叠,时间 ≈ max(计算, 搬运);Double Buffering 实现无停顿流水线
- TPU:VMEM 128 MB、程序员直接控制、带宽 22× HBM;GPU:L2 50 MB、硬件自动管理
- MXU 是 128×128 systolic array,每 8 周期完成
bf16[8,128]×bf16[128,128];张量维度需 ≥ 128 才能充分利用 - GPU SM 更多更小(132 个 SM × 4 Tensor Core),灵活但难达峰值;SIMT 支持分支但需避免 warp divergence
- VMEM 预取使临界算术强度从 240 降到 11,让小 batch 推理也能 compute-bound
- Flash Attention 将 HBM 访问从 $O(N^2)$ 降到 $O(N^2d^2/M)$,利用 SMEM 做 tiling
- PCIe 比 HBM 慢 ~67×(临界 AI ≈ 19,800),GPU offloading 仅适合非关键路径
- 训练 70B 模型需要每参数 ~16 bytes → 总计 1.1 TB → 至少 14 张 H100
- KV Cache 随 batch×seq 线性增长,可能超过模型参数本身的内存占用
进一步阅读
- 原书 Chapter 2: What Is a TPU → Memory & MXU 部分
- 原书 Chapter 12: What Is a GPU → Memory 部分
- 原书 Appendix B: How does a systolic array work
- Flash Attention 论文 (Dao et al., 2022) — HBM 访问量分析
- Flash Attention 2 (Dao, 2023) — 利用 warp 级并行进一步优化
- NVIDIA H100 Whitepaper — SM 架构详解
- Megatron-LM Activation Recomputation — Selective Recomputation 策略
- Systolic Array 动画 (fleetwood.dev) — 交互式理解脉动阵列
- How to Optimize a CUDA Matmul (Simon Boehm) — GPU 内存层级与 tiling 实战