本章目标:承接第 5 章的通信原语,理解当矩阵被分片到多个设备上时,如何高效完成矩阵乘法,以及不同分片方式为什么会触发 AllGather、ReduceScatter 或 AllReduce。
对应原书:Chapter 3 (Sharded Matrices and How to Multiply Them) 下篇:分片矩阵乘法 改写范围:基本对应原书 Chapter 3 的四种 sharded matmul case;Megatron Column/Row Parallel 是帮助落到训练框架的补充。 优先级:⭐⭐⭐ 高 | 建议时间:Day 5, 约 3 小时
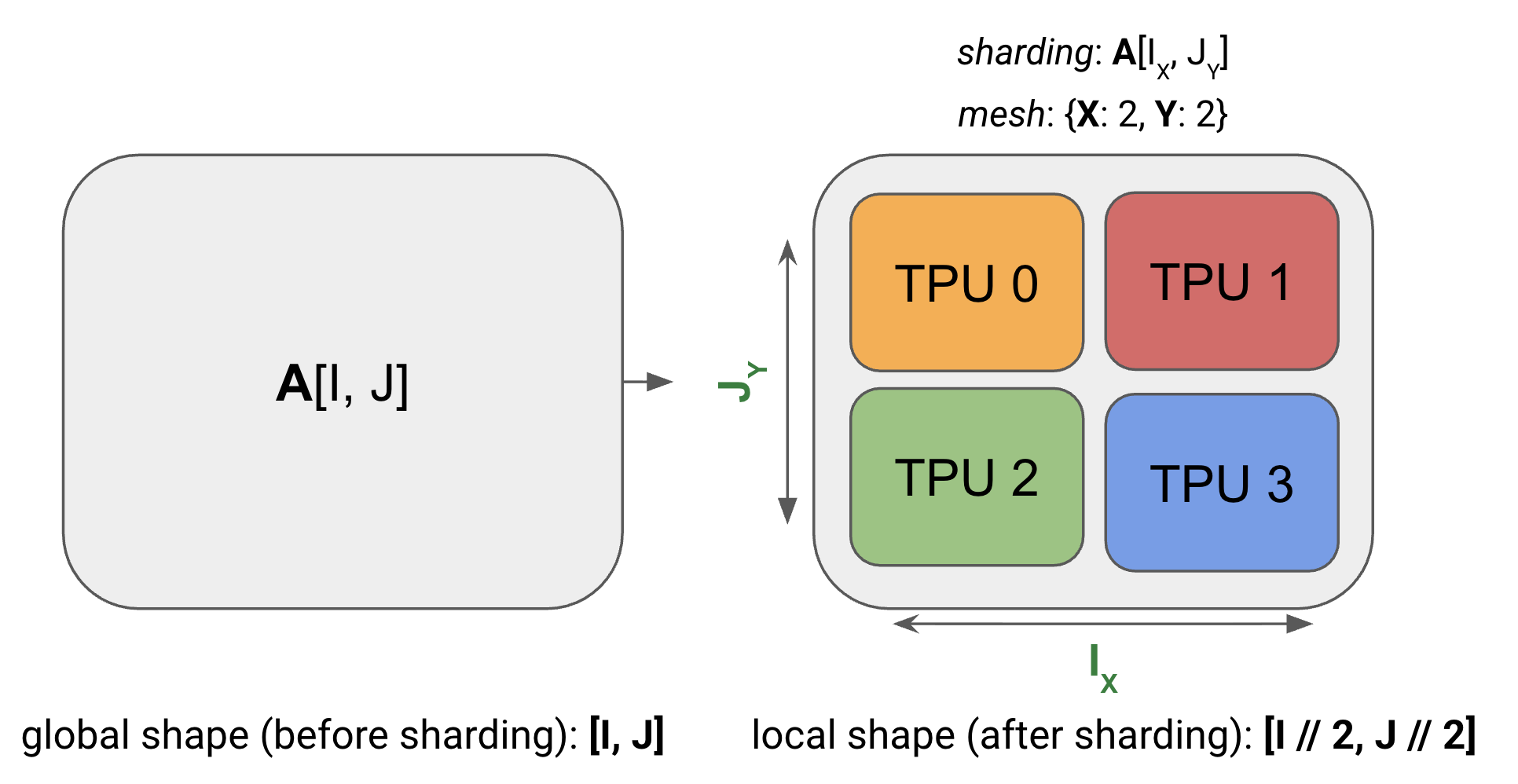
6.1 什么是分片(Sharding)
LLM 的参数太大,无法放在单个设备的 HBM 中。因此必须将矩阵”切”成多份,分布到多个设备上。
阅读建议:如果你对 AllGather / ReduceScatter / AllReduce / AllToAll 的语义和 $V/W$ 成本模型还不熟,先回到 第 5 章:集合通信原语。本章不再重复推导通信原语,而是专注于它们在 matmul sharding 中如何组合。
🔗 与你的联系
你在 CV 中使用 Data Parallel 时,每张卡持有完整的模型参数副本。LLM 太大了,必须把参数本身也切开 — 这就是模型并行(Model Parallelism / Tensor Parallelism)的核心,也是为什么你需要理解分片矩阵乘法。
分片记号
原书使用一种简洁的下标记号:
A[I, J]:未分片的矩阵,形状 I×JA[Iₓ, J]:沿 I 维度在 X 轴的设备上分片A[I, Jᵧ]:沿 J 维度在 Y 轴的设备上分片A[Iₓ, Jᵧ]:同时沿两个维度分片
例如,A[Iₓ, J] 表示矩阵 A 的行被均匀分配到 X 轴上的各设备,每个设备持有 I/Nₓ 行。
多轴分片:A[I_{XY}, J] 表示将 I 维度同时沿 X 和 Y 两个轴分片。如果 Mesh({‘X’: 4, ‘Y’: 2}),则 I 被分成 4×2=8 份。下标顺序决定了在网格中的遍历顺序。
注意:同一个 mesh 维度不能被用两次。A[I_X, J_X] 是非法的 — 一旦 mesh 维度 X 被用来分片 I,它就被”消耗”了,不能再用于 J。
💡 Pop Quiz
数组
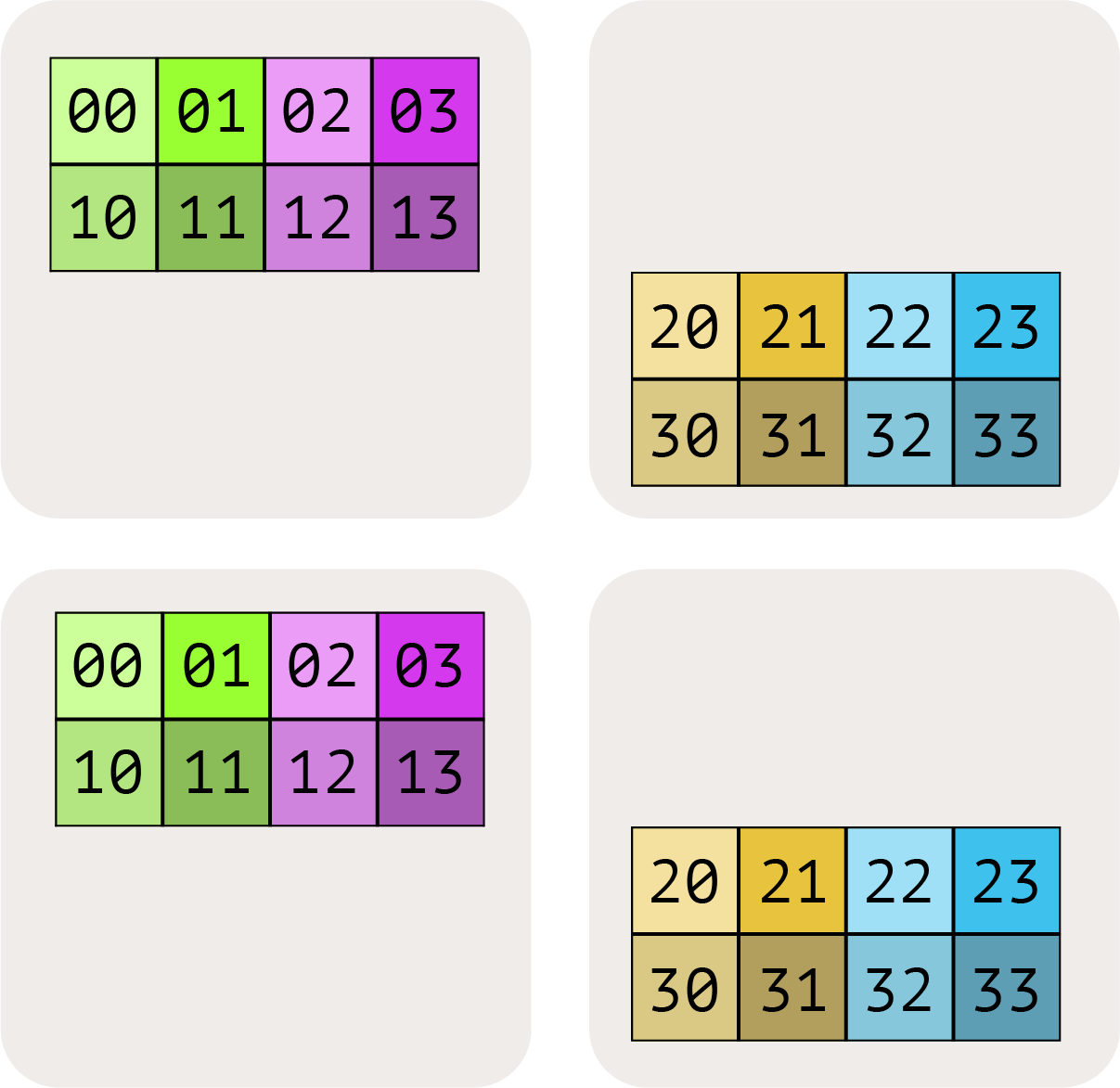
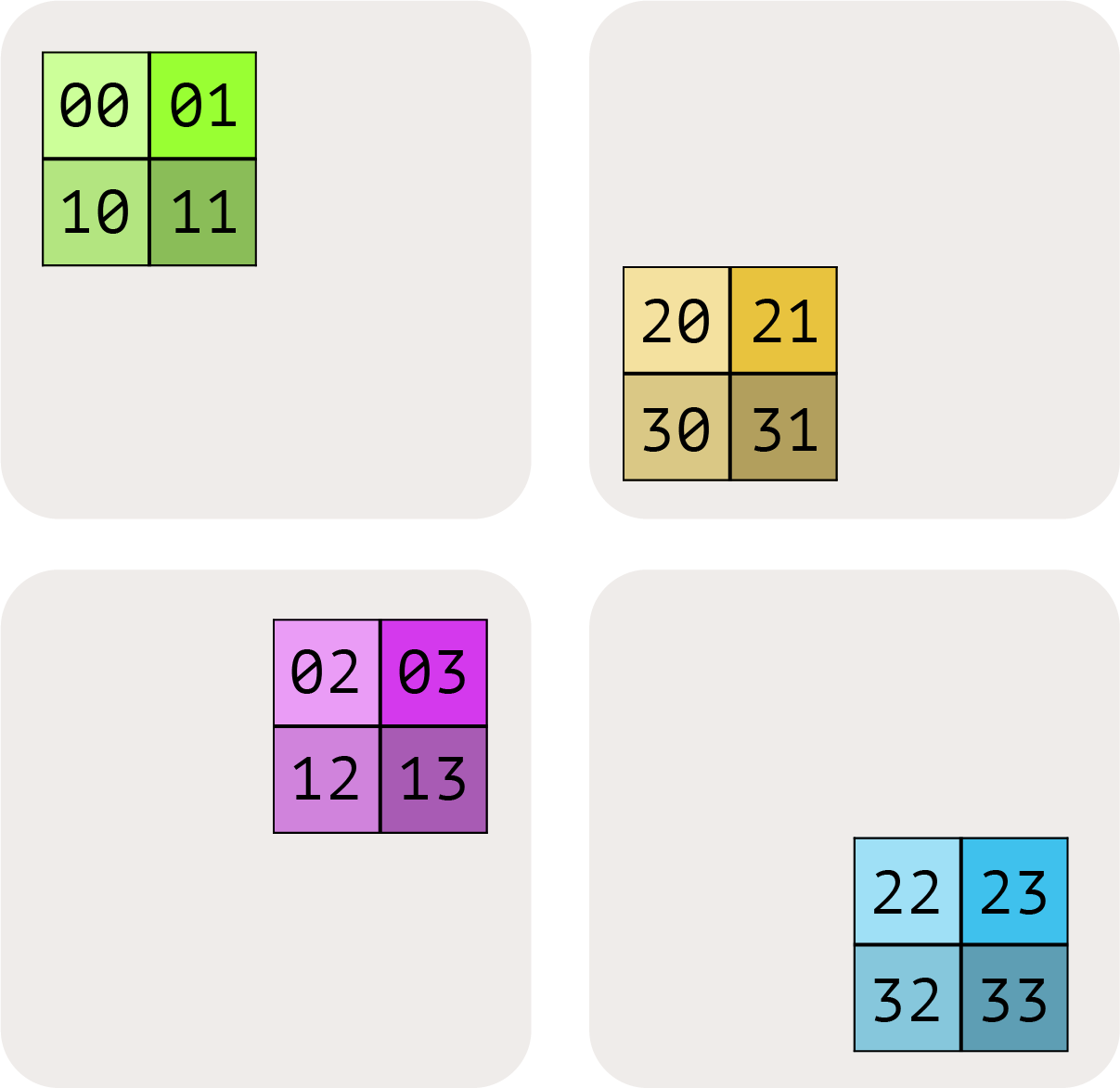
int8[128, 2048],sharding 为 $A[I_{XY}, J]$,Mesh({‘X’: 2, ‘Y’: 8, ‘Z’: 2})(共 32 个设备)。每个设备的内存占用是多少?所有设备上 A 占的总内存是多少?点击查看答案
A 沿 X 和 Y 分片(2×8=16 份),在 Z 上被复制。
每设备的 local shape:
int8[128/(2×8), 2048] = int8[8, 2048],大小 =8 × 2048 = 16,384 bytes ≈ 16KB。因为 Z 方向有 2 份完整复制,总内存 = 原始大小 × Z 复制数 =
128 × 2048 × 2 = 512 KiB。验证:32 设备 × 16,384 bytes = 512 KiB ✓
在 JAX 中描述分片
JAX 使用 NamedSharding 和 PartitionSpec 来描述分片,语法与上面的抽象记号几乎一一对应:
import jax
import jax.numpy as jnp
# 创建 Mesh:将 8 个设备排列为 4×2 网格,轴名为 'X' 和 'Y'
assert len(jax.devices()) == 8
