本章目标:理解多芯片如何连接成集群,不同互联方式(ICI/NVLink/InfiniBand/DCN)的带宽差异,以及拓扑结构如何影响并行策略。
对应原书:Chapter 2 (TPU Networking) + Chapter 12 (GPU Networking)
改写范围:原书主线是 TPU ICI/torus 和 GPU bonus 章;NVLink、IB、SHARP 与 Megatron 配置是面向 GPU 集群的扩展。 优先级:⭐⭐⭐ 高 | 建议时间:Day 3-4, 约 2.5 小时
4.1 为什么需要集群
单张加速器的算力和内存都是有限的。训练一个大模型(如 LLaMA 70B)需要:
- 内存:远超单卡容量,需要将参数分片到多卡
- 算力:要在合理时间内完成训练,需要大量并行计算
- 目标:加 N 倍芯片 → 获得接近 N 倍的加速(strong scaling)
但芯片间需要通信(交换参数、梯度、激活值),通信时间如果超过计算时间就无法有效 scale。因此,互联带宽和拓扑结构直接决定了能用多少芯片、怎么分布计算。
4.2 TPU 的互联:ICI 与 Torus 拓扑
ICI(Inter-Chip Interconnect)
TPU 之间通过 ICI 直接连接,不经过 CPU 或交换机。这是 TPU 与 GPU 最大的网络差异。
各代 ICI 带宽:
| 型号 | 单向 ICI/link | 双向 ICI/link | 轴数 | 总 ICI/chip |
|---|---|---|---|---|
| TPU v3 | 100 GB/s | 200 GB/s | 2 | 400 GB/s |
| TPU v4p | 45 GB/s | 90 GB/s | 3 | 270 GB/s |
| TPU v5p | 90 GB/s | 180 GB/s | 3 | 540 GB/s |
| TPU v5e | 45 GB/s | 90 GB/s | 2 | 180 GB/s |
| TPU v6e | 90 GB/s | 180 GB/s | 2 | 360 GB/s |
双向带宽指单条链路两个方向的总吞吐。在有完整环(wraparound)的情况下,AllGather/ReduceScatter 的通信公式使用双向带宽。
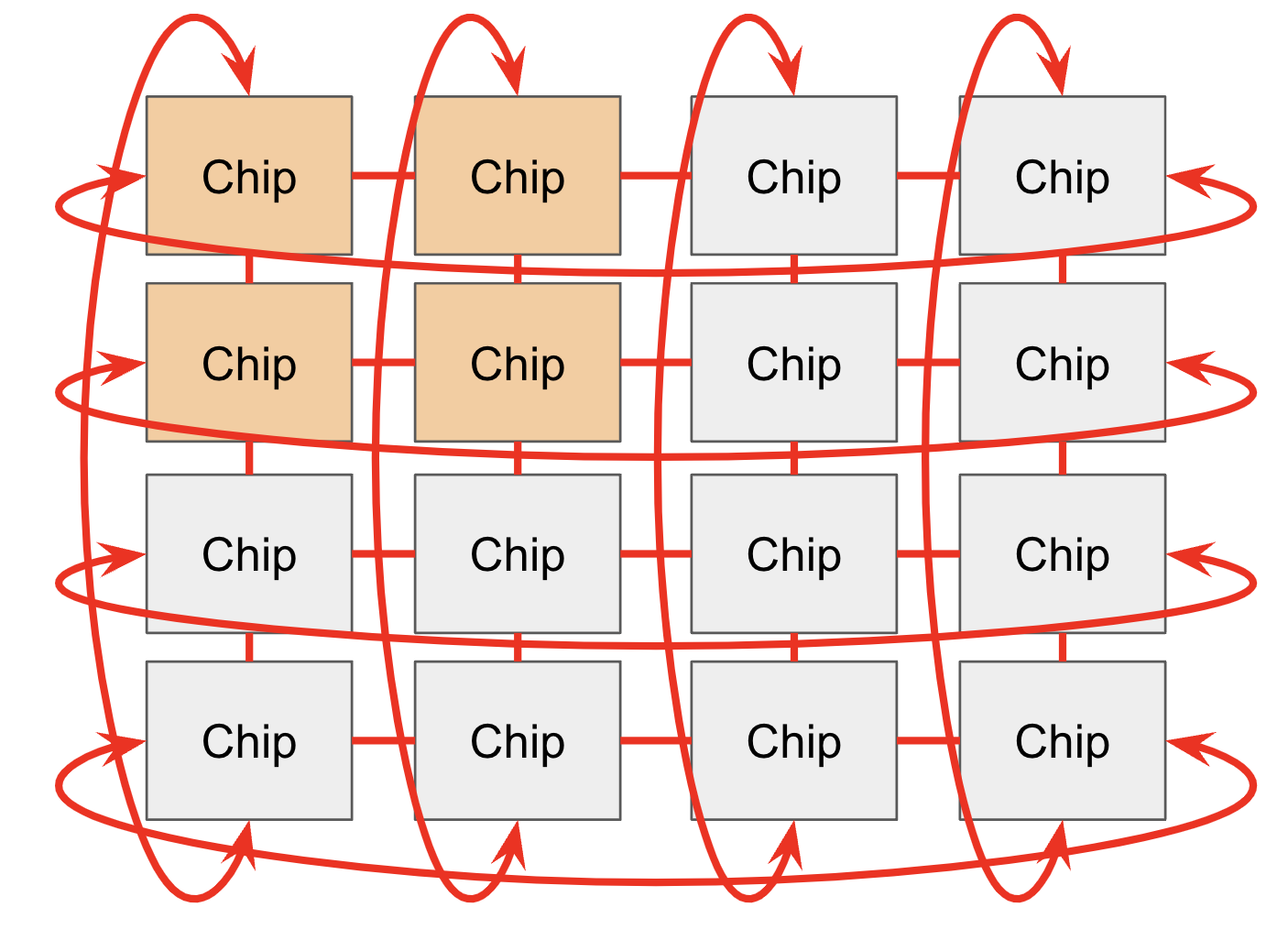
Torus 拓扑
TPU 的连接方式是 Torus(环面)拓扑:
- TPU v5e/v6e:2D Torus,最大 16×16
- TPU v4/v5p:3D Torus,如 16×16×16 或 16×20×28
📋 背景知识:什么是 Torus 拓扑
把芯片排成网格(如 4×4),每个芯片只和上下左右 4 个邻居直接相连。
- Mesh(网格):边缘芯片只有 2-3 个邻居
- Torus(环面):加上”绕回”连接(首尾相连),每个芯片都有 4 个(2D)或 6 个(3D)邻居
- 绕回连接将最远距离从 N 缩短到 N/2
- Twisted Torus:一种扭转的拓扑(类似莫比乌斯带),进一步减小平均节点距离
类比:想象一张纸的左右边粘起来(变成圆柱),再把上下粘起来(变成甜甜圈),这就是 2D torus。
Wraparound 规则(关键细节)
不是所有拓扑都有 wraparound! 这直接影响通信时间(无 wraparound → 通信时间翻倍)。
| 芯片类型 | Wraparound 条件 |
|---|---|
| TPU v4/v5p(3D) | 轴长为 4 的倍数(由光交换机提供) |
| TPU v5e/v6e(2D) | 轴长 = 16 时有 wraparound |
具体示例:
4×4×4→ 所有轴有 wraparound ✓(完整 cube)4×4×8→ 所有轴有 wraparound ✓(多个 cube)2×2×4→ 无 wraparound ✗(不是完整 cube)8×16(v5e)→ 长轴(16)有 wraparound,短轴(8)无 ✓/✗4×4(v5e)→ 无 wraparound ✗
无 wraparound 的影响:AllGather 需要的跳数从 N/2 增加到 N-1,通信时间接近翻倍。
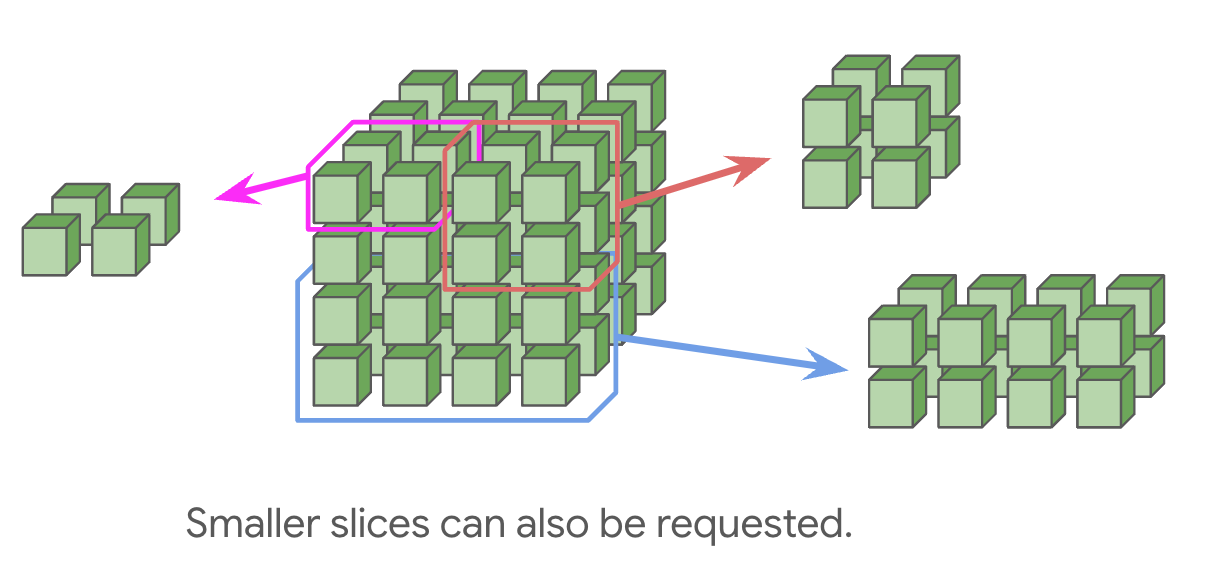
TPU Pod 与 Superpod
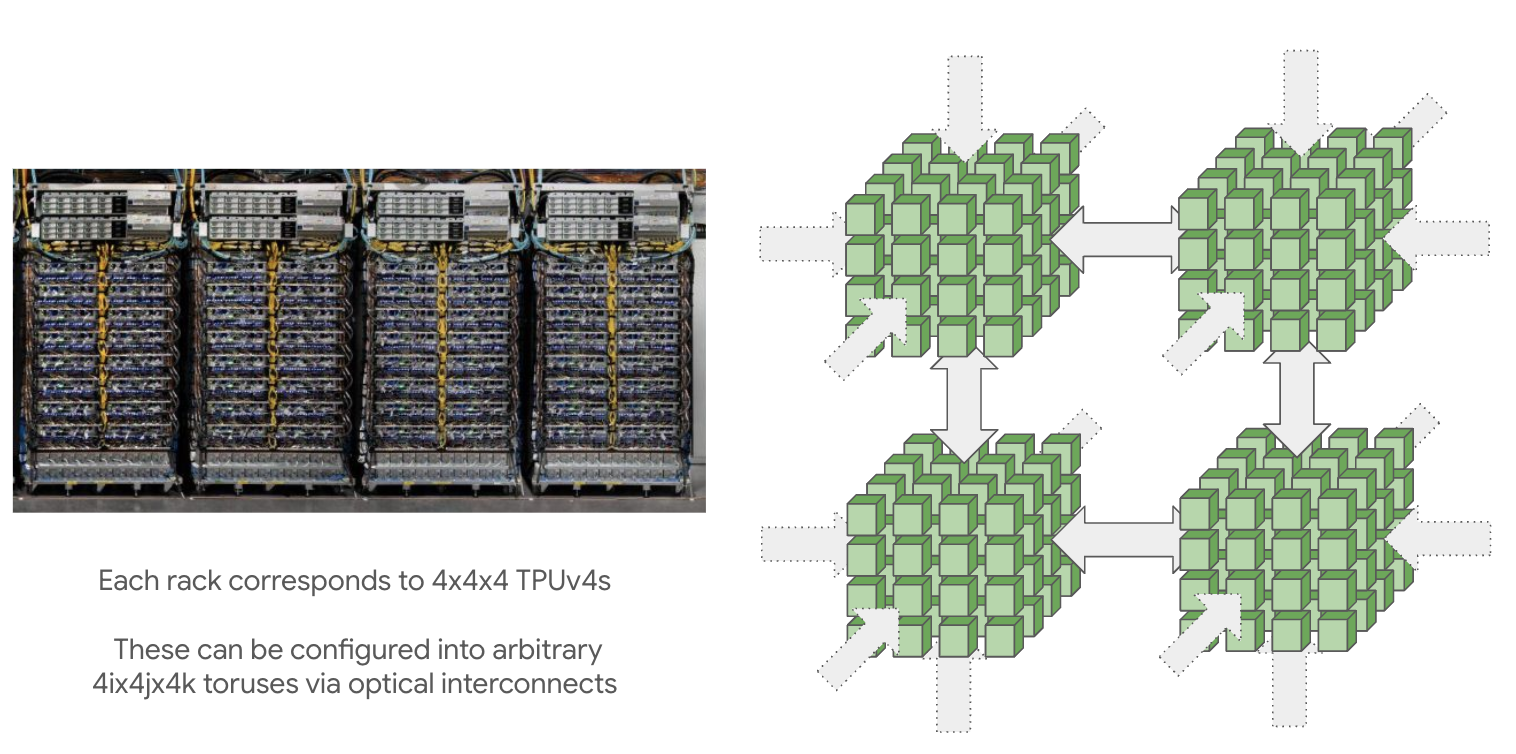
- Pod:ICI 连接的所有芯片
- TPU v4/v5p 的基本构建块:4×4×4 = 64 芯片的 “cube”
- Cube 之间通过光交换机(Optical Circuit Switch)连接,带宽与普通 ICI 相同
- 光交换机可以动态重配置连接,组装不同拓扑
最大 Pod/Superpod 规模:
| 型号 | 最大 Pod 尺寸 | 总芯片数 |
|---|---|---|
| TPU v4p | 16×16×16 | 4,096 |
| TPU v5p | 16×20×28 | 8,960 |
| TPU v5e | 16×16 | 256 |
| TPU v6e | 16×16 | 256 |
Multi-Slice 训练
一组 ICI 连接的 TPU 称为一个 slice。不同 slice 可以通过 DCN 连接:
Slice A (ICI内部高速) ←──DCN──→ Slice B (ICI内部高速)
