本章目标:精确计算 Transformer 每一层的参数量、FLOPs 和内存占用,建立”Transformer = 一系列已知大小的矩阵乘法”的量化直觉。
对应原书:Chapter 4 (All the Transformer Math You Need to Know)
改写范围:沿原书 Transformer math 主线展开,额外加入 MoE、FlashAttention、KV cache 等与现代模型/推理更贴近的补充。 优先级:⭐⭐ 中 | 建议时间:Day 6, 约 2.5 小时
7.1 Transformer 层的解剖
🔗 与你的联系
你做模型架构设计时一定计算过 FLOPs(比如用
6ND估算训练 FLOPs)。这一章将精确到 Transformer 的每一个矩阵乘法,让你理解 FLOPs 到底花在了哪里,内存被谁占用。这对你设计新架构和评估训练成本都直接有用。
一个标准 Transformer 层由两部分组成:
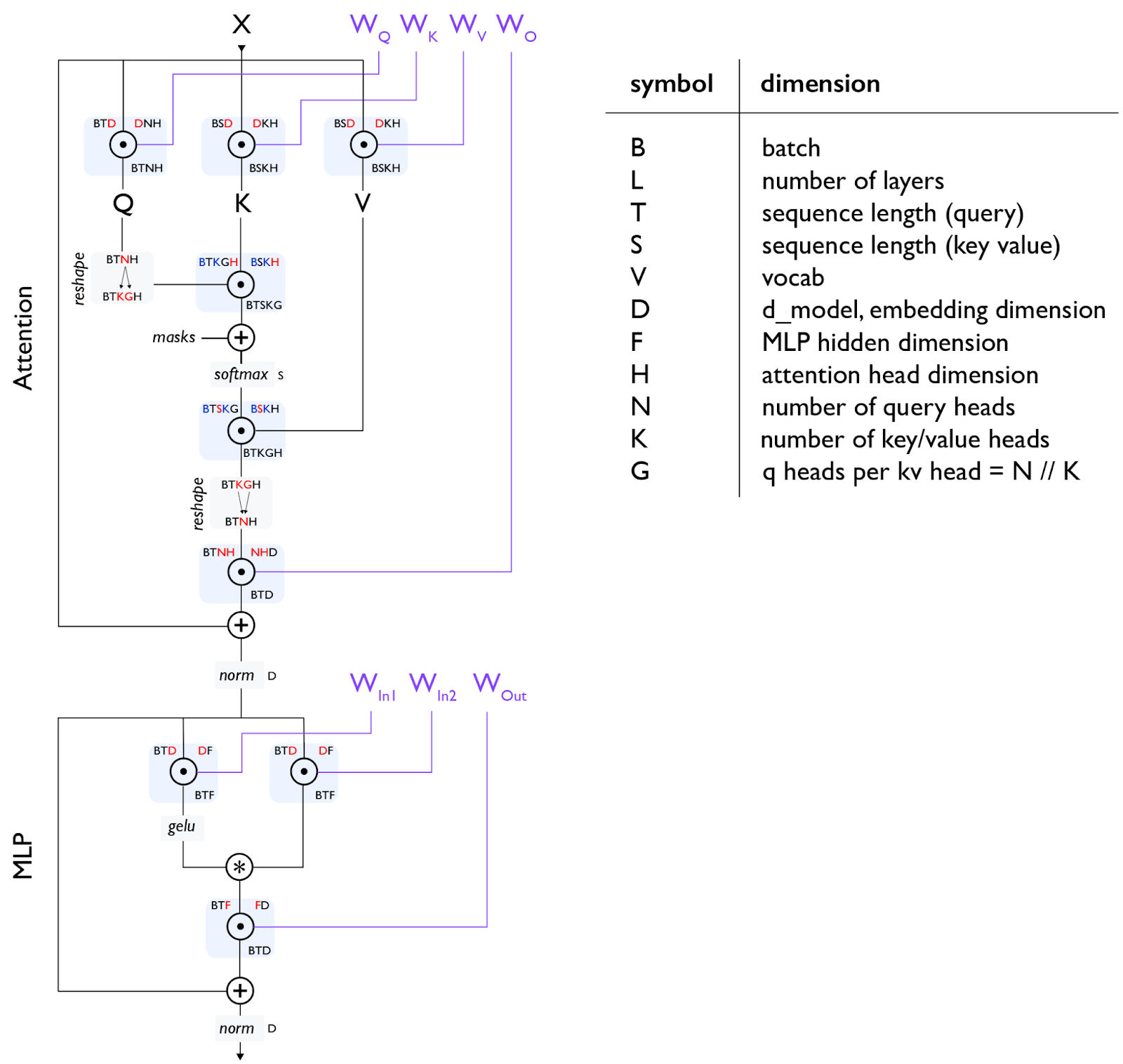
符号约定
| 符号 | 含义 | 典型值 (LLaMA 70B) |
|---|---|---|
| D | 隐藏维度 (d_model) | 8192 |
| F | FFN 中间维度 (d_ff) | 28672 |
| H | 注意力头数 | 64 |
| K | 每头维度 (d_head = D/H) | 128 |
| B | batch 中的 token 数 | 取决于配置 |
| S | 序列长度 | 4096-8192 |
| L | 层数 | 80 |
| V | 词表大小 | 32000 |
7.2 FLOPs 计算基础:数点运算
📋 背景知识:从向量到张量的 FLOPs 计算
运算 FLOPs 数据量(字节) 向量点积 $x \cdot y$,$x,y \in \mathbb{R}^P$ $2P$ $2P$ 矩阵-向量 $Ax$,$A \in \mathbb{R}^{N \times P}$ $2NP$ $NP + P$ 矩阵-矩阵 $AB$,$A \in \mathbb{R}^{N \times P}$, $B \in \mathbb{R}^{P \times M}$ $2NPM$ $NP + PM$ 关键观察:matmul 的计算量是 $O(N^3)$,但数据量只有 $O(N^2)$。这意味着矩阵越大,越容易达到 compute-bound。这也是为什么深度学习大量使用矩阵乘法——它们天然适合 scale up!