mesh = jax.make_mesh(axis_shapes=(4, 2), axis_names=('X', 'Y'))
# 辅助函数:将 PartitionSpec 包装为 NamedSharding
def P(*args):
return jax.NamedSharding(mesh, jax.sharding.PartitionSpec(*args))
# A[I_X, J_Y]:两个维度分别沿 X 和 Y 分片
A = jnp.zeros((8, 2048), dtype=jnp.bfloat16, device=P('X', 'Y'))
# B[J, K_Y]:J 维度不分片(None),K 维度沿 Y 分片
B = jnp.zeros((2048, 8192), dtype=jnp.bfloat16, device=P(None, 'Y'))
# 分片 matmul!JAX/XLA 自动处理通信
y = jax.jit(
lambda A, B: jnp.einsum('BD,DF->BF', A, B),
out_shardings=P('X', 'Y')
)(A, B)
关键特性:
B.shape返回全局形状(2048, 8192),而不是本地 shard 形状B.addressable_shards可以查看实际的本地分片- JAX/XLA 自动插入通信(AllGather、ReduceScatter 等)来完成跨设备操作
PartitionSpec中的None表示该维度不分片(复制)
📋 背景知识:PartitionSpec 与数学记号的对应
数学记号 PartitionSpec 含义 A[I, J]P(None, None)完全复制 A[I_X, J]P('X', None)I 沿 X 分片,J 复制 A[I, J_Y]P(None, 'Y')I 复制,J 沿 Y 分片 A[I_X, J_Y]P('X', 'Y')I 沿 X,J 沿 Y 分片 A[I_{XY}, J]P(('X','Y'), None)I 沿 XY 联合分片
6.2 分片矩阵乘法的四种情况
考虑矩阵乘法 C[B, F] = X[B, D] × W[D, F],其中 D 是收缩维度(contracting dimension)。
📋 背景知识:分块矩阵乘法的直觉
分片矩阵乘法的本质就是分块矩阵乘法(block matrix multiplication)。将矩阵按 shard 边界切成子块后,矩阵乘法规则仍然成立:
\[\begin{pmatrix} A_{00} & A_{01} \\ A_{10} & A_{11} \end{pmatrix} \cdot \begin{pmatrix} B_{00} & B_{01} \\ B_{10} & B_{11} \end{pmatrix} = \begin{pmatrix} A_{00}B_{00} + A_{01}B_{10} & A_{00}B_{01} + A_{01}B_{11} \\ A_{10}B_{00} + A_{11}B_{10} & A_{10}B_{01} + A_{11}B_{11} \end{pmatrix}\]
每个 $A_{ij}$ 和 $B_{ij}$ 就是一个设备持有的 shard。分布式矩阵乘法就是:
- 在设备间移动(通信)这些子块
- 对本地子块做矩阵乘法
- 如果需要,对部分和求和
核心问题就是:需要什么通信,开销有多大。
根据哪个维度被分片、以及被分片的是否是收缩维度,分为 4 种情况:
Case 1:无收缩维度被分片
场景:只要收缩维度 J 没有被分片,无论非收缩维度怎么分片,都可以直接做本地 matmul:
\[\begin{align*} A[I, J] \cdot B[J, K] \rightarrow &\ C[I, K] \\ A[I_X, J] \cdot B[J, K] \rightarrow &\ C[I_X, K] \\ A[I, J] \cdot B[J, K_Y] \rightarrow &\ C[I, K_Y] \\ A[I_X, J] \cdot B[J, K_Y] \rightarrow &\ C[I_X, K_Y] \end{align*}\]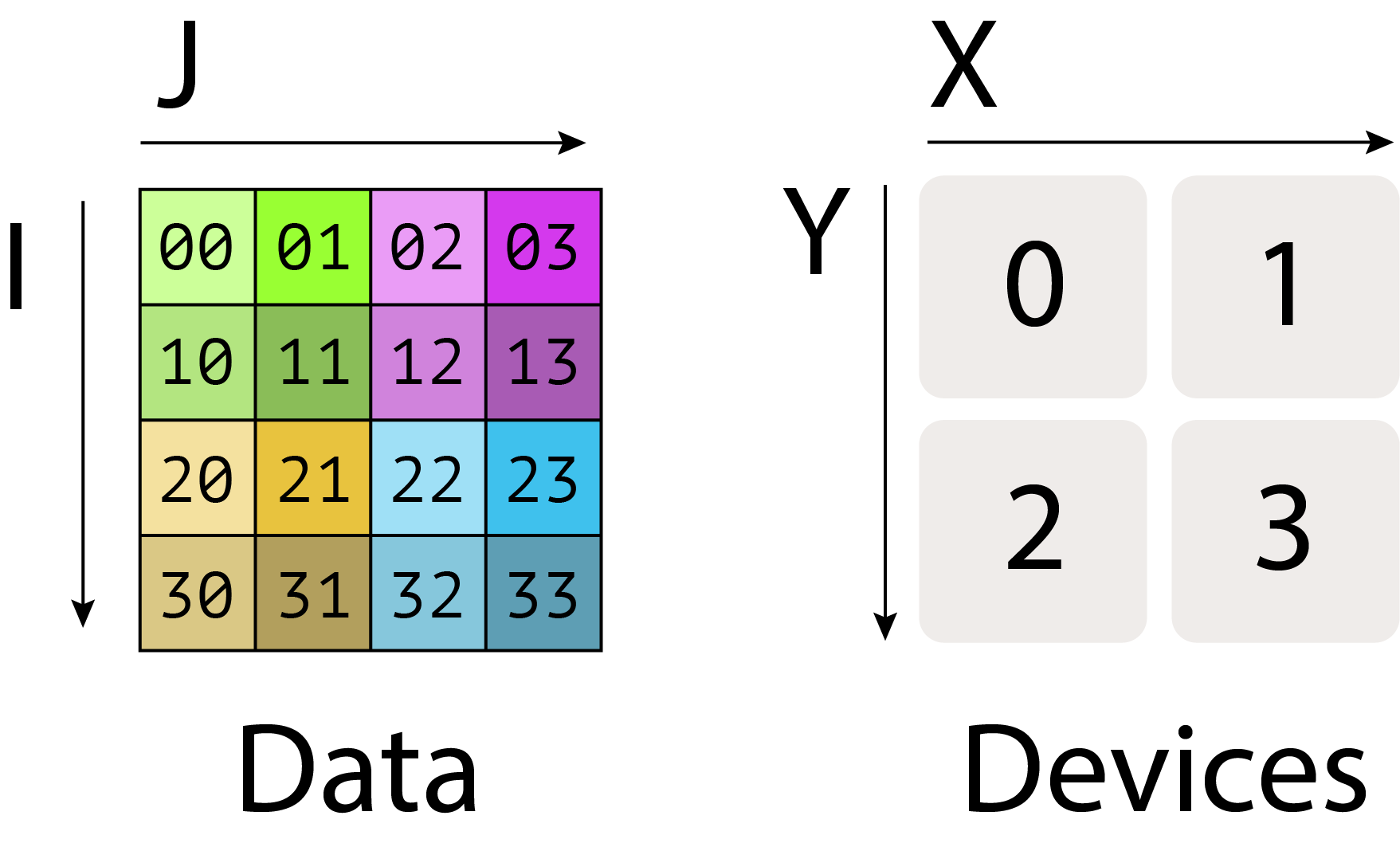
无需任何通信! 每个设备独立处理自己的 shard,输出的分片方式自然由输入决定。
这是最理想的情况,也是 Data Parallelism 和 Megatron Column Parallel 的基础。
Case 2:一个乘数的收缩维度被分片
场景:A[I, J_X] × B[J, K](A 沿收缩维度 J 分片,B 未分片)
由于 A 的收缩维度被分片,每个设备只有 J 的一部分,无法完成完整的收缩。解决方案:
策略 A(AllGather + matmul):先恢复完整的 A,再做本地 matmul
\[\text{AllGather}_X(A[I, J_X]) \rightarrow A[I, J] \quad\quad \text{通信:} \frac{2IJ}{W_{\text{ici}}}\] \[A[I, J] \cdot B[J, K] \rightarrow C[I, K] \quad\quad \text{每设备做完整 matmul}\]策略 B(本地 matmul + AllReduce):先做部分 matmul,再求和
\[A[I, J_X] \cdot_{\text{LOCAL}} B[J_X, K] \rightarrow C[I, K] \{U_X\} \quad\quad \text{部分和}\] \[\text{AllReduce}_X(C[I, K] \{U_X\}) \rightarrow C[I, K] \quad\quad \text{通信:} \frac{4IK}{W_{\text{ici}}}\]这里 ${U_X}$ 标记表示”沿 X 轴未归约”——每个设备的 C 只是最终结果的一个部分和。
如何选择:比较两边通信量即可。策略 A 的通信量是 $2IJ$,策略 B 的通信量是 $4IK$,所以当 $J > 2K$ 时策略 B 更好。映射到 Transformer 常见的 $X[B,D] \times W[D,F]$,条件就是 $D > 2F$。
Case 3:两个乘数的收缩维度都被分片
场景:A[I, J_X] × B[J_X, K](两者都沿 J 分片到同一组设备)
两个乘数在同一组设备上持有 J 的相同切片,因此可以做本地 matmul 得到部分和:
\[A[I, J_X] \cdot_{\text{LOCAL}} B[J_X, K] \rightarrow C[I, K] \{U_X\}\]然后用 AllReduce 或 ReduceScatter 完成求和:
\[\text{AllReduce}_X(C[I, K] \{U_X\}) \rightarrow C[I, K] \quad\quad \text{通信:} \frac{4IK}{W_{\text{ici}}}\]或者用 ReduceScatter(更常用,因为保持分片状态):
\[\text{ReduceScatter}_{X,K}(C[I, K] \{U_X\}) \rightarrow C[I, K_X] \quad\quad \text{通信:} \frac{2IK}{W_{\text{ici}}}\]注意 ReduceScatter 可以选择沿哪个维度引入新的分片(I 或 K),具体选择取决于后续操作需要的 sharding。
这是 Megatron Row Parallel 和 FSDP 中的核心模式。
Case 4:两个乘数的非收缩维度沿同一轴分片(非法 → 需修复)
