本章目标:掌握 LLM 训练的四大并行策略,理解每种策略的通信开销推导、适用场景和最优组合方式。
对应原书:Chapter 5 (How to Parallelize a Transformer for Training)
改写范围:原书主线是 TPU 上的 DP/FSDP/TP/PP roofline;Megatron-LM 3D 并行配置是面向 GPU 训练的实践补充。 建议时间:Day 7-8, 约 5-6 小时(含习题)
8.1 Scaling 的目标与符号约定
Strong scaling 的定义:设备数增加 N 倍,训练吞吐也提升 N 倍。
单芯片性能取决于 memory bandwidth 和 FLOPs 的平衡(Roofline),而集群级性能取决于能否用有用的 FLOPs 来掩盖芯片间通信。这是非平凡的:增加芯片数会增加通信负载,同时减少每设备的计算量。
符号约定
| 符号 | 含义 |
|---|---|
| D | d_model(隐藏维度/残差流维度) |
| F | d_ff(FFN 中间维度) |
| B | Batch 维度(总 token 数,非 sequence 数) |
| T | 序列长度 |
| L | 层数 |
| C | 每芯片 FLOPs/s |
| W | 网络带宽(双向),如 $W_{\text{ici}}$, $W_{\text{dcn}}$ |
| X | FSDP/DP 方向的芯片数 |
| Y | TP 方向的芯片数 |
| N | 总芯片数,$N = X \times Y$ |
简化模型
为了分析方便,我们将 Transformer 近似为一叠 MLP 块(因为对于大模型,attention 只占 FLOPs 的一小部分)。每层包含:
- W_in:
bf16[D, F](上投影) - W_out:
bf16[F, D](下投影) - 输入 In:
bf16[B, D]
前向传播:In[B, D] → Tmp[B, F] = In × W_in → Out[B, D] = Tmp × W_out
每层 FLOPs = $4BDF$(前向 2 个 matmul,各 $2BDF$)
反向 FLOPs = $8BDF$(4 个 matmul)
总 FLOPs/层 = $12BDF$
📋 背景知识:梯度下降与反向传播
对于 $Y = X \cdot A$ 的矩阵乘法:
- $\frac{\partial L}{\partial A} = X^T \cdot \frac{\partial L}{\partial Y}$(权重梯度,用于更新参数)
- $\frac{\partial L}{\partial X} = \frac{\partial L}{\partial Y} \cdot A^T$(激活梯度,用于传播到前一层)
所以反向传播中每个 matmul 产生 2 个新的 matmul(dW 和 dX),加上前向的 1 个,每层共 3 个 matmul × 2(W_in 和 W_out)= 6 个 matmul。但 dW_in 和 dW_out 的 FLOPs 与前向相同,所以反向 = 2× 前向。
8.2 Data Parallelism(DP)
分片方式:
\[\text{In}[B_X, D] \cdot_D W_{\text{in}}[D, F] \cdot_F W_{\text{out}}[F, D] \rightarrow \text{Out}[B_X, D]\]激活值沿 batch 维度分片,权重和优化器状态在每个设备上完全复制。
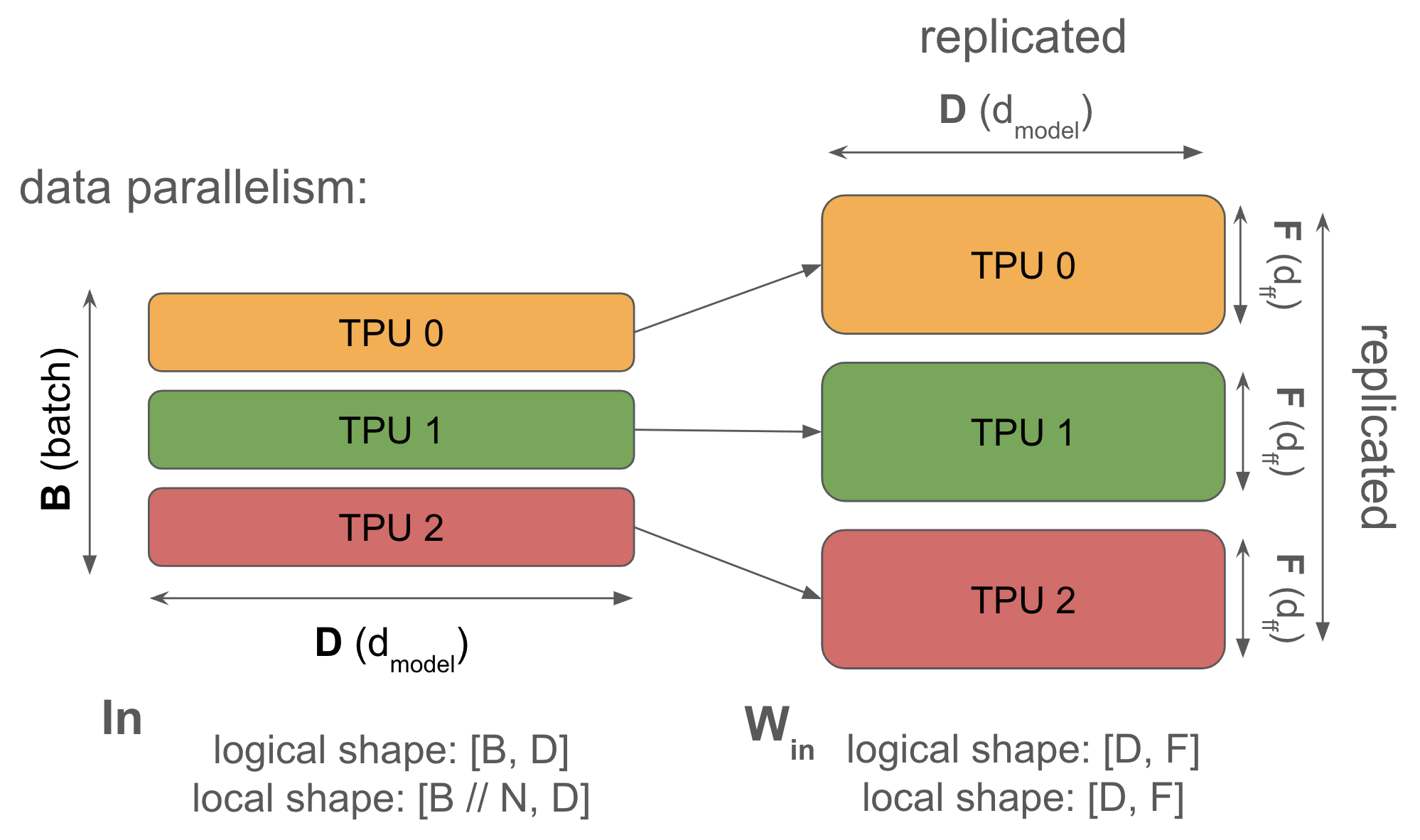
算法
前向传播(无通信):
Tmp[B_X, F] = In[B_X, D] × W_in[D, F]Out[B_X, D] = Tmp[B_X, F] × W_out[F, D]Loss[B_X] = ...