通用张量收缩的 FLOPs 规则
对于两个高维张量的收缩,FLOPs = 2 × 所有维度的乘积(收缩维度和 batch 维度只计一次)。
例如 $C[\text{G}, \text{H}, I, J, \text{K}, \text{L}] \cdot D[\text{G}, \text{H}, M, N, \text{K}, \text{L}]$:
- 收缩维度(出现在两个输入但不在输出中):K, L
- Batch 维度(出现在两个输入和输出中):G, H
- 非收缩维度:I, J, M, N
前向和反向的 FLOPs 关系
对于一个 matmul $C = AB$($A$[N,P], $B$[P,M]),训练时的反向传播需要:
\[\frac{\partial L}{\partial B} = A^T \left(\frac{\partial L}{\partial C}\right) \quad \text{→ } 2NPM \text{ FLOPs}\] \[\frac{\partial L}{\partial A} = \left(\frac{\partial L}{\partial C}\right) B^T \quad \text{→ } 2NPM \text{ FLOPs}\]前向 $2NPM$ + 反向 $4NPM$ = 训练总 $6NPM$ FLOPs。
由于 $PM$ 就是权重矩阵的参数量,这给出了著名的 $6 \times \text{tokens} \times \text{params}$ 训练 FLOPs 估算公式。
7.3 参数量计算
Attention 层
每个 Attention 层有 4 个权重矩阵:
| 矩阵 | 形状 | 参数量 |
|---|---|---|
| Q 投影 (Wq) | [D, D] | D² |
| K 投影 (Wk) | [D, Kv_heads × K] | D × Kv_heads × K |
| V 投影 (Wv) | [D, Kv_heads × K] | D × Kv_heads × K |
| Output 投影 (Wo) | [D, D] | D² |
对于标准 MHA(Multi-Head Attention):Kv_heads = H,参数量 = 4D²/层
对于 GQA(Grouped Query Attention):Kv_heads < H,K/V 投影更小。
\[P_{\text{attn}} = 2D \times (H + \text{Kv\_heads}) \times K\]| 模型 | H | Kv_heads | K | Attn 参数/层 |
|---|---|---|---|---|
| GPT-3 (MHA) | 96 | 96 | 128 | $4 \times 12288^2 = 604M$ |
| LLaMA 70B (GQA) | 64 | 8 | 128 | $2 \times 8192 \times 72 \times 128 = 151M$ |
| LLaMA 8B (GQA) | 32 | 8 | 128 | $2 \times 4096 \times 40 \times 128 = 42M$ |
📋 背景知识:MHA vs GQA vs MQA
- MHA:每个 Q head 有独立的 K, V head → Kv_heads = H
- GQA:多个 Q head 共享一组 K, V → Kv_heads < H(LLaMA 3 用 H=64, Kv_heads=8,即 8 组)
- MQA:所有 Q head 共享一组 K, V → Kv_heads = 1
GQA 是 MHA 和 MQA 的折中:KV cache 缩小到 MHA 的 $\text{Kv_heads}/H$ 倍,同时保持接近 MHA 的表达能力。
FFN 层
标准 FFN(SwiGLU,LLaMA 使用):
| 矩阵 | 形状 | 参数量 |
|---|---|---|
| Gate 投影 (W_gate) | [D, F] | DF |
| Up 投影 (W_up) | [D, F] | DF |
| Down 投影 (W_down) | [F, D] | DF |
FFN 参数量 = 3DF/层
总参数量
\[P \approx L \times (4D^2 + 3DF) + VD\]最后的 VD 是 embedding 层和 output head。
📋 背景知识:为什么 F 通常是 D 的 3-4 倍
早期 Transformer(如 GPT-2)使用 F = 4D。现代模型使用 SwiGLU 激活函数,由于多了一个 gate 矩阵(3 个 [D,F] 而非 2 个 [D,F]),通常设 F ≈ 8D/3 来保持总 FLOPs 不变。
LLaMA 70B:D=8192, F=28672 ≈ 3.5D
🛠️ 实践:用 Megatron-LM 配置验证参数量
Megatron 的模型配置直接对应上面的符号:
# LLaMA 70B 配置 --num-layers 80 \ # L = 80 --hidden-size 8192 \ # D = 8192 --ffn-hidden-size 28672 \ # F = 28672 --num-attention-heads 64 \ # H = 64 --num-query-groups 8 \ # Kv_heads = 8 (GQA) --seq-length 4096 \ # S = 4096 --vocab-size 32000 # V = 32000手算参数量:
- Attention/层:$2 \times 8192 \times (64 + 8) \times 128 = 150.99M$
- FFN/层:$3 \times 8192 \times 28672 = 704.64M$
- 每层小计:$855.64M$
- 80 层 + embedding:$80 \times 855.64M + 8192 \times 32000 = 68.7B$