场景:A[I_X, J] × B[J, K_X]——两个非收缩维度都分片在 X 轴上
这是非法的!设备 i 只能算出 C 的第 (i, i) 块(对角线),无法恢复完整结果。
修复方法:先 AllGather 其中一个输入,消除冲突:
\[\text{AllGather}_X(A[I_X, J]) \rightarrow A[I, J] \quad\quad \text{然后做 Case 1}\] \[A[I, J] \cdot B[J, K_X] \rightarrow C[I, K_X]\]或者 AllGather B:
\[\text{AllGather}_X(B[J, K_X]) \rightarrow B[J, K] \quad\quad \text{然后做 Case 1}\] \[A[I_X, J] \cdot B[J, K] \rightarrow C[I_X, K]\]选择哪个取决于后续操作需要的 sharding 和数据量大小。
📋 背景知识:为什么收缩维度的分片需要通信
矩阵乘法
C[i,j] = Σ_d X[i,d] × W[d,j]。
- 如果 d 维度被分片:每个设备只能算部分求和(${U_X}$),需要 AllReduce 加起来 → 需要通信
- 如果 i 或 j 维度被分片:每个设备算的是 C 的不同行/列,彼此独立 → 不需要通信
- 如果 i 和 j 在同一轴分片:得到的是对角块,信息丢失 → 必须先 AllGather
核心原则:分片收缩维度 = 需要 AllReduce/ReduceScatter;分片不同轴的非收缩维度 = 无需通信;分片同轴的非收缩维度 = 非法,需修复。
💡 Pop Quiz
对于 $A[I_X, J_Y] \cdot_J B[J_Y, K] \to C[?, ?]$,需要什么通信?输出的 sharding 是什么?
点击查看答案
B 沿收缩维度 J 分片(J_Y),A 也沿 J 分片(J_Y)。两者在同一轴 Y 上分片 → Case 3。
本地 matmul 得到 $C[I_X, K] {U_Y}$,然后 AllReduce_Y 得到 $C[I_X, K]$。
通信:AllReduce 的 $4 \times I/X \times K$ bytes(注意 I 已经被 X 分片,所以每个设备的 C 只有 $I/X$ 行)。
6.3 通信代价总结
| 分片方式 | 需要的通信 | 通信量(bytes) |
|---|---|---|
| 非收缩维度分片 | 无 | 0 |
| 一个收缩维度分片 | AllGather 或 ReduceScatter | ~2BD 或 ~2BF |
| 两个收缩维度分片 | AllReduce | ~4BF |
关键洞察:尽可能沿非收缩维度分片,避免通信开销。
6.4 通信原语速查
| 操作 | 语义 | 通信时间 |
|---|---|---|
| AllGather | [A_X, B] → [A, B] |
V / W_ici |
| ReduceScatter | [A, B] {U_X} → [A_X, B] |
V / W_ici(同 AllGather) |
| AllReduce | [A, B] {U_X} → [A, B] |
2V / W_ici |
| AllToAll | [A, B_X] → [A_X, B] |
V / (4·W_ici) |
这里的 $V$ 是参与这次 collective 的逻辑 payload 大小,$W_{\text{ici}}$ 是双向 ICI 带宽;小消息仍然会进入 latency-bound 区域。完整语义、ring 推导、AllToAll 的 1/4 直觉、以及 latency-bound 的阈值都在第 5 章展开过。
本章只记住一个映射即可:
- 需要完整输入 shard → AllGather
- 产生多个设备的部分和,但希望输出仍分片 → ReduceScatter
- 产生多个设备的部分和,并且每个设备都要完整结果 → AllReduce
- 需要把分片下标从一个维度换到另一个维度 → AllToAll
6.5 Roofline 视角下的分片 matmul
对于 N 个设备的分片 matmul X[B, D] × W[Dₓ, F](Case 3,AllReduce):
- 计算时间:$T_{\text{math}} = \frac{2BDF}{N \times \text{FLOPs/s}}$
- 通信时间(AllReduce):$T_{\text{comms}} = \frac{4BF}{W_{\text{ici}}}$
Compute-bound 条件:
\[\frac{2BDF}{N \times \text{FLOPs/s}} > \frac{4BF}{W_{\text{ici}}}\] \[D > \frac{2N \times \text{FLOPs/s}}{W_{\text{ici}}}\]即 D 要足够大来”摊平”通信开销。加的设备越多(N 越大),D 需要越大才能保持 compute-bound。
数值示例
TPU v5e(FLOPs/s = 1.97×10¹⁴, ICI = 9×10¹⁰ 双向):
\[D > \frac{2N \times 1.97 \times 10^{14}}{9 \times 10^{10}} = 4378N\]- N=4 (TP=4):D > 17,511 → 对于 D=8192,communication-bound
- N=2 (TP=2):D > 8,755 → 对于 D=8192,临界点附近
- N=1 (无 TP):无通信
结论:对于典型 Transformer(D=8192),TPU v5e 上 TP=4 就已经接近 communication-bound。这就是为什么 TP 通常不超过 8。
6.6 计算和通信的重叠(Collective Matmul)
在 Roofline 分析中我们假设 $T = \max(T_{\text{math}}, T_{\text{comms}})$。实现这个下界需要将通信和计算流水线化:
算法思路
以 Case 3 为例:X[B, D_X] × W[D_X, F] → C[B, F],需要 AllReduce。
朴素实现(串行):
1. 本地 matmul → C_partial[B, F]
2. AllReduce(C_partial) → C[B, F]
总时间 = T_math + T_comms
流水线实现(Collective Matmul):
将 matmul 分成 k 个 chunk(沿 B 维度):
for chunk_i in chunks:
1. 本地 matmul chunk_i → C_partial_i
2. 同时:AllReduce(C_partial_{i-1})(上一个 chunk 的结果)
总时间 ≈ max(T_math, T_comms)
关键:当一个 chunk 在做 AllReduce 时,下一个 chunk 的 matmul 同时进行。这样通信和计算完美重叠。
JAX 中的实现
# JAX collective matmul 示意
from jax.lax import psum_scatter, all_gather
def collective_matmul(x_shard, w_shard, mesh_axis='x'):
# x_shard: [B, D/N] 本地 shard
# w_shard: [D/N, F] 本地 shard
# 方法 1: AllGather + matmul(适合 B 小的情况)
x_full = all_gather(x_shard, axis_name=mesh_axis) # [B, D]