反向传播(需要 AllReduce 梯度):
dOut[B_X, D] = ...dW_out[F, D] {U_X} = Tmp[B_X, F] ×_B dOut[B_X, D](每个设备计算局部梯度)dW_out[F, D] = AllReduce(dW_out[F, D] {U_X})(不在关键路径上,可异步)dTmp[B_X, F] = dOut[B_X, D] ×_D W_out[F, D]dW_in[D, F] {U_X} = In[B_X, D] ×_B dTmp[B_X, F]dW_in[D, F] = AllReduce(dW_in[D, F] {U_X})(不在关键路径上,可异步)dIn[B_X, D] = dTmp[B_X, F] ×_F W_in[D, F]
关键观察:前向传播无通信,所有通信都在反向传播。而且 AllReduce 不在关键路径上——可以在计算下一层的同时进行当前层的 AllReduce。
Roofline 分析
设 X 为 DP 的设备数。每层的反向传播中:
计算时间(4 个 matmul,每个 $2BDF$ FLOPs):
\[T_{\text{math}} = \frac{8BDF}{X \cdot C}\]通信时间(2 个 AllReduce,每个 $2DF$ bytes):
\[T_{\text{comms}} = \frac{2 \cdot 2 \cdot 2DF}{W_{\text{ici}}} = \frac{8DF}{W_{\text{ici}}}\]Compute-bound 条件:
\[T_{\text{math}} > T_{\text{comms}} \iff \frac{8BDF}{X \cdot C} > \frac{8DF}{W_{\text{ici}}}\] \[\iff \frac{B}{X} > \frac{C}{W_{\text{ici}}}\]结论:per-device batch size 必须大于硬件的 ICI operational intensity。
对于 TPU v5p:$C / W_{\text{ici}} = 4.6 \times 10^{14} / (2 \times 9 \times 10^{10}) = 2550$
所以 per-device batch size > 2550 tokens 才能 compute-bound。
如果使用 3 个 mesh 轴做 DP,带宽变为 $3 \times W_{\text{ici}}$,临界值降到 $2550 / 3 = 850$。
🔗 与你的联系
这就是为什么 CV 训练中 DP 如此流行——图像分类的 batch size 通常很大(256-4096),per-device batch 轻松超过临界值。但 LLM 训练中,如果 global batch = 2M tokens,用 1000 张卡做 DP,per-device batch = 2000,仍然 compute-bound。
但 DP 的致命问题不是通信,而是内存:每张卡都要存完整模型 + 优化器。
内存分析
每张卡需要存储:
- 参数(bf16):$2P$ bytes(P 是参数数量)
- 梯度(bf16):$2P$ bytes
- Adam 优化器状态(fp32):$8P$ bytes(一阶矩 + 二阶矩)
- 总计:$12P$ bytes
对于 70B 模型:$12 \times 70 \times 10^9 = 840$ GB,需要 11 张 H100(每张 80GB HBM)仅存储参数和优化器,还没算激活值!