与 LLaMA 2 70B 的官方参数量(68.9B)基本一致,差异来自 LayerNorm 参数和 output head。
Megatron 启动日志中会打印
number of parameters,可以直接验证。
7.4 FLOPs 计算
📋 背景知识:矩阵乘法的 FLOPs 计算
A[M,K] × B[K,N]的 FLOPs =2×M×K×N
- M×N 个输出元素,每个需要 K 次乘法和 K-1 次加法 ≈ 2K 次运算
前向传播 FLOPs
QKVO 投影 FLOPs
| 操作 | 训练 FLOPs | 参数量 |
|---|---|---|
| $A[\text{B,T,}\red{D}] \cdot W_Q[\red{D}, H, K]$ | $6BT \cdot D \cdot HK$ | $D \cdot HK$ |
| $A[\text{B,T,}\red{D}] \cdot W_K[\red{D}, \text{Kv}, K]$ | $6BT \cdot D \cdot \text{Kv} \cdot K$ | $D \cdot \text{Kv} \cdot K$ |
| $A[\text{B,T,}\red{D}] \cdot W_V[\red{D}, \text{Kv}, K]$ | $6BT \cdot D \cdot \text{Kv} \cdot K$ | $D \cdot \text{Kv} \cdot K$ |
| $A[\text{B,T,}\red{H,K}] \cdot W_O[\red{H,K}, D]$ | $6BT \cdot D \cdot HK$ | $HK \cdot D$ |
| 小计 | $12BTD(H+\text{Kv})K$ | $2D(H+\text{Kv})K$ |
标准 MHA(Kv=H):$24BTD \cdot HK = 24BTDNH$(因为 $D = NH$)
Attention Dot-Product FLOPs
QKVO 投影之外,还有注意力本身的 $QK^T$ 和 $\text{softmax}(QK^T)V$ 操作:
| 操作 | 训练 FLOPs |
|---|---|
| $Q[\blue{B}, T, \blue{\text{Kv}}, G, \red{K}] \cdot K[\blue{B}, S, \blue{\text{Kv}}, \red{K}]$ | $6BTSKGH = 6BTSNH$ |
| $\text{softmax}_S(\cdot)$ | $O(BTSN)$(可忽略) |
| $S[\blue{B}, T, \red{S}, \blue{\text{Kv}}, G] \cdot V[\blue{B}, \red{S}, \blue{\text{Kv}}, K]$ | $6BTSKGH = 6BTSNH$ |
| 小计 | $12BT^2NH$(自注意力 $S=T$) |
Causal masking:大多数现代 LLM 使用因果掩码,只有下三角有效 → 有效 FLOPs 减半为 $6BT^2NH$。但需要 Flash Attention 等内核才能真正实现这个减半。
MLP FLOPs
| 操作 | 训练 FLOPs | 参数量 |
|---|---|---|
| $A[\text{B,T,}\red{D}] \cdot W_{\text{gate}}[\red{D}, F]$ | $6BTDF$ | $DF$ |
| $A[\text{B,T,}\red{D}] \cdot W_{\text{up}}[\red{D}, F]$ | $6BTDF$ | $DF$ |
| $\sigma(A) * A$(逐元素,可忽略) | $O(BTF)$ | — |
| $A[\text{B,T,}\red{F}] \cdot W_{\text{down}}[\red{F}, D]$ | $6BTDF$ | $DF$ |
| 小计 | $18BTDF$ | $3DF$ |
注意力 vs MLP 的 FLOPs 比例
忽略 dot-product attention 时,一层的训练 FLOPs ≈ $18BTDF + 12BTD(H+\text{Kv})K$。
标准 MHA + SwiGLU($D = NH$, $F \approx 4D$)的 attention 参数占比:
\[\frac{4D^2}{4D^2 + 3DF} = \frac{4D^2}{4D^2 + 12D^2} = \frac{1}{4}\]MLP 主导参数和 FLOPs(在序列长度不太长时)。
注意力成本与序列长度的关系
当 $F \approx 4D$ 且 $D = NH$ 时,dot-product attention FLOPs 占比为:
\[\frac{\text{attention FLOPs}}{\text{matmul FLOPs}} = \frac{12BT^2NH}{18BTDF + 24BTDNH} = \frac{12BT^2D}{96BTD^2} = \frac{T}{8D}\]当 $T > 8D$ 时 attention FLOPs 才开始主导。对于 $D=8192$,这需要 $T > 65536$。大模型中 attention 的二次成本并不像想象的那么可怕。
但对于较小的模型,这个阈值更低。例如 Gemma 27B($D = 4608$)在 $T \approx 36K$ 时 attention 就开始主导。
| 模型 | D | Attention 主导阈值 ($8D$) |
|---|---|---|
| GPT-3 175B | 12288 | ~98K |
| LLaMA 70B | 8192 | ~65K |
| LLaMA 8B | 4096 | ~33K |
| Gemma 27B | 4608 | ~37K |
💡 Pop Quiz:注意力 FLOPs 何时等于投影 FLOPs?
Dot-product attention FLOPs = $12BT^2NH$,QKVO 投影 FLOPs = $24BTDNH$。何时相等?