~6 GB/s/chip
DCN 传输路径:TPU HBM → PCIe → CPU → DCN → CPU → PCIe → TPU HBM,每一步都增加延迟。因此 multi-slice 训练应该把 DCN 上的通信量最小化(通常用于 Data Parallelism)。
4.3 GPU 的互联:NVLink + InfiniBand
GPU 使用完全不同的互联策略:层级化交换机网络。
节点内:NVLink + NVSwitch
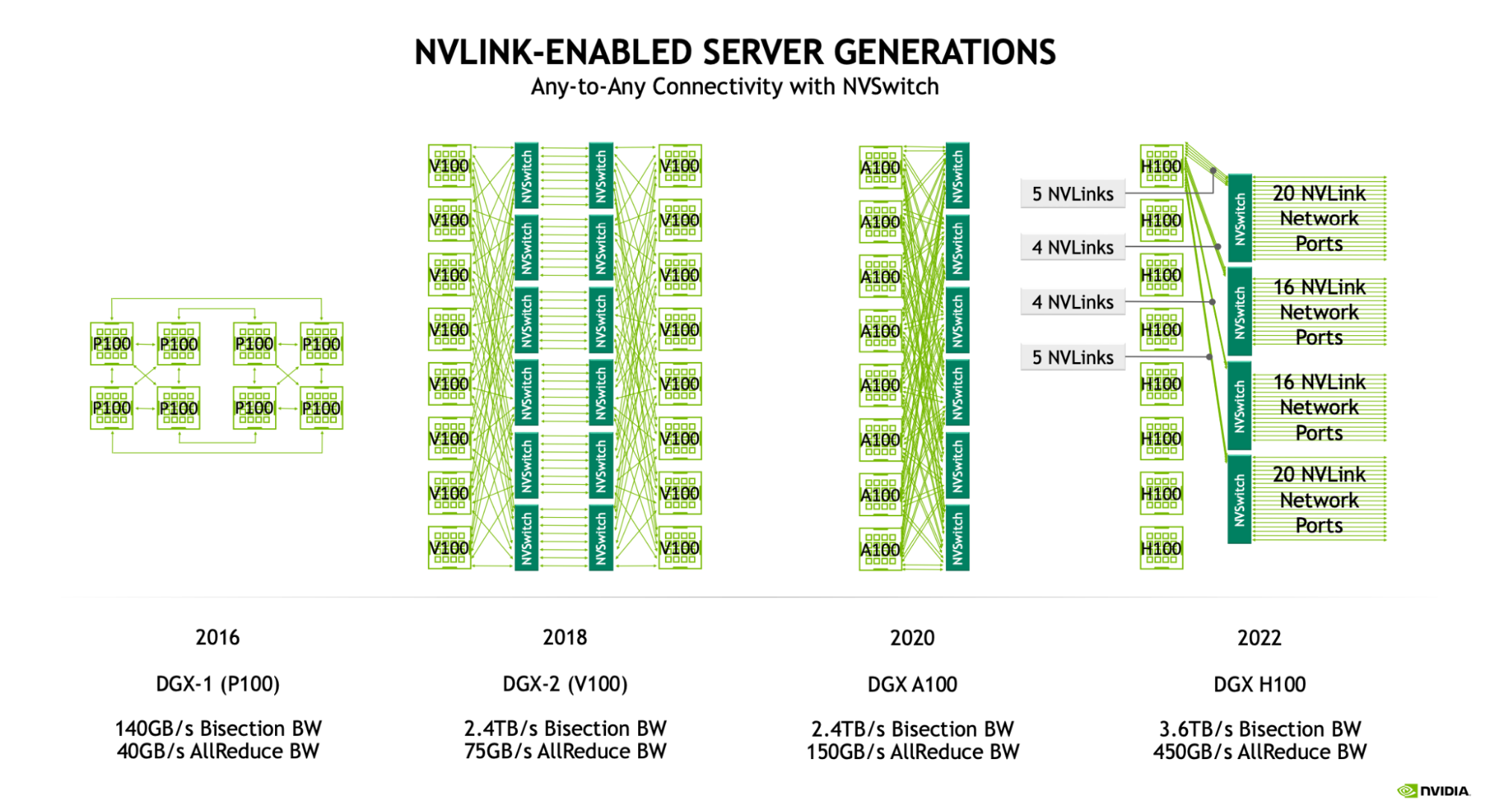
GPU 节点内通过 NVLink 高速互联,由 NVSwitch 交换芯片中转,实现任意两张 GPU 的全带宽直连。
各代 NVLink 参数:
| NVLink 代 | NVSwitch 代 | GPU 代 | 单 link 带宽 | 每 GPU link 数 | GPU 双向带宽 | 节点大小 | NVSwitch/节点 |
|---|---|---|---|---|---|---|---|
| 3.0 | 2.0 | Ampere (A100) | 25 GB/s | 12 | 300 GB/s | 8 | 6 |
| 4.0 | 3.0 | Hopper (H100) | 25 GB/s | 18 | 450 GB/s | 8 | 4 |
| 5.0 | 4.0 | Blackwell (B200) | 50 GB/s | 18 | 900 GB/s | 8/72 | 2/18 |
H100 的 NVLink 连接模式:每张 GPU 有 18 条 NVLink 4.0 连接到 4 个 NVSwitch(按 5+4+4+5 模式分配),每条链路 25 GB/s 全双工。
💡 Pop Quiz:H100 节点带宽
H100 节点有 4 个 NVSwitch,每个有 64 个 NVLink 端口。计算节点总带宽。为什么实际带宽受限于 GPU 而非交换机?
点击查看答案
交换机级别:
4 × 64 × 25 GB/s = 6.4 TB/sGPU 级别:
8 × 450 GB/s = 3.6 TB/sGPU 是瓶颈(3.6 < 6.4),所以节点峰值带宽 = 3.6 TB/s。交换机有余量。
Bisection bandwidth(二分带宽)= 任意等分两半后跨越的带宽 =
8 × 450 = 3.6 TB/s(NVIDIA 官方报告值)。
节点间:InfiniBand Fat Tree
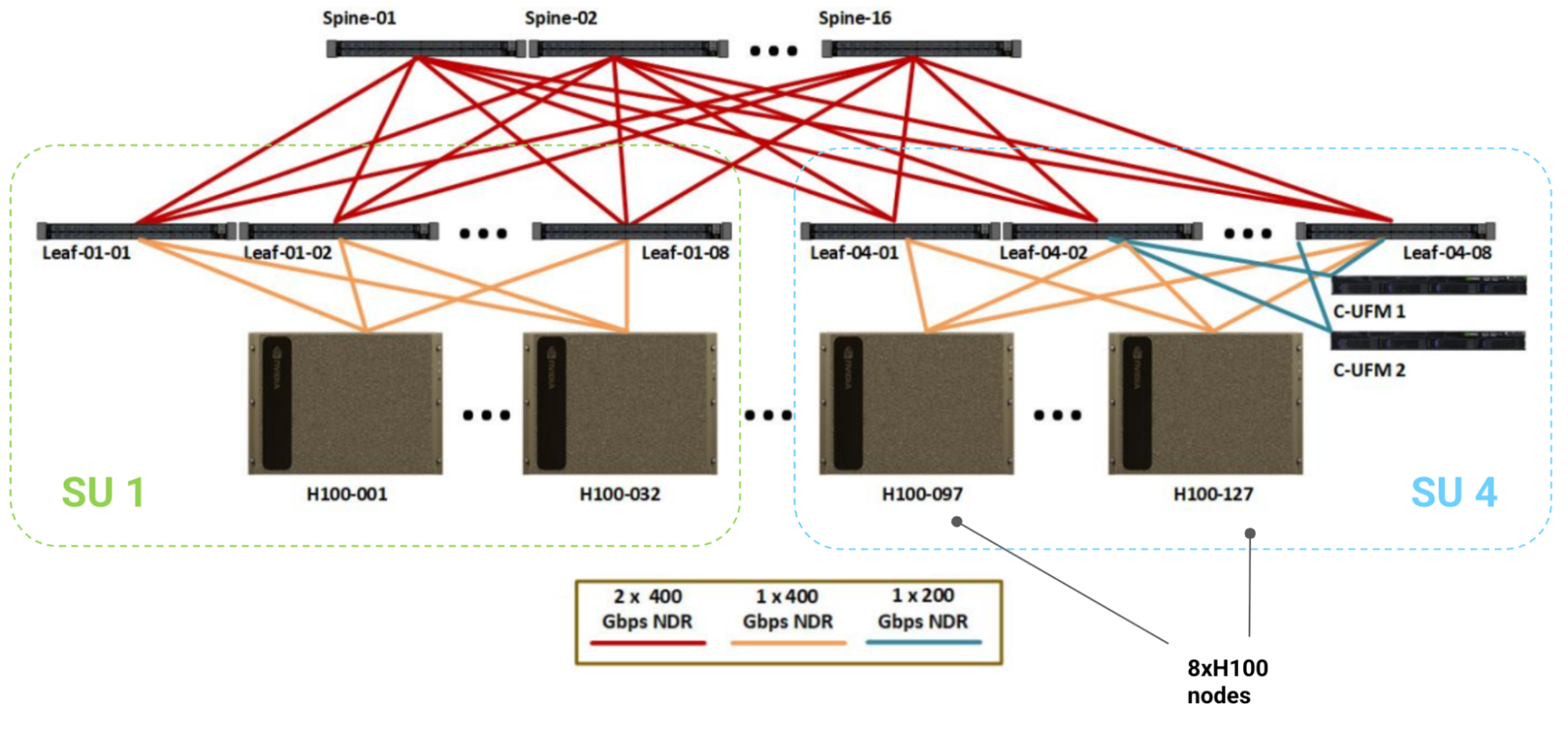
跨节点通信走 InfiniBand(IB)网络,拓扑为 Fat Tree(胖树):
DGX H100 SuperPod(1024 GPU)架构:
Spine Level: 16 个 IB 交换机
↕ 2×400Gbps IB/SU
Leaf Level (SU): 4 个 SU × 8 个 IB 交换机/SU
↕ 1×400Gbps IB/node
Node Level: 128 个节点 × 8 GPU/节点 = 1024 GPU
↕ NVLink 4.0
GPU Level: 8 GPU 全互联(450GB/s 双向/GPU)
Scalable Unit (SU):32 个节点(256 GPU),配 8 个 leaf IB 交换机。
各层级带宽总结:
| 层级 | GPU 数 | 每 GPU 集合通信带宽 | Fat Tree 带宽 |
|---|---|---|---|
| 节点 (NVLink) | 8 | 450 GB/s | 450 GB/s |
| Leaf (SU) | 256 | 50 GB/s | 400 GB/s |
| Spine | 1024 | 50 GB/s | 400 GB/s |
Fat Tree 关键性质:在所有层级保持 full bisection bandwidth(完全二分带宽)。无论如何把节点分成两半,跨越的总带宽恒定 = 400 GB/s/node。这意味着 AllReduce 在理论上不随集群大小增长而变慢。
GB200 NVL72:更大的 NVLink 域
Blackwell 引入了 72 GPU NVLink 域(GB200 NVL72):
- 18 个 NVSwitch 连接 72 张 GPU,每 GPU 900 GB/s 双向
- 节点出口带宽大幅增加:
4 × 18 × 400 / 8 = 3.6 TB/s(vs H100 的 400 GB/s)
| 节点类型 | GPU/节点 | GPU 出口带宽 | 节点出口带宽 |
|---|---|---|---|
| H100 | 8 | 450 GB/s | 400 GB/s |
| B200 | 8 | 900 GB/s | 400 GB/s |
| GB200 NVL72 | 72 | 900 GB/s | 3,600 GB/s |
GB200 NVL72 的节点出口带宽是 H100 的 9×,这使得跨节点集合通信不再是瓶颈。
📋 背景知识:NVLink vs ICI 的本质差异