Takeaway:纯 DP 能训练的最大模型约为 HBM / 10 参数。对 TPU v5p(96GB HBM)约 9.6B 参数。
8.3 Fully-Sharded Data Parallelism(FSDP / ZeRO-3)
分片方式:
\[\text{In}[B_X, D] \cdot_D W_{\text{in}}[D_X, F] \cdot_F W_{\text{out}}[F, D_X] \rightarrow \text{Out}[B_X, D]\]激活值沿 batch 分片(同 DP),但权重沿同一轴分片,计算前 AllGather,计算后丢弃。
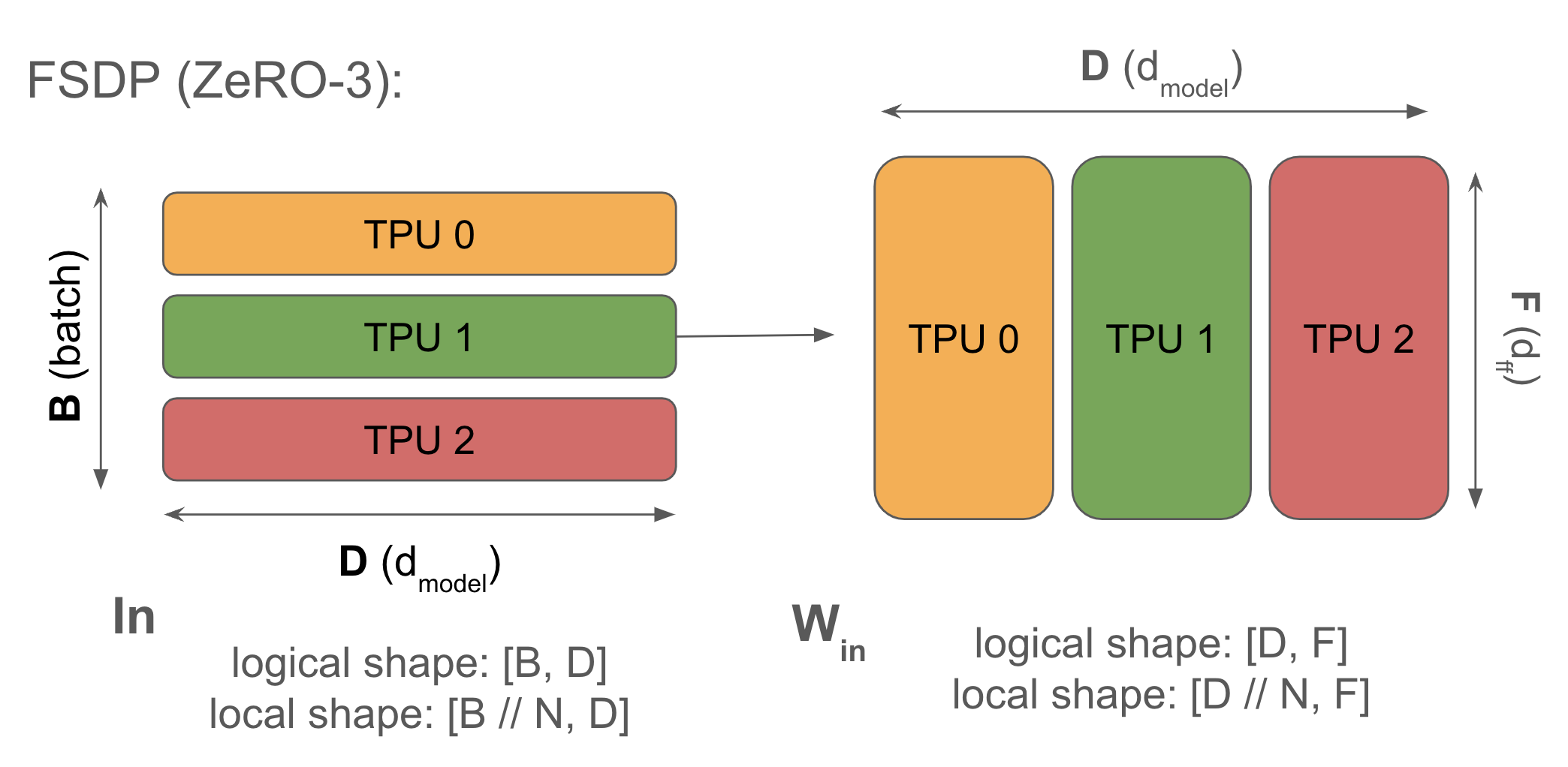
核心思想
DP 中的 AllReduce 可以分解为 AllGather + ReduceScatter。FSDP 的策略是:
- 将权重分片存储(每个设备只存 1/X)
- 前向时 AllGather 权重 → 计算 → 丢弃非本地分片
- 反向时 AllGather 权重 → 计算梯度 → ReduceScatter 梯度(每个设备只保留自己的 1/X)
这样每个设备只需要存储和更新 1/X 的参数和优化器状态。
算法
前向传播:
W_in[D, F] = AllGather(W_in[D_X, F])(可在前一层计算时预取)Tmp[B_X, F] = In[B_X, D] × W_in[D, F](计算后可丢弃 W_in)W_out[F, D] = AllGather(W_out[F, D_X])Out[B_X, D] = Tmp[B_X, F] × W_out[F, D]
反向传播:
dOut[B_X, D] = ...dW_out[F, D] {U_X} = Tmp[B_X, F] ×_B dOut[B_X, D]dW_out[F, D_X] = ReduceScatter(dW_out[F, D] {U_X})(不在关键路径)W_out[F, D] = AllGather(W_out[F, D_X])(可提前做)dTmp[B_X, F] = dOut[B_X, D] ×_D W_out[F, D]dW_in[D, F] {U_X} = dTmp[B_X, F] ×_B In[B_X, D]dW_in[D_X, F] = ReduceScatter(dW_in[D, F] {U_X})W_in[D, F] = AllGather(W_in[D_X, F])(可提前做)dIn[B_X, D] = dTmp[B_X, F] ×_F W_in[D, F]
Roofline 分析
前向传播(每层):
- 计算:$\frac{4BDF}{X \cdot C}$
- 通信(2 个 AllGather,各 $2DF$ bytes):$\frac{4DF}{W_{\text{ici}}}$
反向传播类似,总时间:
\[T = \max\left(\frac{4BDF}{X \cdot C}, \frac{4DF}{W_{\text{ici}}}\right)\]Compute-bound 条件:
\[\frac{B}{X} > \frac{C}{W_{\text{ici}}}\]和 DP 完全一样! 因为 AllReduce = AllGather + ReduceScatter,通信量相同。
但 FSDP 的内存节省是巨大的:
| 组件 | DP(每卡) | FSDP(每卡) |
|---|---|---|
| 参数 | $2P$ | $2P/X$ |
| 梯度 | $2P$ | $2P/X$ |
| 优化器 | $8P$ | $8P/X$ |
| 总计 | $12P$ | $12P/X$ |
对于 70B 模型,128 张卡的 FSDP:每卡只需 $840 / 128 = 6.6$ GB 存储参数和优化器!