点击查看答案
$12BT^2NH = 24BTDNH \implies T = 2D$
对于 $D=4096$,这是 $T=8192$。大部分合理上下文长度下,投影 FLOPs 大于 attention FLOPs。
整个模型前向传播
\[\text{FLOPs}_{\text{forward}} \approx L \times (8BD^2 + 4BSD + 6BDF) + 2BDV\]当 $S \ll D$ 时可忽略 attention 项:
\[\text{FLOPs}_{\text{forward}} \approx L \times B \times (8D^2 + 6DF) \approx 2BP\]这就是 “前向 FLOPs ≈ 2 × tokens × params” 规则。
训练总 FLOPs
前向 $2NP$ + 反向 $4NP$ = 训练总 $6NP$ FLOPs。
\[\text{FLOPs}_{\text{training}} \approx 6 \times N \times P\]其中 $N$ 是训练的总 token 数,$P$ 是参数量。
🛠️ 实践:用 6NP 规则估算训练成本
LLaMA 3 70B 在 15T tokens 上训练:
- 理论 FLOPs = $6 \times 15 \times 10^{12} \times 68.9 \times 10^9 = 6.2 \times 10^{24}$
- H100 FP16 性能 = 990 TFLOPs/s,假设 40% MFU
- 有效 FLOPs/s/GPU = $990 \times 10^{12} \times 0.4 = 396 \times 10^{12}$
- 所需 GPU-hours = $\frac{6.2 \times 10^{24}}{396 \times 10^{12} \times 3600} = 4.35 \times 10^6$ GPU-hours
- 16K GPU 集群:$\frac{4.35 \times 10^6}{16000} = 272$ 小时 ≈ 11.3 天
Megatron 训练日志中的
\[\text{MFU} = \frac{6 \times \text{tokens/iter} \times P}{\text{elapsed time} \times \text{GPU数} \times \text{peak FLOPs/s}}\]elapsed time per iteration可以反推实际 MFU:
完整的逐层汇总:
| 组件 | 参数/层 | 训练 FLOPs/层 |
|---|---|---|
| MLP | $3DF$ | $18BTDF$ |
| Attention (MHA) | $4DNH$ | $24BTDNH + 12BT^2NH$ |
| LayerNorm 等 | $D$ | $O(BTD)$ |
| Vocab (非逐层) | $DV$ | $12BTDV$ |
7.5 内存占用
模型权重
| 精度 | 每参数字节数 | 70B 模型 |
|---|---|---|
| fp32 | 4 | 280 GB |
| bf16 | 2 | 140 GB |
| int8 | 1 | 70 GB |
| int4 | 0.5 | 35 GB |
训练时的完整内存
| 组件 | 每参数字节数 | 70B 模型 |
|---|---|---|
| 权重 (bf16) | 2 | 140 GB |
| 梯度 (bf16) | 2 | 140 GB |
| 优化器状态 (Adam, fp32) | 8 | 560 GB |
| 小计 | 12 | 840 GB |
加上激活值(取决于 batch size 和是否使用 gradient checkpointing),总内存可达 1+ TB。
📋 背景知识:为什么 Adam 需要 8 字节/参数
Adam 优化器为每个参数维护两个状态:
- 一阶动量 $m$(梯度的指数移动平均):fp32,4 字节
- 二阶动量 $v$(梯度平方的指数移动平均):fp32,4 字节
此外,混合精度训练中还需要一份 fp32 主权重(master weights)用于参数更新的数值精度,这又是 4 字节/参数。所以完整的优化器内存实际上是 12 字节/参数(而非上表中的 8 字节)。
上表中的”权重 2B + 优化器 8B”是简化写法——8B 中已包含 fp32 主权重的 4B。更精确的分解是:
- bf16 权重:2B(用于前向/反向计算)
- fp32 主权重:4B(用于参数更新)
- fp32 一阶动量:4B
- fp32 二阶动量:4B
- bf16 梯度:2B
- 总计:16 字节/参数(如果单独计算 fp32 主权重)
KV Cache(推理时)
每层每 token 的 KV cache:
\[\text{KV cache/token/layer} = 2 \times 2 \times K_v\_\text{heads} \times K = 4 \times K_v\_\text{heads} \times K \text{ bytes (bf16)}\]对 LLaMA 70B(GQA,Kv_heads=8,K=128):