result = x_full @ w_shard # [B, F/N] if w is also sharded on F
# 方法 2: 本地 matmul + ReduceScatter(适合输出比输入更小的情况)
partial = x_shard @ w_shard # [B, F] partial sum
result = psum_scatter(partial, axis_name=mesh_axis) # [B, F/N]
return result
6.7 Megatron 中的分片矩阵乘法
🛠️ 实践:Megatron
Megatron 的 Tensor Parallelism 本质就是分片矩阵乘法:
Column Parallel Linear
FFN 的第一层
Y = XW₁:将 W₁ 按列切分到 TP 个设备上W₁[D, F] → 每设备持有 W₁[D, F/TP] X[B, D] × W₁[D, F/TP] → Y[B, F/TP](无需通信!)这是 Case 1/4 — 分片非收缩维度,无需通信。
Row Parallel Linear
FFN 的第二层
Z = YW₂:将 W₂ 按行切分W₂[F, D] → 每设备持有 W₂[F/TP, D] Y[B, F/TP] × W₂[F/TP, D] → Z_partial[B, D] AllReduce(Z_partial) → Z[B, D]这是 Case 3 — 收缩维度被分片,需要 AllReduce。
通信次数
一个 Transformer 层的前向传播中,Megatron 需要 2 次 AllReduce:
- FFN 的 Row Parallel 之后
- Attention 的 output projection 之后
反向传播中还需要额外 2 次,总共 4 次 AllReduce/层。
这就是为什么 TP 只适合节点内(NVLink 高带宽):每层都有 4 次 AllReduce。
6.8 分片策略选择的直觉
| 场景 | 推荐分片方式 | 原因 |
|---|---|---|
| Data Parallelism | 沿 B 维度分片 | 每设备处理不同 batch,计算独立 |
| Tensor Parallelism (FFN) | W 按列/行交替分片 | 最小化 AllReduce 次数 |
| Tensor Parallelism (Attention) | 沿 head 维度分片 | 不同 head 独立计算 |
| FSDP | 沿某维度分片参数,计算前 AllGather | 节省内存,用通信换空间 |
| Expert Parallelism (MoE) | 沿 expert 维度分片 | 需要 AllToAll 路由 token |
训练 vs 推理的分片选择
| 训练 | 推理(Generation) | |
|---|---|---|
| 目标 | 最大化 FLOPs 利用率 | 最小化延迟 |
| TP degree | 4-8(ICI bound 限制) | 可更大(因为 memory-bound) |
| FSDP | 常用(节省内存) | 通常不用于优化单请求 decode latency |
| DP | 常用(扩展 batch) | 作为多副本 serving 扩吞吐,而不是降低单请求步时间 |
| 分片原则 | 移动激活值 | 移动激活值(不移动 KV cache) |
6.9 Worked Problems(习题与详解)
Problem 1:复制比例
题目:数组 A[I_X, J, K, ...] 在 Mesh({‘X’: 4, ‘Y’: 8, ‘Z’: 2}) 上。所有设备上 A 占的总字节数与单份 A 大小的比值是多少?