📋 背景知识:ZeRO 的三个阶段
DeepSpeed 的 ZeRO 论文定义了三个级别:
- ZeRO-1:只分片优化器状态 → 每卡 $2P + 2P + 8P/X = 4P + 8P/X$
- ZeRO-2:分片优化器 + 梯度 → 每卡 $2P + (2P + 8P)/X$
- ZeRO-3:分片所有(= FSDP)→ 每卡 $12P/X$
ZeRO-3 通信量最大(前向也要 AllGather),但内存节省最多。
Takeaway:FSDP 和 DP 有相同的 roofline(per-device batch > 2550),但内存减少 X 倍。这是”免费的午餐”——只要你本来就 compute-bound,升级到 FSDP 没有性能损失。
8.4 Tensor Parallelism(TP / Model Parallelism)
分片方式:
\[\text{In}[B, D_Y] \cdot_D W_{\text{in}}[D, F_Y] \cdot_F W_{\text{out}}[F_Y, D] \rightarrow \text{Out}[B, D_Y]\]激活值沿 D(d_model)分片,权重沿 F(d_ff)分片。这里用 Y 表示 TP 维度(为了后面和 FSDP 组合)。
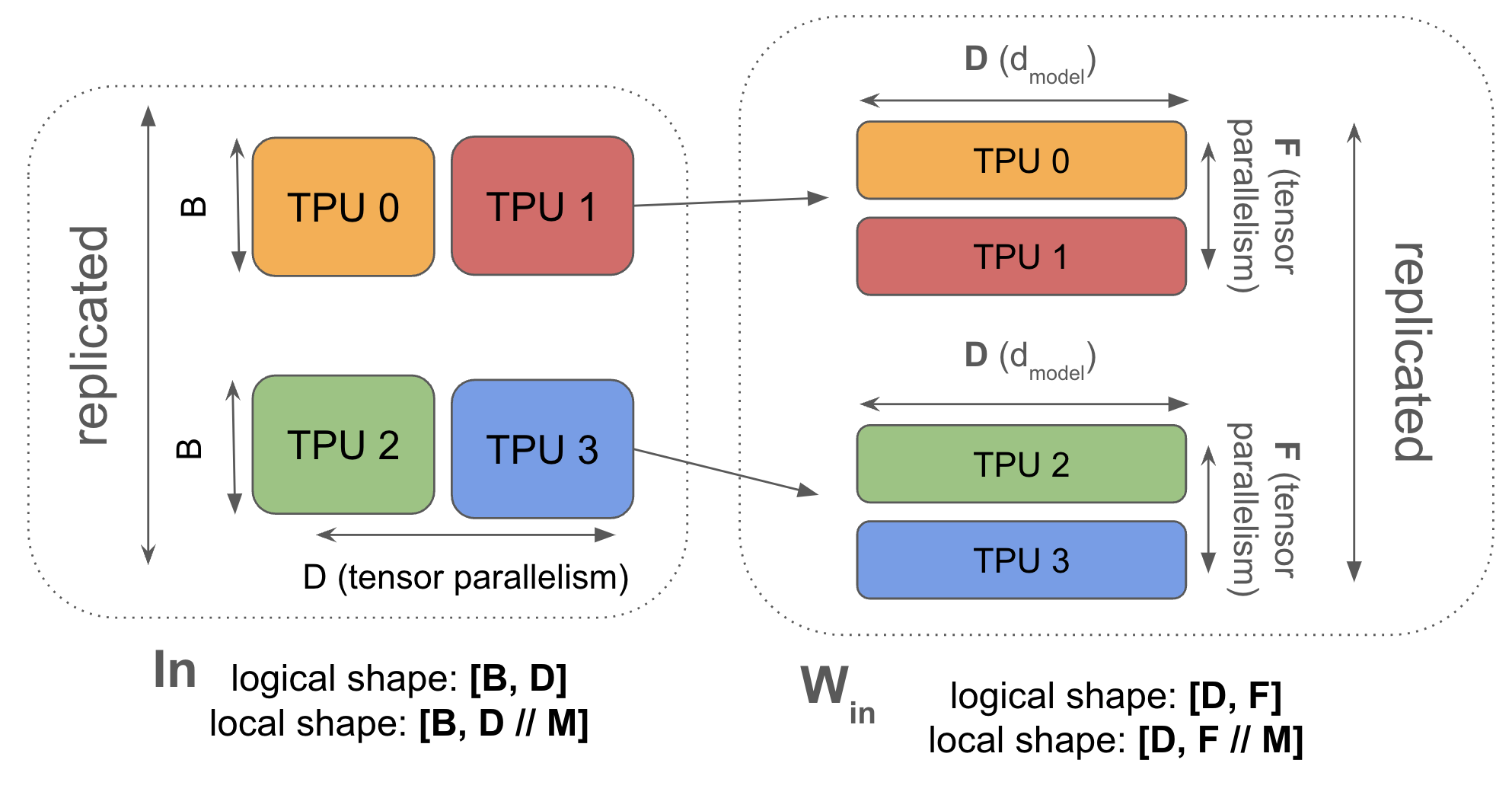
核心思想
回顾第 6 章的分片矩阵乘法:当矩阵沿某个维度分片时,需要通信来聚合结果。TP 的策略是:
- 将 W_in 沿输出维度(F)分片 → 每个设备计算
In × W_in_local,得到Tmp[B, F_Y] - 将 W_out 沿输入维度(F)分片 → 每个设备计算
Tmp_local × W_out_local,得到部分和 - ReduceScatter 聚合部分和,得到
Out[B, D_Y]
关键:TP 将单个 matmul 切分到多个设备,而 DP/FSDP 是将不同的 batch 分配到不同设备。
算法
前向传播:
In[B, D] = AllGather(In[B, D_Y])(在关键路径上)Tmp[B, F_Y] = In[B, D] × W_in[D, F_Y](无通信,因为 D 维度未分片)Out[B, D] {U_Y} = Tmp[B, F_Y] × W_out[F_Y, D](每个设备得到部分和)Out[B, D_Y] = ReduceScatter(Out[B, D] {U_Y})(在关键路径上)
反向传播:
dOut[B, D_Y] = ...dOut[B, D] = AllGather(dOut[B, D_Y])(在关键路径上)dW_out[F_Y, D] = Tmp[B, F_Y] ×_B dOut[B, D]dTmp[B, F_Y] = dOut[B, D] ×_D W_out[F_Y, D]In[B, D] = AllGather(In[B, D_Y])(可与前向的 AllGather 共享)dW_in[D, F_Y] = dTmp[B, F_Y] ×_B In[B, D]dIn[B, D] {U_Y} = dTmp[B, F_Y] ×_F W_in[D, F_Y]dIn[B, D_Y] = ReduceScatter(dIn[B, D] {U_Y})(在关键路径上)
注意:TP 的通信在关键路径上,不能异步!这和 DP/FSDP 不同。