特性 NVLink (GPU) ICI (TPU) 拓扑 全互联(交换机) 最近邻(Torus) 节点内带宽 450-900 GB/s/GPU 180-540 GB/s/chip 跨节点带宽 400 GB/s/node (IB) 90 GB/s/axis (ICI) 扩展性 靠增加交换层级 靠 torus 自然扩展 成本 高(NVSwitch 很贵) 低(直接连接) 最大规模 需要更多交换层级 8,960 chip(v5p pod) 关键直觉:NVLink 让节点内所有 GPU”像一张大卡”(全互联),但跨节点立刻带宽骤降(450→50 GB/s per GPU)。TPU 的每芯片带宽更均匀,但总量更低。
4.4 DCN(Data Center Network)
无论 GPU 还是 TPU,超出一个 Pod/Superpod 的通信走数据中心网络(DCN):
- TPU DCN 带宽:~6 GB/s/chip(TPU v5p)
- 这比 ICI 慢约 15×,比 HBM 带宽慢约 450×
DCN 用于:
- Multi-slice 训练:多个 ICI-connected 的 TPU slice 通过 DCN 连接
- 跨 Pod 的 Data Parallelism
4.5 GPU 上的集合通信
节点内集合通信
GPU 节点内的 AllGather/ReduceScatter 和 TPU 完全相同(环形算法),成本为:
\[T_{\text{AG or RS}} = \frac{\text{bytes} \times (N-1)}{N \times W_{\text{GPU egress}}} \to \frac{\text{bytes}}{W_{\text{GPU egress}}}\]H100 上约 = bytes / 450e9,B200 上约 = bytes / 900e9。AllReduce = 2× 此值。
AllToAll 在 GPU 上更高效:GPU 节点内全互联(点对点),不需要像 TPU 那样沿环传递。成本为:
\[T_{\text{AllToAll}} = \frac{B \times (N-1)}{N^2 \times W_{\text{GPU egress}}} \approx \frac{B}{N \times W_{\text{GPU egress}}}\]单节点 H100 上 = B / (8 × 450e9),比 TPU 的 B / (4 × W_ici) 快约 2×。
💡 Pop Quiz:节点内 AllGather 时间
在 8×H100 节点(450 GB/s 全双工带宽)上 AllGather
bf16[B_X, F],B=1024, F=16384。需要多久?点击查看答案
总数据 =
2 × 1024 × 16384 = 33.6 MB精确计算:$T = 33.6\text{e}6 \times 7 / (8 \times 450\text{e}9) = 65\mu s$
近似:$T \approx 33.6\text{e}6 / 450\text{e}9 = 75\mu s$
稀疏/不规则 AllToAll(Ragged AllToAll):MoE(Mixture of Experts)模型中,每个 token 只路由到 $k$ 个专家(总共 $E$ 个),因此 AllToAll 的数据量可以按 $k/N$ 的比例减少:
\[T_{\text{Ragged AllToAll}} \approx \frac{B \times \min(k/N, 1)}{N \times W_{\text{GPU egress}}}\]例如,$k=8, N=8$ 时退化为全密度 AllToAll;$k=2, N=8$ 时只需传输 1/4 的数据。对于 token 独立随机路由的情况,实际非零条目略少于 $k/N$(类似”生日问题”)。
💡 Pop Quiz:稀疏 AllToAll 时间
在 8×H100 节点上执行
AllToAll_X->k(bf16[B_X, N]),B=4096, N=8192。如果只有 4/8 的条目非零,时间是多少?点击查看答案
密集情况:$T = B \times (N-1) / (W \times N^2) \approx B / (W \times N)$
其中 $B = 2 \times 4096 \times 8192 = 67\text{ MB}$
密集:$T = 67\text{e}6 / (450\text{e}9 \times 8) = 18.6\mu s$
稀疏(k/N = 1/2):$T \approx 18.6 / 2 = 9.3\mu s$
SHARP:网络内归约
自 Hopper 起,NVSwitch 和 IB 交换机支持 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)— 交换机自身可以做归约操作:
无 SHARP:GPU → 交换机 → GPU → 交换机 → GPU(数据过 GPU 两次)
有 SHARP:GPU → 交换机(在交换机中归约)→ GPU(数据过 GPU 一次)
理论上 AllReduce 成本减半(从 2B/W 到 B/W)。实际仅提升约 30%(从 ~370 GB/s 到 ~480 GB/s)。
跨节点集合通信
跨节点时,集合通信成本由 节点出口带宽 决定:
\[T_{\text{AG or RS}} = \frac{\text{bytes}}{W_{\text{node egress}}} \underset{H100}{=} \frac{\text{bytes}}{400\text{e}9}\]因为 Fat Tree 保证 full bisection bandwidth,所以无论集群多大,这个公式都适用。