点击查看答案
A 只沿 X 分片(4 份),在 Y 和 Z 上被复制。
- 每个设备持有:
sizeof(A) / 4 - 总设备数:
4 × 8 × 2 = 64 - 总字节数:
64 × sizeof(A) / 4 = 16 × sizeof(A)
比值 = 16(= Y × Z)
直觉:Y=8 和 Z=2 方向上各持有一份完整复制,所以总共有 8×2=16 份完整的 A。
Problem 2:两种 Matmul 策略比较
题目:执行 X[B, D] ×_D Y[D_X, F] → Z[B, F],比较两种策略:
- 策略 1:先 AllGather Y,再本地 matmul
- 策略 2:本地做部分 matmul,再 AllReduce
分别计算 FLOPs 和通信时间,哪个更好?
点击查看答案
策略 1(AllGather + matmul):
- 通信:AllGather
2DFbytes → 时间 =2DF / W_ici - 计算:每设备做完整 matmul
2BDFFLOPs → 时间 =2BDF / C - 总时间:$\max\left(\frac{2BDF}{C}, \frac{2DF}{W_{\text{ici}}}\right)$
策略 2(本地 matmul + AllReduce):
- 计算:每设备做
2BDF/XFLOPs → 时间 =2BDF / (X·C) - 通信:AllReduce
4BFbytes → 时间 =4BF / W_ici - 总时间:$\max\left(\frac{2BDF}{X \cdot C}, \frac{4BF}{W_{\text{ici}}}\right)$
比较:
当 B < 临界值(通信限制)时:
- 策略 1 通信 ∝ DF
- 策略 2 通信 ∝ BF
在这个题设下,策略 1 的通信量是 $2DF$,策略 2 的通信量是 $4BF$,所以当 D > 2B 时,策略 2 更好(通信量更小)。注意这里 AllGather 的是 $Y[D,F]$;和前文 AllGather $X[B,D]$ 时得到的 $D > 2F$ 是两个不同比较。
对于推理(B 小,如 B=16):D=8192 » 2×16=32,策略 2 远优于策略 1。 对于训练(B 大,如 B=4096):D=8192 > 2×4096=8192,临界点。
实践:在 Megatron 中,实际上更常使用策略 1 的变体(因为 TP 的 Column/Row 分片模式天然配合)。
Problem 3:Transformer Block 分片设计
题目:Transformer block 有 W_in[D, F] 和 W_out[F, D],其中 D=8192, F=32768, B=128, bf16。在 TPU v5e 2×2 slice 上,每设备只有 300MB 空闲内存。
如何分片?总 FLOPs 和通信时间各是多少?
点击查看答案
内存分析:
- 每个权重矩阵:
2 × 8192 × 32768 = 536 MB - 单设备 300MB → 必须分片
方案:Megatron TP(沿 F 维度分片)
分片策略(假设 Mesh{‘X’:2, ‘Y’:2},合并为 4-way TP):
W_in[D, F_{XY}]:每设备2 × 8192 × 8192 = 134MB✓W_out[F_{XY}, D]:每设备2 × 8192 × 8192 = 134MB✓- 总内存/设备:268MB < 300MB ✓
计算过程:
1. In[B, D] × W_in[D, F_XY] → Mid[B, F_XY] (Case 1,无通信)
2. GeLU(Mid)
3. Mid[B, F_XY] × W_out[F_XY, D] → Out[B, D] {U_XY} (Case 3)
4. ReduceScatter_{XY,D}(Out) → Out[B, D_XY]
5. (下一层需要 AllGather 恢复 In[B, D])
时间分析(TPU v5e:FLOPs/s=1.97×10¹⁴,ICI=9×10¹⁰ 双向):
FLOPs/设备:
- 第一层:
2 × 128 × 8192 × 32768 / 4 = 17.2 GFLOPs - 第二层:同上
- 总 FLOPs 时间:
2 × 17.2e9 / 1.97e14 = 175μs
通信:
- ReduceScatter:
2 × 128 × 8192 = 2.1MB→2.1e6 / 9e10 = 23μs - AllGather(为下一层):
2 × 128 × 8192 = 2.1MB→2.1e6 / 9e10 = 23μs - 总通信:
46μs
总时间:max(175, 46) = 175μs(compute-bound,好!)
如果 B 降到 16(推理场景):
- FLOPs 时间:
175 × 16/128 = 22μs - 通信时间:
46 × 16/128 = 5.8μs - 总时间:
max(22, 5.8) = 22μs(仍然 compute-bound)
Problem 4:最小延迟的 Matmul 分片
题目:在 TPU v4p 4×4×4 上执行 $A[I, J] \cdot_J B[J, K] \to C[I, K]$,要求结果完全复制(不分片)。输入可以任意分片。如何分片能获得最低延迟?