Roofline 分析
前向传播(每层):
- 计算:$\frac{4BDF}{Y \cdot C}$
- 通信(AllGather
In[B, D]+ ReduceScatterOut[B, D]):$\frac{2 \cdot 2BD}{W_{\text{ici}}} = \frac{4BD}{W_{\text{ici}}}$
Compute-bound 条件:
\[\frac{4BDF}{Y \cdot C} > \frac{4BD}{W_{\text{ici}}}\] \[\iff \frac{F}{Y} > \frac{C}{W_{\text{ici}}}\] \[\iff F > Y \cdot \frac{C}{W_{\text{ici}}}\]对于 TPU v5p:$F > Y \times 2550$
如果使用多个 mesh 轴($M_Y$ 个),带宽增加,条件变为:$F > Y \times 2550 / M_Y$
关键观察:TP 的 roofline 不依赖 batch size,只依赖模型维度 F!
Takeaway:TP 在 $Y > M_Y \cdot F / 2550$ 时变成 communication-bound。对大多数模型,这意味着 TP ≤ 8-16。
实例
| 模型 | F | 最大 TP(单轴) | 最大 TP(2轴) |
|---|---|---|---|
| LLaMA 7B | 11,008 | 4 | 8 |
| LLaMA 70B | 28,672 | 11 | 22 |
| Gemma 7B | 49,152 | 19 | 38 |
实践中,TP 通常限制在 8(单节点内的 GPU 数),因为:
- 节点内有 NVLink 高带宽(~450 GB/s)
- 跨节点的 InfiniBand 带宽低得多(~50 GB/s)
🛠️ 实践:Megatron-LM 的 Tensor Parallelism
--tensor-model-parallel-size 8 # 通常 = 节点内 GPU 数Megatron 的 TP 实现细节:
- Column Parallel:W_in 按列切分,输出是
[B, F_Y],无需通信- Row Parallel:W_out 按行切分,输出需要 AllReduce
- 优化:将 FFN 的两个 matmul 组合,只在最后做一次 AllReduce
Sequence Parallelism(Megatron v2):
- TP 只分片了 matmul,但 LayerNorm/Dropout 仍对完整激活操作
- SP 将这些操作也沿序列维度分片
- 使用 AllGather(TP → SP)和 ReduceScatter(SP → TP)过渡
- 激活内存减少到 1/TP
--sequence-parallel启用
8.5 混合 FSDP + Tensor Parallelism
分片方式:
\[\text{In}[B_X, D_Y] \cdot_D W_{\text{in}}[D_X, F_Y] \cdot_F W_{\text{out}}[F_Y, D_X] \rightarrow \text{Out}[B_X, D_Y]\]同时沿 X(FSDP)和 Y(TP)两个轴分片。
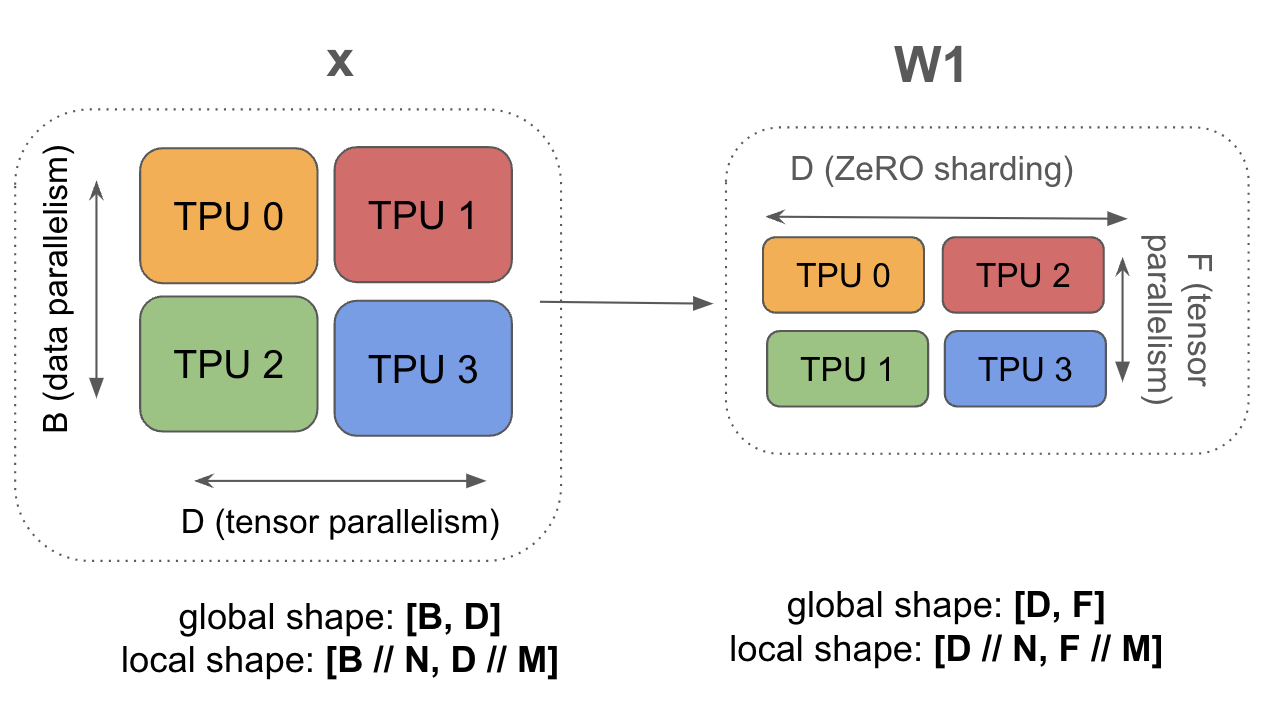
为什么要混合?