更精确的推导:我们可以在树的每一层做环形归约,各层的成本可以重叠。总成本为:
\[T_{\text{AG or RS}} = \text{bytes} \times \max_{\text{depth } i}\left[\frac{D_i - 1}{D_i \times W_{\text{link } i}}\right]\]其中 $D_i$ 是第 $i$ 层的度数(子节点数),$W_{\text{link } i}$ 是该层链路带宽。以 H100 SuperPod 为例:
- 节点层:$D=8$, $W=450\text{e}9$ → 带宽 = $450 \times 8/7 = 514$ GB/s
- Leaf 层:$D=32$, $W=400\text{e}9$ → 带宽 = $400 \times 32/31 = 413$ GB/s
- Spine 层:$D=4$, $W=12.8\text{e}12$ → 带宽 = $12.8\text{e}12 \times 4/3 = 17.1$ TB/s
整体带宽 = $\min(514, 413, 17100) = 413$ GB/s,瓶颈在 Leaf 层。实际中 450 和 400 GB/s 足够作为近似值。
跨节点 AllToAll:AllToAll 跨节点时不能像 AllReduce 那样利用树形层级化归约。如果 N-way AllToAll 跨 $M = N/8$ 个节点,成本为:
\[T_{\text{AllToAll}} = \frac{B \times (M-1)}{M^2 \times W_{\text{node egress}}} \approx \frac{B}{M \times W_{\text{node egress}}}\]等效每 GPU 带宽仅 50 GB/s(而非 400 GB/s)。从单节点 $B/(8 \times 450\text{e}9)$ 到 2 节点 $B/(2 \times 400\text{e}9)$,退化超过 4×。这是 MoE 模型跨节点 EP 的主要瓶颈。
多轴分片的影响:如果沿内轴 Y 分片了数据,外轴 X 的 AllReduce 成本会降低。但只有当 Y 跨越多个节点时才有效:
\[T_{\text{node}} = \frac{\text{bytes}}{W_{\text{GPU egress}} \times \min(Y, D_{\text{node}})}\] \[T_{\text{scale-out}} = \frac{\text{bytes} \times D_{\text{node}}}{W_{\text{node egress}} \times \max(D_{\text{node}}, Y)}\] \[T_{\text{total}} = \max(T_{\text{node}},\ T_{\text{scale-out}})\]关键洞察:如果做 8-way TP($Y=8=D_{\text{node}}$),节点内成本降低 8×,但整体成本不变——因为 scale-out 仍是瓶颈。只有 $Y > D_{\text{node}}$(跨越多个节点)才能真正提速。
💡 Pop Quiz:多轴分片 AllGather
在一个 SU(256 GPU)上执行
AllGather_X(bf16[D_X, F_Y]),其中 Y 是内轴。当 Y=8 和 Y=32 时,通信时间分别是多少?D=8192, F=32768。点击查看答案
总数据 = $2 \times 8192 \times 32768 = 512\text{ MB}$
Y=8(节点内 TP):$T_{\text{node}} = 512\text{e}6 / (450\text{e}9 \times 8) = 142\mu s$,$T_{\text{scale-out}} = 512\text{e}6 \times 8 / (400\text{e}9 \times 8) = 1.28\text{ms}$。瓶颈在 scale-out → $T = 1.28\text{ms}$
Y=32(跨 4 节点 TP):$T_{\text{node}} = 512\text{e}6 / (450\text{e}9 \times 8) = 142\mu s$,$T_{\text{scale-out}} = 512\text{e}6 \times 8 / (400\text{e}9 \times 32) = 320\mu s$。瓶颈仍在 scale-out 但降低 4× → $T = 320\mu s$
所以跨 4 节点的分片比单节点分片快 4×!
经验测量:实际 AllReduce 带宽在 H100 上很难超过 370 GB/s(理论 450 GB/s),且需要 ~10 MB 以上的消息才能接近峰值。相比之下,TPU 在 ~600 KB 就能达到 95% 峰值带宽。这意味着 GPU 上小消息的集合通信效率更低。
这是一个实际问题:例如 LLaMA-3 70B 的 MLP 权重 bf16[8192, 28672],8-way 分片后每块 bf16[8192, 3584] = 58 MB,实测只能达到约 150 GB/s(理论 450 GB/s 的 33%)。
🛠️ 实践:NCCL
GPU 的集合通信由 NCCL(NVIDIA Collective Communication Library,读作”nickel”)实现。