- 每 token 每层:4 × 8 × 128 = 4096 bytes = 4 KB
- 80 层,序列长度 4096:4 KB × 80 × 4096 = 1.3 GB/序列
Gradient Checkpointing(梯度检查点/重计算)
反向传播是一种用内存换计算的算法。为了避免反向传播需要 $O(L^2)$ FLOPs,它在前向传播时保存所有中间激活值,这需要 $O(L)$ 内存。
不使用 checkpointing 时的激活内存:
对于 Transformer,每层大约有 20 个中间节点需要保存(每个 matmul 的输入输出、softmax 输出、激活函数中间值等)。例如对于 $f(x) = \exp(g(x))$:
\[\frac{df}{dx} = \exp(g(x)) \cdot \frac{dg}{dx}\]要避免重新计算,就需要同时保存 $g(x)$ 和 $\exp(g(x))$。
以 $BT = 4M$(每 batch 4M tokens)、$L=64$、$D=8192$ 为例:
\[\text{激活内存} = 2 \times 20 \times B \times T \times D \times L = 2 \times 20 \times 4M \times 8192 \times 64 \approx \textbf{84 TB}\]这显然无法放入任何现有硬件!这就是 gradient checkpointing 必不可少的原因。
Checkpointing 策略:
| 策略 | 保存内容 | 每层保存量 | 训练 FLOPs |
|---|---|---|---|
| 无 checkpointing | 所有 ~20 个中间节点 | ~20 × BTD | 6ND |
| Block remat | 仅每层输入(1 个检查点) | 1 × BTD | 8ND(+33%) |
| Big-matmuls-only | 仅 7 个大 matmul 输出 | 7 × BTD | ~7ND |
- Block remat:最激进的策略,只保存每层的输入。反向传播时需要重新执行几乎全部前向计算。上面的 84TB 例子变为 $2 \times 1 \times 4M \times 8192 \times 64 = 4.2\text{TB}$。FLOPs 从 $6ND$ 增加到约 $\textbf{8ND}$。
- Big-matmuls-only:只保存 7 个大矩阵乘法的输出(Q, K, V, O 投影 + 3 个 FFN 矩阵),避免重新计算这些昂贵的 matmul,只需重新计算 attention softmax 和激活函数等较便宜的操作。
🛠️ 实践:Megatron-LM 的重计算配置
Megatron 提供了精细的 checkpointing 控制:
# 完整重计算(block remat) --recompute-granularity full \ --recompute-method block \ --recompute-num-layers 64 # 选择性重计算(只重计算 attention 中的 core attention) --recompute-granularity selective
selective模式只重计算 core attention($QK^T$ 和 softmax·V),保留 QKVO 投影和 FFN matmul 的输出,是 block remat 和完全不重计算之间的折中。
7.6 MoE(Mixture of Experts)的特殊性
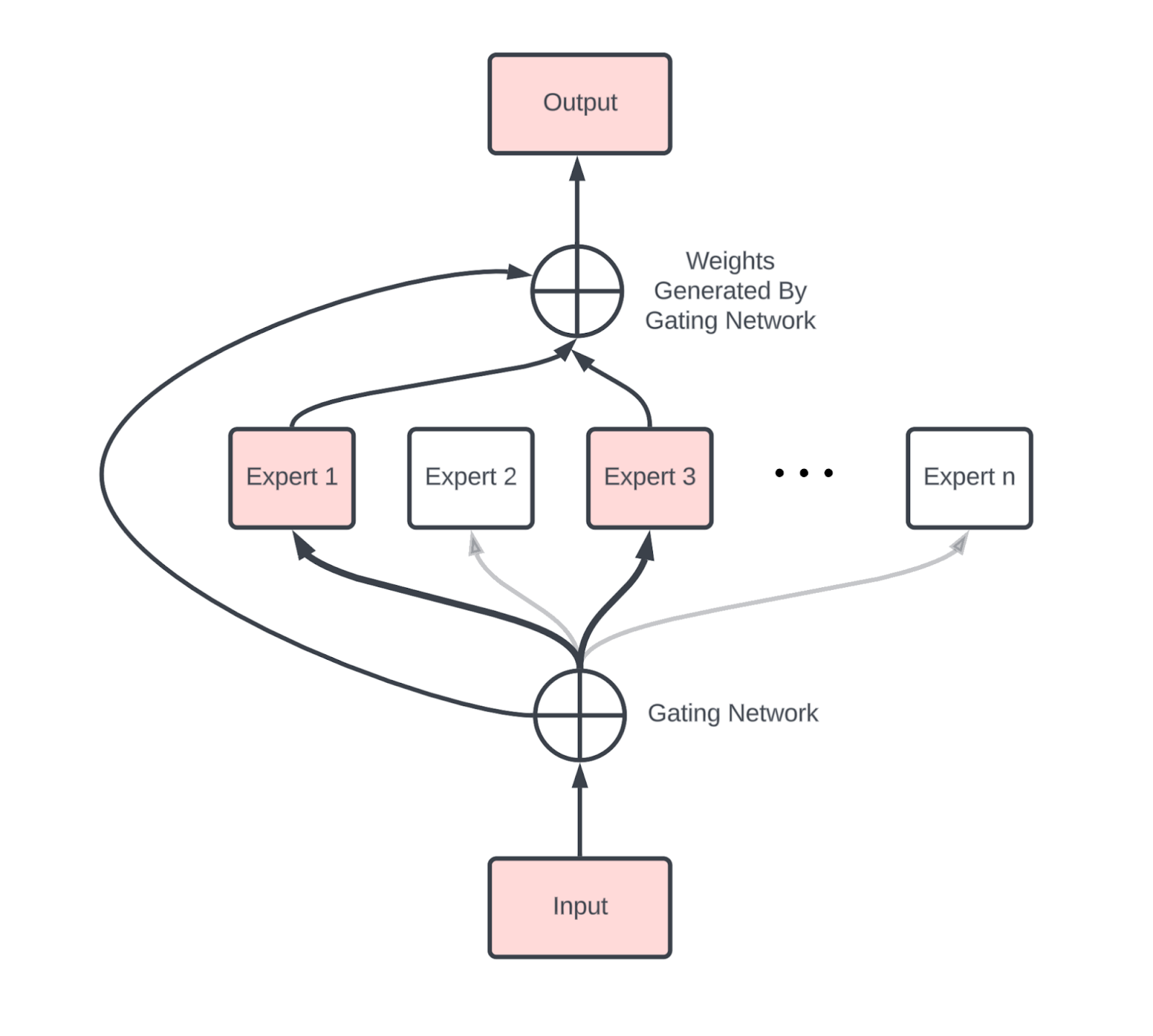
MoE 将标准 Transformer 中的单个 dense MLP 替换为 E 个独立的 MLP(expert),每个 token 通过一个 gating network 只路由到 top-k 个 expert。
MoE 的参数量与 FLOPs
| 指标 | Dense 模型 | MoE 模型 | 变化 |
|---|---|---|---|
| FFN 参数/层 | $3DF$ | $E \times 3DF$ | ×E |
| 激活参数/token | $3DF$ | $k \times 3DF$ | ×k |
| FFN FLOPs/token | $18BTDF$ | $k \times 18BTDF$ | ×k |
| 权重内存 | $3DF$ | $E \times 3DF$ | ×E |
稀疏度 $E/k$ 通常在 8-64 之间。例如 DeepSeek-V3:$E=256$(路由专家),$k=8$,稀疏度 = 32。
这就是 MoE 模型的核心 trade-off:
- 更多参数 = 更多知识存储容量 → 更好的模型质量
- 更少 FLOPs/token = 每个 token 只激活 $k/E$ 的参数 → 更快的训练/推理
- 代价:需要 AllToAll 通信将 token 路由到持有对应 expert 的设备(参见第 5 章)
MoE 何时 Compute-Bound?