关键洞察:
- FSDP 移动权重(AllGather
W[D_X, F_Y]),通信量与 batch size 无关 - TP 移动激活(AllGather
In[B_X, D_Y]),通信量与 batch size 成正比
当 batch size 减小时:
- FSDP 的通信量不变,但计算量减少 → 更容易 communication-bound
- TP 的通信量也减少 → 相对更划算
所以混合策略可以在更小的 batch size 下保持 compute-bound。
算法
前向传播:
In[B_X, D] = AllGather_Y(In[B_X, D_Y])(TP 的 AllGather)W_in[D, F_Y] = AllGather_X(W_in[D_X, F_Y])(FSDP 的 AllGather)Tmp[B_X, F_Y] = In[B_X, D] × W_in[D, F_Y]W_out[F_Y, D] = AllGather_X(W_out[F_Y, D_X])Out[B_X, D] {U_Y} = Tmp[B_X, F_Y] × W_out[F_Y, D]Out[B_X, D_Y] = ReduceScatter_Y(Out[B_X, D] {U_Y})
反向传播类似,有更多的 AllGather 和 ReduceScatter,但每个的大小都更小。
Roofline 分析
设总设备数 $N = X \times Y$,$M_X$ 和 $M_Y$ 是各自使用的 mesh 轴数。
前向传播(每层):
- 计算:$\frac{4BDF}{N \cdot C}$
- FSDP 通信(AllGather 权重):$\frac{4DF}{Y \cdot W_{\text{ici}} \cdot M_X}$
- TP 通信(AllGather 激活):$\frac{4BD}{X \cdot W_{\text{ici}} \cdot M_Y}$
总通信时间(假设可以重叠):
\[T_{\text{comms}} = \max\left(\frac{4DF}{Y \cdot W_{\text{ici}} \cdot M_X}, \frac{4BD}{X \cdot W_{\text{ici}} \cdot M_Y}\right)\]最优 X 和 Y
为了最小化通信时间,我们希望两项相等:
\[\frac{DF}{Y \cdot M_X} = \frac{BD}{X \cdot M_Y}\] \[\iff \frac{F}{Y \cdot M_X} = \frac{B}{X \cdot M_Y}\] \[\iff X = Y \cdot \frac{B \cdot M_X}{F \cdot M_Y}\]由于 $N = X \times Y$,我们得到:
\[X_{\text{opt}} = \sqrt{\frac{B}{F} \cdot \frac{M_X}{M_Y} \cdot N}\] \[Y_{\text{opt}} = \sqrt{\frac{F}{B} \cdot \frac{M_Y}{M_X} \cdot N}\]Compute-bound 条件
将最优的 X 和 Y 代入,要求计算时间 > 通信时间:
\[\frac{4BDF}{N \cdot C} > \frac{4D}{W_{\text{ici}}} \cdot \max\left(\frac{F}{Y_{\text{opt}} \cdot M_X}, \frac{B}{X_{\text{opt}} \cdot M_Y}\right)\]由于我们选择了让两项相等的 X 和 Y,可以简化为:
\[\frac{BF}{N \cdot C} > \frac{1}{W_{\text{ici}}} \cdot \sqrt{\frac{BF}{M_X M_Y N}}\] \[\iff \sqrt{BF} > \frac{C}{W_{\text{ici}}} \cdot \sqrt{\frac{N}{M_X M_Y}}\] \[\iff \frac{B}{N} > \frac{C^2}{W_{\text{ici}}^2 \cdot M_X M_Y \cdot F}\]对于 TPU v5p($C / W_{\text{ici}} = 2550$,$M_X M_Y \approx 2$):
\[\frac{B}{N} > \frac{2550^2}{2F} = \frac{3.25 \times 10^6}{F}\]对于 F = 30,000:$B/N > 108$
Takeaway:混合 FSDP + TP 允许 per-device batch size 低至 ~100,比纯 FSDP 的 ~850 低约 8 倍。
实例:4×4×4 TPU slice
设 N = 64,B = 48,000,F = 32,768,$M_X = M_Y = 1$:
\[X_{\text{opt}} = \sqrt{\frac{48000}{32768} \cdot 64} \approx 8.7 \rightarrow 8\] \[Y_{\text{opt}} = 64 / 8 = 8\]所以最优配置是 FSDP=8, TP=8。