点击查看答案
四种最可能的方案:
- $A[I_{XYZ}, J] \cdot B[J, K] \to C[I_{XYZ}, K]$ + AllGather 恢复
- $A[I, J] \cdot B[J, K_{XYZ}] \to C[I, K_{XYZ}]$ + AllGather 恢复
- $A[I, J_{XYZ}] \cdot B[J_{XYZ}, K] \to C[I, K]{U_{XYZ}}$ + AllReduce
- $A[I, J] \cdot B[J, K]$(完全复制,无分片)
对于方案 1-3,每个 TPU 的计算量相同:$2IJK / 64$。
通信比较(设 $V_C = 2IK$, $V_A = 2IJ$, $V_B = 2JK$):
| 方案 | 通信操作 | 通信量 |
|---|---|---|
| 1 | AllGather C | $V_C / (W \cdot 3)$(3 轴) |
| 2 | AllGather C | $V_C / (W \cdot 3)$ |
| 3 | AllReduce C | $2V_C / (W \cdot 3)$ |
| 4 | 无 | 0,但计算 64× |
方案 1 和 2 等价且最优(AllGather 比 AllReduce 便宜一半)。方案 4 虽然无通信,但每设备做完整计算,通常不划算。
结论:沿非收缩维度分片(方案 1 或 2),然后 AllGather 结果。
Problem 5:具体分片的通信与计算分析
题目:在 TPU v5e 4×4(16 设备)上,分析以下三种分片方案的通信和计算时间。设 I=4096, J=8192, K=4096, bf16。
(a) $A[I_X, J_Y] \cdot_J B[J_Y, K] \to C[?, ?]$
(b) $A[I_X, J] \cdot_J B[J_X, K_Y] \to C[?, ?]$(训练中 Data + Tensor + ZeRO 的典型设置)
(c) $A[I_X, J] \cdot_J B[J, K_Y] \to C[?, ?]$(推理中 TP + DP 的典型设置)
点击查看答案
TPU v5e 参数:FLOPs/s = 1.97×10¹⁴, 双向 ICI = 9×10¹⁰ B/s。
(a) $A[I_X, J_Y] \cdot_J B[J_Y, K]$:
- A 和 B 都沿收缩维度 J 在 Y 轴分片 → Case 3
- 本地 matmul:$A[I_X, J_Y] \cdot_{\text{LOCAL}} B[J_Y, K] \to C[I_X, K]{U_Y}$
- 通信:AllReduce_Y → $C[I_X, K]$
- 计算时间:$2 \times (4096/4) \times (8192/4) \times 4096 / 1.97\text{e}14 = 87\mu s$
- 通信(AllReduce):$2 \times 2 \times (4096/4) \times 4096 / 9\text{e}10 = 186\mu s$
- communication-bound
(b) $A[I_X, J] \cdot_J B[J_X, K_Y]$:
- B 沿 J(收缩维度)在 X 轴分片 → 需要先处理
- 方法:AllGather_X(B) → B[J, K_Y],然后 A[I_X, J] · B[J, K_Y] → C[I_X, K_Y](Case 1,无通信)
- AllGather 通信:$2 \times 8192 \times (4096/4) / 9\text{e}10 = 186\mu s$
- 计算时间:$2 \times (4096/4) \times 8192 \times 4096 / 1.97\text{e}14 = 348\mu s$
- 近 compute-bound
(c) $A[I_X, J] \cdot_J B[J, K_Y]$:
- 收缩维度 J 未被分片 → Case 1
- 直接本地 matmul → C[I_X, K_Y]
- 无需任何通信!
- 计算时间:$2 \times (4096/4) \times 8192 \times (4096/4) / 1.97\text{e}14 = 87\mu s$
- 这就是为什么推理中纯 TP 是最高效的分片方式
Problem 6:另一种 Matmul 策略
题目:在 Case 2 中,我们说当只有一个输入的收缩维度被分片时($A[I, J_X] \cdot B[J, K]$),标准做法是先 AllGather A。但另一种策略是:先做本地 matmul 得到部分和,再 AllReduce。
\[A[I, J_X] \cdot B[J_X, K] \to C[I, K]\{U_X\}\] \[\text{AllReduce}_X(C[I, K]\{U_X\}) \to C[I, K]\]回答以下问题:
- 用下标写出每个设备上的具体计算
- 如果允许输出是分片的(而非复制),算法如何改变?
- 比较两种策略的通信代价
点击查看答案
(1) 设 A 的列被分成 X 份。设备 $d$ 持有 $A$ 的第 $d$ 组列:$A_{:, d}$,以及 $B$ 的第 $d$ 组行:$B_{d, :}$。
每个设备计算外积:$O_d[I, K] = A_{:,d} \cdot B_{d,:} = \sum_{i \in \text{shard}d} A \times B_{i,:}$
$O_d$ 是最终结果的一个部分和,标记为 ${U_X}$。
然后 AllReduce 所有设备的 $O_d$:$C[I, K] = \sum_d O_d[I, K]$
(2) 如果允许输出分片,可以用更便宜的 ReduceScatter 替代 AllReduce:
- $\text{ReduceScatter}_{X,K}\ C[I, K]{U_X} \to C[I, K_X]$(沿 K 分片)
- 或 $\text{ReduceScatter}_{X,I}\ C[I, K]{U_X} \to C[I_X, K]$(沿 I 分片)
ReduceScatter 的通信量只有 AllReduce 的一半。
(3) 通信代价比较:
| 策略 | 通信操作 | 通信数据量 |
|---|---|---|
| AllGather A + matmul | AllGather $A[I, J_X]$ | $2IJ / W_{\text{ici}}$ |
| matmul + ReduceScatter | ReduceScatter $C[I, K]$ | $2IK / W_{\text{ici}}$ |
两种策略的通信时间比 = $J/K$(AllGather 的数据大小 ∝ IJ,ReduceScatter ∝ IK)。
当 $J > K$ 时,ReduceScatter 策略更好;当 $J < K$ 时,AllGather 策略更好。
关键要点
- 分片非收缩维度 → 无需通信(好!)
- 分片收缩维度 → 需要 AllReduce/ReduceScatter(有开销)
- 一个输入的收缩维度被分片时,可以在 AllGather 输入和归约输出之间权衡
- 两个输入的收缩维度沿同一轴分片时,本地 matmul 只得到部分和,必须 ReduceScatter 或 AllReduce
- 两个非收缩维度沿同一 mesh 轴分片是非法布局,需要先 AllGather 修复
- Megatron 的 TP 用 Column Parallel(无通信)+ Row Parallel(ReduceScatter)交替
- 每个 Transformer 层需要 2 次 ReduceScatter + 2 次 AllGather(前向+反向共 4 对)
- D 越大,TP 越容易保持 compute-bound
- Collective Matmul 可以将通信和计算重叠,实现 T = max(T_math, T_comms)
- 通信原语的完整推导见第 5 章,本章只关心它们如何服务于分片 matmul
进一步阅读
- 原书 Chapter 3: Sharded Matrices and How to Multiply Them
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Megatron-LM v2: Reducing Activation Recomputation
- Wang et al., Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models — Collective Matmul 论文
- JAX Pallas Collective Matmul 文档