对于 int8 权重的 MoE,每个权重矩阵需要加载 $E \times D \times F$ 字节,但只做 $2k \times B \times D \times F$ FLOPs。算术强度为:
\[\text{AI} = \frac{2kBDF}{EDF} = \frac{2kB}{E}\]要达到 compute-bound(AI > 240):
\[B > \frac{120E}{k}\]| 模型 | E | k | 临界 batch size |
|---|---|---|---|
| Mixtral 8x7B | 8 | 2 | 480 |
| DeepSeek-V3 | 256 | 8 | 3840 |
DeepSeek-V3 在 generation 阶段需要 3840 tokens 的 batch 才能 compute-bound——这是一个非常大的 batch size!这也解释了为什么 MoE 模型在推理时更依赖大 batch 来提升吞吐量。
MoE 的通信开销
MoE 引入两次 AllToAll 通信(expert 前和 expert 后),将 token 路由到持有对应 expert 的设备,再将结果送回。如第 5 章所述,每个 AllToAll 的代价只有同等 AllGather 的 1/4(双向 ring),所以 MoE 的通信开销相对可控。
| 通信 | 操作 | 数据量 |
|---|---|---|
| Expert 前 | AllToAll(发送 token → expert 设备) | $B \times D / N_{\text{devices}}$ |
| Expert 后 | AllToAll(返回结果 → 原设备) | $B \times D / N_{\text{devices}}$ |
但如果跨节点 AllToAll,由于无法利用 reduce 的层级优化(参见第 4 章),有效带宽会显著下降。这也是为什么 Expert Parallelism 通常尽量保持在节点内。
7.7 Flash Attention
关于 Transformer 在长上下文下的二次开销,有两个重要的 caveat:
- 如前面分析所示,attention FLOPs 只有当 $S > 8D$ 时才开始主导。对于大模型,这意味着序列长度需要超过 65K 才是瓶颈。
- 我们不需要把完整的 attention 矩阵存在内存中! 可以通过分块计算局部 softmax 来避免 $O(S^2)$ 的内存。
第二个观察就是 Flash Attention 的核心思想。
标准 Attention 的问题
标准实现需要在 HBM 中存储完整的 $[B, H, T, S]$ attention 矩阵:
\[S = Q \times K^T \quad \text{→ 形状 } [B, H, T, S]\]- 当 $S = 8192$,$H = 64$ 时,这个矩阵需要 ~4 GB(bf16)
- 更糟糕的是,它必须写入 HBM 再读回来做 softmax,产生大量 HBM I/O
Online Softmax 算法

Flash Attention 的关键是 online softmax:将 K, V 序列分成小 chunk,在 SRAM/VMEM 中逐 chunk 计算局部 attention,同时维护三个运行统计量:
- M:$q \cdot k$ 在序列维度上的 running max
- O:running full attention 输出
- L:running softmax 分母 $\sum_i \exp(q \cdot k_i - \text{running max})$
为什么这可行? 考虑两个连续的 key 块 $K^1$ 和 $K^2$,它们各自的局部 softmax 分母为:
\[L^1 = \sum_i \exp(Q \cdot K_i^1 - M^1), \quad L^2 = \sum_i \exp(Q \cdot K_i^2 - M^2)\]其中 $M^1 = \max_j Q \cdot K_j^1$,$M^2 = \max_j Q \cdot K_j^2$。
可以将它们合并为完整的 softmax:
\[L^{\text{combined}} = \exp(M^1 - \max(M^1, M^2)) \cdot L^1 + \exp(M^2 - \max(M^1, M^2)) \cdot L^2\]这利用了 $\sum_i \exp(a_i + b) = \exp(b) \sum_i \exp(a_i)$ 的性质——减去 max 不影响最终结果,但可以分块累积。
Flash Attention 的效果
| 指标 | 标准 Attention | Flash Attention |
|---|---|---|
| HBM 读写量 | $O(S^2)$ | $O(S)$ |
| 额外内存 | $O(BHS^2)$ | $O(BH)$(常数级) |
| FLOPs | $O(S^2)$(不变) | $O(S^2)$(不变) |
| 实际加速 | — | 2-4× |
Flash Attention 不减少 FLOPs 总量(attention 的 FLOPs 仍然是 $12BT^2NH$),但通过将 Q 保持在 SRAM/VMEM 中、逐 chunk 流式加载 K/V,大幅提升了算术强度。
反向传播中的关键恒等式
Flash Attention 的反向传播也可以分块计算,这依赖于一个重要的恒等式。对于 softmax 输出 $S_{ij}$,反向传播中需要计算 $S_{ij} \cdot_j dS_{ij}$(沿序列维度 $j$ 求和),这看似需要完整的 $S \times S$ 矩阵。但利用以下恒等式:
\[\sum_j S_{ij} \cdot dS_{ij} = \sum_d dO_{id} \cdot O_{id}\]将沿序列长度维度的收缩转换为沿特征维度的局部收缩。这使得反向传播也能在 SRAM 中分块完成,是 Flash Attention 训练可行的关键。
📋 背景知识:Causal Masking 与 Flash Attention
对于因果(causal)attention,只有下三角矩阵有效,理论上 FLOPs 减半为 $6BT^2NH$。但标准实现仍然计算完整矩阵再 mask,无法真正节省计算。
Flash Attention 的分块策略天然支持 causal masking:对于完全在上三角的 chunk 直接跳过,部分在下三角的 chunk 只计算有效部分。这使得 causal masking 的 FLOPs 节省真正实现。
7.8 其他操作
LayerNorm
每层有 2 个 LayerNorm(attention 前和 FFN 前),每个操作 $O(BTD)$ FLOPs,参数量 $D$。相比 matmul 的 $O(BTD^2)$ 可以忽略不计。
Unembedding(输出头)
模型最后一层的 unembedding 矩阵将隐藏维度映射到词表:
\[A[B, T, \red{D}] \cdot W_{\text{unembed}}[\red{D}, V] \quad \text{→ 训练 FLOPs: } 6BTDV, \text{ 参数: } DV\]对于 $V = 32000$, $D = 8192$:参数量 = 262M。注意许多模型(如 LLaMA)共享 embedding 和 unembedding 权重(weight tying),此时不额外增加参数。