下图展示了不同策略在不同 batch size 下的 FLOPs/Comms 比值:
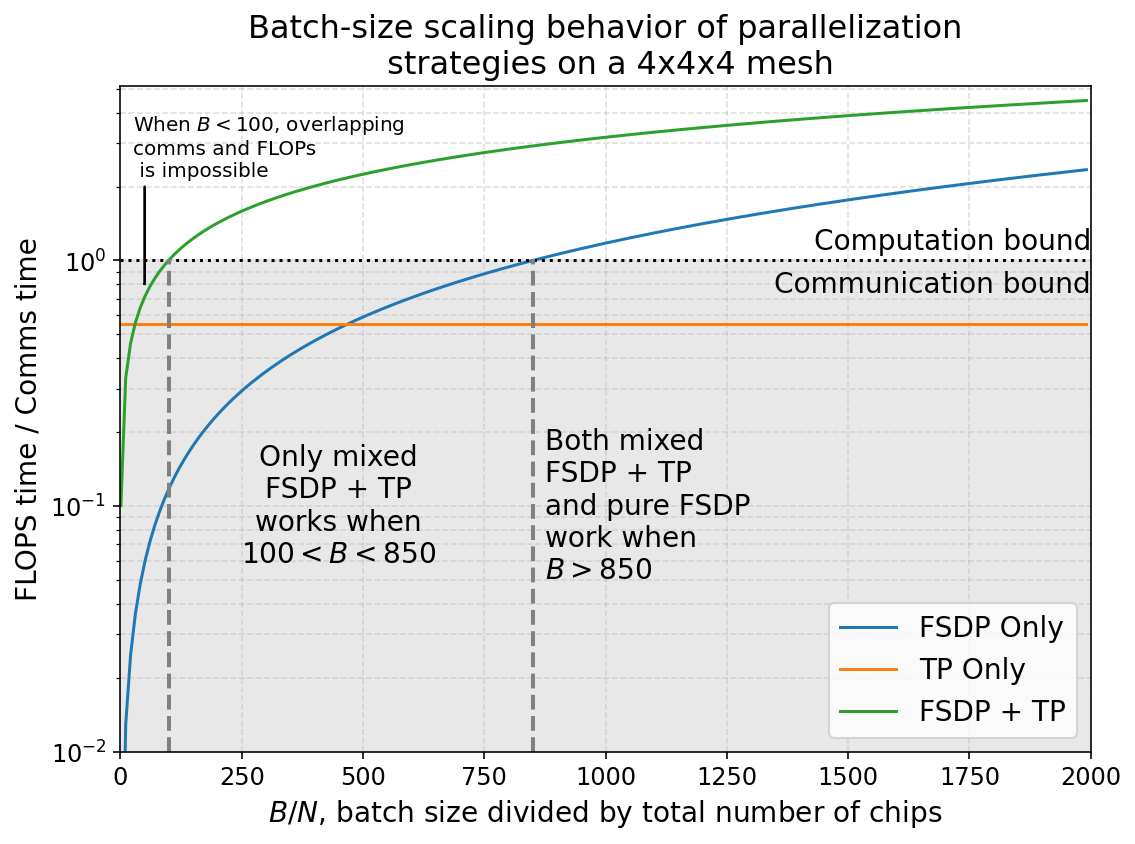
- 纯 TP:比值恒定(不依赖 B)
- 纯 FSDP:比值线性增长(∝ B)
- 混合 FSDP+TP:比值 ∝ √B(介于两者之间)
在中等 batch size(100-850 per device)时,只有混合策略能保持 compute-bound。
8.6 Pipeline Parallelism(PP)
分片方式(滥用符号):
\[\text{In}[L_Z, B, D][i] \cdot_D W_{\text{in}}[L_Z, D, F][i] \cdot_F W_{\text{out}}[L_Z, F, D][i] \rightarrow \text{Out}[L_Z, B, D][i]\]将模型按层维度切分,每个设备负责连续的几层。
核心思想
- 将 L 层分成 Z 组,每组 L/Z 层
- 将 batch 切成 M 个 micro-batch
- Micro-batch 按流水线顺序经过各 stage
Bubble 问题
流水线有”填充”和”排空”阶段,期间部分设备空闲。
\[\text{Bubble ratio} = \frac{Z - 1}{M + Z - 1}\]其中 M 是 micro-batch 数。M 越大,bubble 越小,但内存占用越大(需要存储多个 micro-batch 的激活)。
通信分析
PP 的通信非常简单:只需点对点传输激活值。
- 每个 stage 之间传输
In[B_micro, D] - 通信量:$2B_{\text{micro}} \times D$ bytes(前向 + 反向)
- 远小于 TP 和 FSDP 的通信量
但 PP 的问题不是通信量,而是:
- Bubble:设备利用率 < 100%
- 延迟:跨节点传输的延迟可能很高
- 内存:需要存储多个 micro-batch 的激活
📋 背景知识:为什么需要 Pipeline Parallelism
PP 解决的核心问题:当 TP 已经用满节点内所有卡(TP=8),但模型仍然太大时,PP 可以跨节点扩展而不需要高带宽互联。
代价是 bubble 和内存开销。
Virtual Pipeline Parallelism
Megatron 的优化:将每个 stage 的层交错分布。
标准 PP:
- Stage 0: 层 0-9
- Stage 1: 层 10-19
- Stage 2: 层 20-29
- Stage 3: 层 30-39
Virtual PP(V=2):
- Stage 0: 层 0-4, 20-24
- Stage 1: 层 5-9, 25-29
- Stage 2: 层 10-14, 30-34
- Stage 3: 层 15-19, 35-39
Bubble ratio 降低到:
\[\text{Bubble ratio} = \frac{Z - 1}{M \times V + Z - 1}\]🛠️ 实践:Megatron 的 Pipeline Parallelism
--pipeline-model-parallel-size 4 --num-layers-per-virtual-pipeline-stage 1 # Virtual PPDeepSeek-V3 的”无 bubble”流水线:
- 通过精心调度前向、反向(dL/dx)、梯度(dL/dW)三种计算
- 优先执行反向 dL/dx,避免”搁浅” FLOPs
- 实现接近 0% 的 bubble
8.7 跨 Pod 的 Data Parallelism
当训练扩展到多个 Pod 时,Pod 之间通过 DCN(Data Center Network)连接,带宽远低于 ICI。
TPU v5p 的网络层级:
- ICI(芯片间互联):~180 GB/s(双向)per chip
- DCN(数据中心网络):~6.25 GB/s(双向)per chip
策略:
- Pod 内用 TP + FSDP(利用高带宽 ICI)
- Pod 间用纯 DP(通过低带宽 DCN)
Roofline 分析
设 M 为每个 ICI 域的芯片数(如一个 Pod = 8960 芯片)。
跨 Pod 的 DP 需要在 Pod 间做 AllReduce:
- 计算时间:$\frac{8BDF}{N \cdot C}$
- 通信时间(ring AllReduce):$\frac{8DF}{M \cdot W_{\text{dcn}}}$
Compute-bound 条件:
\[\frac{B}{M} > \frac{C}{W_{\text{dcn}}}\]对于 TPU v5p:$C / W_{\text{dcn}} = 4.6 \times 10^{14} / 6.25 \times 10^9 = 73,600$
所以 per-pod batch size > 73,600 tokens 才能 compute-bound。
实例:LLaMA 70B 训练
假设:
- Global batch = 2M tokens
- F = 30,000
- 使用 2 个 TPU v5p Pod(共 17,920 芯片)