- 开源:https://github.com/NVIDIA/nccl
- 自动选择最优算法(ring vs tree vs direct)根据消息大小和拓扑
- 支持 NVLink + IB + RoCE
- 在 Megatron 和 SGLang 中被底层使用
4.6 带宽层级全景
计算单元内部(VMEM → MXU) ~20-40 TB/s
↓ (~5-20×)
HBM → 计算单元 ~1-9 TB/s
↓ (~3-10×)
节点内互联 (NVLink/ICI) ~90-900 GB/s
↓ (~2-15×)
节点间互联 (InfiniBand/DCN) ~6-50 GB/s
↓ (~3-10×)
PCIe (CPU ↔ GPU) ~50 GB/s
核心原则:通信密集的操作(如 Tensor Parallelism)应该放在高带宽的互联上(节点内),通信稀疏的操作(如 Data Parallelism)可以放在低带宽的互联上(跨节点)。
🛠️ 实践:Megatron
Megatron 的并行策略映射严格遵循这个带宽层级:
节点内 8 卡(NVLink ~900 GB/s) → Tensor Parallelism (TP=8) 跨节点(InfiniBand ~50 GB/s) → Pipeline Parallelism (PP) 全集群 → Data Parallelism (DP)配置示例(128 张 H100,16 节点):
--tensor-model-parallel-size 8 # 节点内 --pipeline-model-parallel-size 4 # 跨 4 个节点 --data-parallel-size 4 # 剩余 = 128/(8×4) = 4
--tensor-model-parallel-size一般不超过单节点的 GPU 数,因为跨节点做 TP 的通信开销太大。
4.7 拓扑对并行策略的影响
不同拓扑适合不同的并行方式:
| 并行策略 | 通信模式 | 适合的互联 |
|---|---|---|
| Data Parallelism | AllReduce 梯度(低频、大量数据) | DCN / InfiniBand |
| Tensor Parallelism | AllReduce/AllGather(高频、中量数据) | NVLink / ICI |
| Pipeline Parallelism | 点对点传输(中频、少量数据) | InfiniBand / ICI |
| Expert Parallelism | AllToAll(高频、中量数据) | NVLink / ICI |
4.8 GPU 上的 LLM 并行 Roofline 分析
理解了互联带宽后,我们可以分析在什么条件下通信时间超过计算时间(通信瓶颈),从而决定并行策略的选择。以 MLP 层为分析对象:
\[\text{MLP}(x) \equiv x[B, D] \times_D W_{\text{in}}[D, F] \times_F W_{\text{out}}[F, D]\]其中 $B$ 是全局 batch size(单位是 token 数,即 batch_size × sequence_length)。
用 $W_{\text{collective}}$ 表示当前层级的集合通信带宽(节点内 = GPU 出口带宽,跨节点 = 节点出口带宽),$C$ 表示单 GPU 的 FLOPs/s。
Data Parallelism Roofline
DP / ZeRO 需要在反向传播中做 AllReduce 或 ReduceScatter + AllGather。对于 X-way DP,每层:
\[T_{\text{math}} = \frac{2 \times 2 \times 2 \times BDF}{X \times C}, \quad T_{\text{comms}} = \frac{2 \times 2 \times 2 \times DF}{W_{\text{collective}}}\]Compute-bound 条件:$B/X > C / W_{\text{collective}}$
| 场景 | $C / W_{\text{collective}}$ | 每 GPU 最小 token batch |
|---|---|---|
| H100 节点内 | $990\text{e}12 / 450\text{e}9$ | 2200 |
| H100 跨 SU | $990\text{e}12 / 400\text{e}9$ | 2475 |
| B200 跨 SU | $2250\text{e}12 / 400\text{e}9$ | 5625 |
这比 TPU 的 ~850 高得多。例如 LLaMA-3 在 16000 张 H100 上训练,需要全局 batch > 40M tokens(实际用 16M)。
MoE 模型的 DP 更难:MoE 有 $E$ 个专家但每 token 只激活 $k$ 个,导致权重通信量放大 $E/k$ 倍:
\[\frac{B}{X} > \frac{E}{k} \times \frac{C}{W_{\text{collective}}}\]例如 $k=4, E=128$ 时,跨节点每 GPU 最小 batch = $32 \times 2475 = 79,200$ tokens!