📋 背景知识:Weight Tying(权重共享)
Weight tying 让 embedding 层和 unembedding 层共享同一个 $[V, D]$ 权重矩阵。
- 优点:减少 $DV$ 参数(LLaMA 70B 约 262M);embedding 和 output 的语义空间一致
- 缺点:在张量并行(TP)时增加复杂性——embedding 通常按词表维度分片(column parallel),而 unembedding 需要先 AllGather 再分片
- LLaMA 1/2/3 使用 weight tying;GPT-3 不使用
在 Megatron 中通过
--untie-embeddings-and-output-weights控制(默认 tied)。
完整的逐组件汇总
| 组件 | 参数/层 | 训练 FLOPs/层 |
|---|---|---|
| MLP (SwiGLU) | $3DF$ | $18BTDF$ |
| Attention (MHA) | $4DNH$ | $24BTDNH + 12BT^2NH$ |
| LayerNorm (×2) | $2D$ | $O(BTD)$(可忽略) |
| Embedding + Unembedding(总计) | $DV$(或 $2DV$) | $12BTDV$ |
7.9 KV Cache 深入分析
推理中 KV cache 的大小直接决定了能同时服务多少请求。
KV Cache 的精确大小
每个 KV cache 是一个形状为 $[2, S, L, \text{Kv_heads}, K]$ 的数组:
\[\text{KV cache/序列} = 2 \times S \times L \times \text{Kv\_heads} \times K \times \text{sizeof(dtype)}\]| 模型 | L | Kv_heads | K | 序列长度 | KV cache/序列 (bf16) |
|---|---|---|---|---|---|
| LLaMA 7B (MHA) | 32 | 32 | 128 | 4096 | 2 × 4096 × 32 × 32 × 128 × 2 = 2.1 GB |
| LLaMA 70B (GQA) | 80 | 8 | 128 | 4096 | 2 × 4096 × 80 × 8 × 128 × 2 = 1.3 GB |
| LLaMA 70B (GQA) | 80 | 8 | 128 | 8192 | 2.7 GB |
GQA 的 KV cache 只有 MHA 的 $\text{Kv_heads}/H$ 倍。LLaMA 70B 用 GQA(8 vs 64 heads)将 KV cache 缩小到 MHA 的 1/8。
为什么 KV Cache 是推理的主要瓶颈
- 256 个并发请求 × 1.3 GB/序列 = 333 GB 仅用于 KV cache
- 加上模型权重(bf16 下 140 GB)→ 总计需要 473 GB HBM
- 这还不包括中间计算的临时内存
减少 KV cache 的三种主要方法:
- GQA/MQA:减少 Kv_heads 数量 → cache 缩小 $H/\text{Kv_heads}$ 倍
- 量化:int8 或 int4 KV cache → 缩小 2-4 倍
- 前缀共享:SGLang 的 RadixAttention 等技术让共享 prompt 前缀的请求复用 KV cache
💡 Pop Quiz:KV cache 每 token 多大?
对于 LLaMA 70B(L=80, Kv_heads=8, K=128),int8 精度下每 token 的 KV cache 大小是多少?
点击查看答案
每 token:$2 \times L \times \text{Kv_heads} \times K = 2 \times 80 \times 8 \times 128 = 163,840$ bytes ≈ 160 KB/token(int8)。
4096 token 序列:160 KB × 4096 = 640 MB/序列(int8 比 bf16 的 1.3 GB 减半)。
习题
Q1:模型参数量计算
一个模型有 $D=4096$, $F=4D$, $V=32000$, $L=64$,使用 MHA($D = NH$)。
(a) 总参数量是多少? (b) Attention 参数占总参数的比例? (c) 每 token 的 KV cache 大小(int8)?
点击查看答案
(a) 总参数量 $\approx L \times (3DF + 4D^2 + D) + 2DV$
\[= 64 \times (3 \times 4096 \times 16384 + 4 \times 4096^2 + 4096) + 2 \times 4096 \times 32000\] \[= 64 \times (201M + 67M + 4K) + 262M \approx 17.4B \approx \textbf{16B 参数}\](b) Attention 参数比例:
\[\frac{4D^2}{4D^2 + 3DF} = \frac{4D^2}{4D^2 + 12D^2} = \frac{1}{4}\]约 25% 的参数在 attention 中。
(c) KV cache/token = $2 \times L \times N \times H = 2 \times 64 \times 4096 = 524,288$ bytes (int8) = 512 KB/token。
Q2:分片 matmul 的 FLOPs
计算 $A[B_X, D_Y] \cdot W[D_Y, F]$ 在 {'X': 4, 'Y': 8, 'Z': 4} 分片上的 FLOPs。每个 TPU 执行多少 FLOPs?
点击查看答案
“理论” FLOPs 为 $2BDF$。但计算没有在 Z 维度上分片,所以每个 Z 副本都做同样的计算,总实际 FLOPs = $2BDF \times Z$。
由于计算在 X 和 Y 维度上分片,每设备 FLOPs = $2BDF / (X \times Y)$。
注意总实际 FLOPs = 每设备 FLOPs × 总设备数 = $\frac{2BDF}{XY} \times XYZ = 2BDF \times Z$,与上面一致。
Q3:高维张量收缩
$A[I,J,K,L] \times B[I,J,M,N,O] \rightarrow C[K,L,M,N,O]$ 需要多少 FLOPs?
点击查看答案
- 收缩维度(在两个输入中但不在输出中):I, J
- 非收缩维度(在输出中):K, L, M, N, O
- 没有 batch 维度
即所有维度的乘积 × 2。如果有 batch 维度(同时出现在两个输入和输出中),该维度也只计一次。
Q4:Self-Attention 的算术强度
给出 self-attention(不含 QKVO 投影)的算术强度,作为 Q 长度 $T$ 和 KV 长度 $S$ 的函数。在什么上下文长度下 attention 变成 compute-bound?