小规模 DP 的优势:2-way DP 享受 $(X-1)/X = 1/2$ 的通信折扣,临界 batch size 减半到 ~1237。这也是 DeepSeek V3 使用 2-way DP 的原因之一。
Tensor Parallelism Roofline
TP 需要在前向传播中做 AllGather + ReduceScatter(激活值)。Y-way TP 每层:
\[T_{\text{math}} = \frac{2 \times 2 \times BDF}{Y \times C}, \quad T_{\text{comms}} = \frac{2 \times 2 \times BD}{W_{\text{collective}}}\]Compute-bound 条件:
\[Y < \frac{F \times W_{\text{collective}}}{C}\]- 节点内:$Y < F / 2200$。LLaMA-3($F=28672$)→ 最多 ~13-way → 实际用 8-way(节点大小)
- 跨 2 节点:$F > 2475 \times (Y-8)$,LLaMA-3 可到 ~16-way(因 2 节点有 2× 带宽加成)
🛠️ 实践:Megatron TP 配置
Megatron 中
--tensor-model-parallel-size一般设为 8(节点内),最多 16(跨 2 节点):# 标准配置:TP=8, 节点内 --tensor-model-parallel-size 8 # 激进配置:TP=16, 需要 F 足够大(如 28672) --tensor-model-parallel-size 16跨 2 节点 TP 只有在 F 很大时才值得,否则通信成本超过收益。
Expert Parallelism Roofline
EP 需要 2× AllToAll 传输激活值。Z-way EP 跨多节点时:
\[T_{\text{math}} = \frac{4 \times B \times k \times D \times F}{Z \times C}\] \[T_{\text{comms}} = \frac{4 \times B \times D \times (Z-8)}{W \times Z} \times \min\left(\frac{8k}{Z}, 1\right)\]这产生两个可行区域:
- 小规模 EP(~2 节点):$k > Z/8$,即激活专家数多于节点数,$F$ 可以较小
- 大规模 EP:$F > 8 \times C/W_{\text{node}}$,即 $F$ 足够大时可以做到 E-way EP
实践中两种都常见:DeepSeek V3 的 $F$ 较小,用 64-way EP 跨 8 节点(受限的跨节点 EP);其他模型如果 $F$ 很大,可以做更多的跨节点 EP。
Pipeline Parallelism 通信成本
PP 的通信量极小,因为只在 stage 边界传递少量激活值:
\[T_{\text{per-layer comms}} \approx 1.5 \times \frac{2BD}{W \times N_{\text{layers}}}\]分母中有 $N_{\text{layers}}$(通常 40-80),使通信成本微不足道。但 PP 的代价不在通信:
- 代码复杂度:零气泡(zero-bubble)调度需要复杂的前/反向交错
- 与 FSDP 冲突:ZeRO-3 在每个 microbatch 都要 AllGather 权重,而 PP 将 batch 切成多个 microbatch → AllGather 无法摊销。且梯度 AllReduce 必须等最后一个 microbatch 完成 → 产生无法 overlap 的通信
- 流水线气泡:朴素调度中各 stage 有大量空闲时间
📋 背景知识:流水线气泡
Stage 0: [F0][F1] [B1][B0][G] Stage 1: [F0][F1][B1][B0] [G] ↑ 这些空白就是"气泡"(浪费的计算)F = Forward,B = Backward,G = Gradient AllReduce
零气泡技术(1F1B、Interleaved)通过交错安排 F/B 步骤来减少气泡,但增加了实现复杂度。
实战案例
DeepSeek V3(2048 × H800):
- 64-way Expert Parallelism(跨 8 节点)
- 16-way Pipeline Parallelism
- 2-way ZeRO-1 Data Parallelism
- Batch = 4096 × 15360 = 62.9M tokens,每 GPU 约 30k tokens
- 模型高度稀疏(k=8, E=256),需要大 batch size
LLaMA-3(16k × H100):
- 8-way Tensor Parallelism(节点内)
- 16-way Pipeline Parallelism
- 128-way ZeRO-1 Data Parallelism
- Batch = 16M tokens,每 GPU ~1k tokens
- 密集模型,16-way PP 将 DP AllReduce 成本降低 16×
🛠️ 实践:Megatron 完整并行配置
以 4096 张 H100(512 节点)训练 LLaMA-3 70B 为例:
# 8-way TP × 16-way PP × 32-way DP = 4096 GPU --tensor-model-parallel-size 8 # 节点内 NVLink --pipeline-model-parallel-size 16 # 跨 16 节点 --data-parallel-size 32 # 全集群 --use-distributed-optimizer # ZeRO-1 --sequence-parallel # 序列并行(减少激活内存)为什么不用 ZeRO-3?因为 PP 的 microbatch 会让 ZeRO-3 在每个 microbatch 都做 AllGather,通信量爆炸。ZeRO-1 只分片优化器状态,不需要额外 AllGather。
GPU 并行策略总结
| 策略 | 节点内临界条件 | 跨节点临界条件 | 典型用法 |
|---|---|---|---|
| DP/FSDP | B/GPU > 2200 | B/GPU > 2475 | 全集群 |
| TP | Y < F/2200 | Y < F/2475 | 1-2 节点 |
| EP | F > 8α 时可大规模 | 受限于 AllToAll | 1-8 节点 |
| PP | 通信基本免费 | 通信基本免费 | 跨多节点 |
高层策略配方:
- 小型密集模型:FSDP 直接分片,batch 足够大即可
- 大型密集模型:1-2 节点 TP + 多节点 PP + 全集群 DP
- MoE 模型:EP 替代或补充 TP + PP + DP
4.9 Appendix:NVLink 交换机与逐层带宽瓶颈
NVLink 4 交换机内部
NVLink 4 Switch 有 64 个 NVLink4 端口(每端口使用 2 条物理 lane),内部有大型 crossbar 负责端口间的包交换。与 TPU 使用的光交换机(镜面可动态重配)不同,NVLink Switch 是固定拓扑。
逐层带宽瓶颈分析
在 H100 DGX SuperPod 中,每一层都可能成为瓶颈,取决于链路带宽和交换机带宽的较小值:
| 层级 | 交换机数/单元 | 交换机类型 | 交换机带宽 (TB/s) | 链路带宽 (TB/s) | 每 GPU 集合带宽 |
|---|---|---|---|---|---|
| 节点 | 4 | NVL | 6.4 | 3.6 | 450 GB/s |
| Leaf (SU) | 8 | IB | 12.8 | 12.8 | 50 GB/s |
| Spine | 16 | IB | 25.6 | 51.2 | 25 GB/s |
- 节点层:GPU 是瓶颈(3.6 < 6.4 TB/s),交换机有余量
- Leaf 层:链路和交换机恰好匹配(12.8 TB/s)
- Spine 层:交换机是瓶颈(25.6 < 51.2 TB/s)
GPU vs TPU 经验带宽对比
| 特性 | GPU (H100) | TPU (v5p) |