点击查看答案
使用 Flash Attention 时,self-attention 的数据加载量为 Q 和 KV 的输入输出:
\[\text{Bytes} = 2 \times \text{sizeof}(Q) + 2 \times \text{sizeof}(\text{K or V}) = 4BTNH + 4BSKH = 4BHK(TG + S)\]其中 $G = H/\text{Kv_heads}$ 是每 KV 组的 Q head 数。总 FLOPs = $4BTSNH$。
\[\text{AI} = \frac{4BTSKGH}{4BHK(TG + S)}\]Prefill($S = T$):$\text{AI} = \frac{T \cdot G}{G + 1} \approx T$(当 $G$ 较大时)。当 $T > 240$ 时即 compute-bound。
Generation($T = 1$):$\text{AI} = \frac{SG}{G + S} \rightarrow G$(当 $S \gg G$)。由于 $G$ 通常很小(MHA: $G=1$, GQA: $G=8$),generation 阶段永远 memory-bound。
注意 GQA 增大 $G$ 使得 generation 更接近 compute-bound,这是 GQA 的一个额外好处。
Q5:Attention FLOPs 等于投影 FLOPs 的交叉点
在什么序列长度下,dot-product attention FLOPs 等于 QKVO 投影 FLOPs?
点击查看答案
\[12BT^2NH = 24BTDNH\] \[T = 2D\]对于 $D = 4096$,这是 $T = 8192$。
这告诉我们,在大多数合理的上下文长度下,matmul(投影)FLOPs 大于 attention(dot-product)FLOPs。
Q6:重计算(Remat)的额外 FLOPs
假设我们只保存 Transformer 每层中 7 个主要 matmul 的输出(Q, K, V, O 投影 + 3 个 FFN 矩阵),反向传播需要多少额外的重计算 FLOPs?
点击查看答案
保存了 7 个 matmul 输出后,反向传播需要重新计算的是 attention 中的两个 dot-product matmul:
\[QK^T \quad \text{和} \quad \text{softmax}(QK^T) \cdot V\]每个是 $[T, T]$ 的 matmul,batched over $B$ 和 $N$ heads,每个的 FLOPs = $2BT^2NH$。
\[\text{额外 FLOPs} = 4BT^2NH\]此外还有一些较小的重计算:
- LayerNorm 等 $O(BTD)$ 操作(用于计算 $\frac{\partial L}{\partial W_{\text{In1}}}$ 和 $\frac{\partial L}{\partial W_{\text{In2}}}$)
- SwiGLU 激活函数 $O(BTF)$(用于计算 $\frac{\partial L}{\partial W_{\text{Out}}}$)
但这些远小于 dot-product attention 的重计算开销。
Q7:DeepSeek-V3 的硬件利用率
DeepSeek-V3 在 14.8T tokens 上训练了 2.79M H800 GPU-hours(论文)。已知其激活参数量为 37B,估算硬件利用率。(提示:使用 FP8 FLOPs,无结构化稀疏。)
点击查看答案
Step 1:H800 的 FP8 性能
H800 的 FP8 性能(含结构化稀疏)为 3,026 TFLOPs/s,不含稀疏通常为一半:$1.513 \times 10^{15}$ FLOPs/s。
Step 2:总可用 FLOPs
\[2.79 \times 10^6 \text{ GPU-hours} \times 1.513 \times 10^{15} \text{ FLOPs/s} \times 3600 \text{ s/h} = 1.52 \times 10^{25} \text{ FLOPs}\]Step 3:理论所需 FLOPs
\[6 \times 37 \times 10^9 \times 14.8 \times 10^{12} = 3.3 \times 10^{24} \text{ FLOPs}\]Step 4:利用率
\[\frac{3.3 \times 10^{24}}{1.52 \times 10^{25}} = \textbf{21.7\%}\]约 22% 的硬件利用率。这看起来不高,但对于 MoE 模型来说是合理的——大量时间花在 AllToAll 通信和 expert 路由上。
Q8:MoE 模型的 Compute-Bound Batch Size
MoE 模型有 $E$ 个 expert,每个 token 激活 $k$ 个。int8 权重在 TPU v5e 上,需要多大的 batch size 才能 compute-bound?对于 DeepSeek-V3($E=256$, $k=8$),这个数字是多少?
点击查看答案
每个权重矩阵需要加载 $E \times D \times F$ 字节(int8),FLOPs 为 $2k \times B \times D \times F$。
算术强度 = $\frac{2kBDF}{EDF} = \frac{2kB}{E}$。
要 compute-bound(AI > 240,bf16 运算在 TPU v5e 上):
\[\frac{2kB}{E} > 240 \implies B > \frac{120E}{k}\]DeepSeek-V3:$B > 120 \times 256 / 8 = \textbf{3840}$ tokens。
这意味着在推理的 generation 阶段,需要同时 batch 3840 个 token(即 3840 个并发请求)才能充分利用计算单元。这就是为什么 MoE 模型的推理需要非常大的 serving 规模才能高效。
关键要点
- Transformer 参数量 ≈ $L \times (4D^2 + 3DF) + VD$,其中 FFN 占 3/4,Attention 占 1/4
- matmul FLOPs = $2 \times$ 所有维度的乘积(收缩维度和 batch 维度只计一次)
- 前向 FLOPs ≈ $2NP$,训练总 FLOPs = $6NP$(前向 2 + 反向 4)
- Attention FLOPs 仅当 $T > 8D$ 时才开始主导;大多数场景下 MLP 主导
- Dot-product attention FLOPs 在 $T = 2D$ 时等于 QKVO 投影 FLOPs
- GQA 将 attention 参数从 $4D^2$ 减少到 $2D(H + \text{Kv_heads})K$
- 训练内存 ≈ 每参数 12 bytes(权重 2 + 梯度 2 + Adam 状态 8),不含激活
- 无 checkpointing 的激活内存可达 84 TB;block remat 将 FLOPs 增加到 $8ND$ 但大幅减少内存
- KV cache/序列 = $2 \times S \times L \times \text{Kv_heads} \times K \times \text{sizeof(dtype)}$
- MoE:参数量 ×E,FLOPs ×k,compute-bound 需要 $B > 120E/k$
- Flash Attention:不改变 FLOPs 总量,但通过 online softmax 将 HBM I/O 从 $O(S^2)$ 降到 $O(S)$
- Flash Attention 使 causal masking 的 FLOPs 减半真正实现(跳过全上三角 chunk)