|---|---|---|
| 峰值带宽 | 450 GB/s | 540 GB/s (3轴总和) |
| 实测峰值 | ~370 GB/s | ~95% 理论值 |
| 达到峰值所需消息大小 | ~10 MB | ~600 KB |
| 小消息效率 | 差(延迟主导) | 好(低延迟直连) |
| AllToAll 效率 | 高(全互联) | 低(环形传递) |
GPU 在大消息上表现接近理论值,但在小消息上效率远低于 TPU。这是因为 NCCL 的 ring/tree 算法有固定的启动开销(kernel launch、同步等),而 TPU 的 ICI 直连延迟更低。
Grace Hopper 与 NVLink C2C
NVIDIA 还推出了 GH200(1 H200 + 1 Grace CPU)和 GB200(2 B200 + 1 Grace CPU)系统。Grace CPU 通过 NVLink C2C 连接到 GPU,带宽与 NVLink 相同。这意味着将参数 offload 到 CPU 内存的带宽等于 GPU 间通信带宽,有利于推理时的大模型部署。
4.10 Worked Problems(习题与详解)
Problem 1:Fat Tree 二分带宽验证
题目:使用上面的 DGX H100 SuperPod 架构,逐层验证 full bisection bandwidth = 400 GB/s per node。
点击查看答案
Node → Leaf:每节点 8×400Gbps IB = 8 × 400 / 8 = 400 GB/s 到 leaf。每 SU 的 8 个 leaf 交换机各有 64 端口 × 400Gbps,但只用 32 端口 ingress → 32 × 50 = 1.6 TB/s per switch。32 节点的 SU 总带宽 = 8 × 1.6 TB/s,per node = 400 GB/s ✓
Leaf → Spine:每 SU 到 spine 有 8 × 16 × 2 × 400Gbps / 8 = 12.8 TB/s。32 节点 → per node = 400 GB/s ✓
Spine:16 个 spine 交换机各 3.2 TB/s。总 = 51.2 TB/s / 128 nodes = 400 GB/s ✓
结论:每一层的链路带宽和交换机容量恰好匹配,保证了恒定的 400 GB/s/node 二分带宽。
Problem 2:GPU AllGather 时间
题目:在 8×H100 节点(450 GB/s 双向/GPU)上 AllGather bf16[D_X, F],D=4096, F=65536。需要多久?
点击查看答案
总数据 = 2 × 4096 × 65536 = 512 MB
实测约 1.5ms(因达不到理论峰值带宽)。
Problem 3:2 节点 AllGather 优势
题目:精确计算 B bytes 在 2 个 H100 节点(16 GPU)上 AllGather 的成本。为什么 2-way DP 特别常见?
点击查看答案
节点内:$T_{\text{node}} = B \times 7 / (8 \times 450\text{e}9) = B / 514\text{e}9$
跨节点(2 nodes):$T_{\text{cross}} = B \times (2-1) / (2 \times 400\text{e}9) = B / 800\text{e}9$
$T_{\text{node}} > T_{\text{cross}}$,所以节点内通信是瓶颈,跨节点基本免费!
这就是 DeepSeek V3 使用 2-way Data Parallelism 的原因 — 加一个节点的 DP 几乎不增加通信开销。
Problem 4:扩展到 2048/4096 GPU
题目:如果想从 1024 GPU 的 SuperPod 扩展到 2048 和 4096 GPU,网络拓扑如何修改?
点击查看答案
2048 GPU:保持 SU 结构(32 nodes/SU),增加到 8 个 SU。Spine 交换机数翻倍到 32 个。每 leaf 到每 spine 从 2×400Gbps 减少到 1×400Gbps 以节省端口。
4096 GPU:64 端口的 spine 交换机端口用尽,需要增加第三层交换(core switches)。NVIDIA 方案:128 个 spine + 64 个 core 交换机。可以验证仍满足 full bisection bandwidth。
Problem 5:GPU AllToAll vs TPU AllToAll
题目:在 8×H100 节点(450 GB/s/GPU)上执行 AllToAll bf16[B_X, N],B=4096, N=8192。对比 TPU v5p 同规模(8 chips, 3 axis)上的 AllToAll 时间。
点击查看答案
数据量 = 2 × 4096 × 8192 = 67 MB
GPU(全互联):$T = B \times (N-1) / (N^2 \times W) = 67\text{e}6 / (8 \times 450\text{e}9) = 18.6\mu s$
TPU(双向环):$T = B / (4 \times W_{\text{ici}}) = 67\text{e}6 / (4 \times 9\text{e}10) = 186\mu s$
GPU 快约 10×!这是因为 GPU 全互联可以直接点对点传输,而 TPU 需要沿环传递。这也是 MoE 模型在 GPU 上通常比 TPU 更高效的原因之一。
Problem 6:SU AllGather 交换机流量分析
题目:在一个 SU(32 节点,M=32)中做 AllGather(B bytes),精确计算 leaf 交换机的 ingress 和 egress 字节数。哪个方向是瓶颈?
点击查看答案
分步分析:
- 每个 GPU 发送 $B / (MN)$ 字节到 leaf 交换机 → 总 ingress = $N \times B/(MN) = B/M$
- Leaf 向 spine 发送 $B/M$ 字节
- Leaf 从 spine 接收 $B \times (M-1)/M$ 字节
- Leaf 向每个 GPU 发送 $B - B/(MN)$ 字节,共 $N$ 个 GPU → egress = $N \times (B - B/(MN)) = NB - B/M$
总计:ingress = $B$,egress = $NB$
GPU 的 egress 是瓶颈:$T = NB / W_{\text{node}} = B / 450\text{e}9$(和节点内 AllGather 一致)。
Problem 7:单节点 SHARP AllReduce 字节分析
题目:在 8×H100 节点中使用 SHARP 做 AllReduce(B bytes),精确计算 NVSwitch 的 ingress 和 egress 总量。验证总成本为 $B / W_{\text{GPU egress}}$。
点击查看答案
SHARP AllReduce 的 4 个步骤:
- 每 GPU 发送 $B \times (N-1)/N$ 字节 → 交换机 ingress = $N \times B(N-1)/N = B(N-1)$
- 交换机做部分归约,返回 $B/N$ 给每 GPU → egress = $N \times B/N = B$
- GPU 本地完成归约后发回 $B/N$ → ingress = $N \times B/N = B$
- 交换机广播完整结果 → egress = $N \times B(N-1)/N = B(N-1)$
总 ingress = $B(N-1) + B = BN$,总 egress = $B + B(N-1) = BN$
每 GPU 总发送量 = $B(N-1)/N + B/N = B$ → $T = B / W_{\text{GPU egress}}$ ✓
与无 SHARP 的 $2B / W$ 相比,理论上快 2×。实际仅快 ~30%。
Problem 8:跨节点 SHARP AllReduce
题目:对于 bf16[D_X, F_Y] 分片在单节点的 Y 个 GPU 上,计算 AllReduce_X(bf16[D, F_Y] {U_X}) 的成本(使用 SHARP)。Y 增大时成本如何变化?跨多节点时呢?
点击查看答案
数据 $B = 2DF$ 字节,分片后每 GPU 持有 $B/(XY)$ 字节。
SHARP AllReduce 的成本按上一题的推导,每 GPU 总发送 $B/Y$ 字节:
\[T = \frac{NB}{Y \times N \times W_{\text{link}}} = \frac{2DF}{Y \times W_{\text{link}}}\]$Y$ 增大时成本线性下降(每 GPU 持有的数据更少)。
跨多节点时:节点内交换机 egress 时需要发送完整的 $B$ 字节(而非 $B/Y$),因为每个分片必须保持独立。跨节点成本不再随 $Y$ 降低 → 这就是为什么多轴分片只有内轴跨越多节点才有效。
Problem 9:B200 Roofline 变化
题目:B200 DGX SuperPod(非 GB200 NVL72)节点内带宽 900 GB/s,跨节点仍 400 GB/s,bf16 FLOPs 为 2250 TFLOPS。与 H100 相比,DP 和 TP 的 roofline 如何变化?
点击查看答案
节点内:$C/W = 2250\text{e}12 / 900\text{e}9 = 2500$,与 H100 的 2200 接近 → TP roofline 基本不变($Y < F/2500$)
跨节点:$C/W = 2250\text{e}12 / 400\text{e}9 = 5625$,比 H100 的 2475 高 2.3× → DP 更难 compute-bound!
B200 的 FLOPs 翻倍但跨节点带宽不变 → compute-communication gap 加大。这使得跨节点并行更加困难,是 GB200 NVL72(3.6 TB/s 节点出口)被需要的原因。
GB200 NVL72:$C/W_{\text{node}} = 2250\text{e}12 / 3600\text{e}9 = 625$,比 H100 改善 4×!
Problem 10:LLaMA-3 70B 分片设计
题目:训练 LLaMA-3 70B(bf16 + fp32 优化器,$F=28672$,batch=4M tokens),在 4096 张 H100 上:(1) 最少需要多少 GPU 存储权重和优化器?(2) 45% MFU 时训练 15T tokens 需多长时间?(3) 设计最优并行策略。
点击查看答案
(1) 最小 GPU 数:权重 2 字节 + 优化器 8 字节 = 10 字节/参数 → $70\text{e}9 \times 10 = 700\text{ GB}$。每 GPU 80 GB → 至少 9 张,即 2 个节点。
(2) 训练时间:总 FLOPs = $6 \times 70\text{e}9 \times 15\text{e}12 = 6.3\text{e}24$。每 GPU 有效 FLOPs = $990\text{e}12 \times 0.45 = 445.5\text{e}12$。总 = $6.3\text{e}24 / (4096 \times 445.5\text{e}12) = 3.45\text{e}6$ 秒 ≈ 40 天。
(3) 并行策略:
- 纯 TP=8 + DP=512:每 GPU 权重 = $700/8 = 87.5$ GB > 80 GB → 内存不够!
- TP=8 + ZeRO-3 + DP=512:内存没问题。每 GPU batch = $4\text{e}6/4096 = 976$ tokens,低于 DP 临界值 2475(ZeRO-3 需要 AllGather 权重,临界值更高)→ 通信瓶颈!
- TP=8 + PP=16 + DP=32:PP 将模型分成 16 个 stage → 每个 DP 分片跨 128 个 GPU(16 节点)。16-way PP 将 DP AllGather 带宽提升 16× → 等效带宽 $16 \times 400 = 6400$ GB/s → roofline 降为 $990\text{e}12/6400\text{e}9 = 155$ → 每 GPU batch = $4\text{e}6/32 = 125000$ » 155 → compute-bound ✓
最优方案:TP=8 + PP=16 + ZeRO-1 DP=32。
Problem 11:Megatron-LM 配置分析
题目:Megatron-LM 给出以下配置的 MFU 数据(序列长度均为 4096)。分析每种配置的每 GPU token batch size,并判断是否 compute-bound。
| 模型 | GPU 数 | TP | PP | DP | Global BS |
|---|---|---|---|---|---|
| 16B | 192 | 8 | 1 | 24 | 192 |
| 70B | 768 | 8 | 4 | 24 | 384 |
| 314B | 3072 | 8 | 16 | 24 | 1536 |
点击查看答案
每 GPU token batch size = Global BS × seq_len / GPU 数:
- 16B:$192 \times 4096 / 192 = 4096$ tokens/GPU
- 70B:$384 \times 4096 / 768 = 2048$ tokens/GPU
- 314B:$1536 \times 4096 / 3072 = 2048$ tokens/GPU
DP 的 spine 层级临界值约为 2475 tokens/GPU。但因为有 PP 分片:
- 16B(PP=1):直接在 spine 做 DP → 4096 > 2475 ✓ compute-bound
- 70B(PP=4):4-way PP 让 DP 获得 4× 带宽加成 → 等效临界值 = $2475/4 \approx 619$ → 2048 » 619 ✓
- 314B(PP=16):16-way PP → 等效临界值 = $2475/16 \approx 155$ → 2048 » 155 ✓
所有配置均为 compute-bound。PP 的关键贡献在于大幅降低 DP 的临界 batch size。
关键要点
- TPU 用 Torus 拓扑(最近邻直连),便宜但需考虑跳数
- GPU 用交换机拓扑(NVLink + InfiniBand),节点内高带宽,跨节点骤降
- Wraparound 连接条件很重要:无 wraparound 时通信时间翻倍
- Fat Tree 保证 full bisection bandwidth — AllReduce 不随集群规模变慢
- GPU 节点内 AllToAll 比 TPU 快很多(全互联 vs 环形)
- 稀疏 AllToAll(MoE)的成本可按 $k/N$ 比例降低
- 跨节点 AllToAll 不能利用树形层级化,等效带宽仅 50 GB/s/GPU
- SHARP 理论减半 AllReduce 成本,实际仅提升 ~30%
- GPU 实际集合通信带宽显著低于理论值(~370 vs 450 GB/s),且需大消息才能达到
- GB200 NVL72 的 72 GPU 域大幅提升节点出口带宽(9× vs H100)
- 带宽层级:片上缓存 » HBM » 节点内互联 » 节点间互联
- 通信密集的并行策略放在高带宽互联上(TP → 节点内)
- 通信稀疏的并行策略放在低带宽互联上(DP → 跨节点)
- Megatron 的 TP/PP/DP 配置直接映射到这个带宽层级
- DP 在 H100 上需要每 GPU >2475 tokens 才 compute-bound,比 TPU 高约 3×
- MoE 模型的 DP 临界 batch 按 E/k 倍放大
- TP 一般限于 1-2 节点($Y < F/2475$),PP 通信成本极低但代码复杂
- PP 能大幅降低 DP 的临界 batch size(PP=16 → 降低 16×)
- B200 的 FLOPs 翻倍但跨节点带宽不变 → 更需要 GB200 NVL72 的大 NVLink 域