Pod 内配置:
- 从 8.5 节知道,最优 FSDP+TP 需要 $B/N > 108$
- 每个 Pod 的 batch = 1M tokens
- 每个 Pod 有 8960 芯片
- Per-device batch = 1M / 8960 = 111 > 108 ✓
Pod 间配置:
- Per-pod batch = 1M > 73,600 ✓
- 所以跨 Pod 的 DP 也是 compute-bound
Takeaway:跨 Pod 的 DP 需要 per-pod batch > ~70k tokens。对于大 batch 训练(如 2M tokens),这通常不是问题。
8.8 Megatron-LM 3D 并行实践
Megatron-LM 是 NVIDIA 开源的大模型训练框架,实现了 TP + PP + DP 的 3D 并行。
配置原则
总设备数 = TP × PP × DP
决策树:
- TP:设置为节点内 GPU 数(通常 8)
- 利用 NVLink 高带宽
- 受限于 $F / TP > 2550$(对 H100)
- PP:设置为让每个 stage 能放进 TP 组
- 如果 TP=8 能放下整个模型 → PP=1
- 否则增加 PP 直到每个 stage 的层数 × TP 能放进内存
- DP:剩余的设备数
- DP = 总设备数 / (TP × PP)
- 调整 global batch size 确保 per-device batch > 临界值
完整配置示例
训练 LLaMA 70B,128 张 H100(16 节点 × 8 卡):
#!/bin/bash
# 模型配置
NUM_LAYERS=80
HIDDEN_SIZE=8192
NUM_ATTENTION_HEADS=64
FFN_HIDDEN_SIZE=28672
# 3D 并行配置
TP=8 # 节点内 NVLink
PP=4 # 跨 4 个节点
# DP=4 自动计算:128 / (8 × 4) = 4
# Batch 配置
MICRO_BATCH_SIZE=1
GLOBAL_BATCH_SIZE=1024 # 总 batch = 1024 sequences
SEQ_LENGTH=4096 # 每个 sequence 4096 tokens
# 总 tokens = 1024 × 4096 = 4,194,304
# Per-device tokens = 4,194,304 / 128 = 32,768 >> 298 ✓
# 内存优化
USE_DISTRIBUTED_OPTIMIZER=true # ZeRO-1 优化器分片
RECOMPUTE_ACTIVATIONS=true # Gradient Checkpointing
SEQUENCE_PARALLEL=true # Sequence Parallelism
# 通信优化
OVERLAP_GRAD_REDUCE=true # 梯度 AllReduce 与反向计算重叠
OVERLAP_PARAM_GATHER=true # 参数 AllGather 与前向计算重叠
# Pipeline 优化
NUM_LAYERS_PER_VIRTUAL_PP_STAGE=1 # Virtual PP
# 启动训练
torchrun \
--nproc_per_node=8 \
--nnodes=16 \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
pretrain_gpt.py \
--tensor-model-parallel-size $TP \
--pipeline-model-parallel-size $PP \
--num-layers $NUM_LAYERS \
--hidden-size $HIDDEN_SIZE \
--num-attention-heads $NUM_ATTENTION_HEADS \
--ffn-hidden-size $FFN_HIDDEN_SIZE \
--micro-batch-size $MICRO_BATCH_SIZE \
--global-batch-size $GLOBAL_BATCH_SIZE \
--seq-length $SEQ_LENGTH \
--use-distributed-optimizer \
--recompute-activations \
--sequence-parallel \
--overlap-grad-reduce \
--overlap-param-gather \
--num-layers-per-virtual-pipeline-stage $NUM_LAYERS_PER_VIRTUAL_PP_STAGE
内存估算
每张 H100(80GB HBM):
- 参数:70B × 2 bytes / (TP × PP) = 70e9 × 2 / 32 = 4.4 GB
- 优化器(分片):70B × 8 bytes / DP = 70e9 × 8 / 4 = 140 GB / 4 = 35 GB
- 激活(Gradient Checkpointing + SP):~20 GB
- 总计:~60 GB < 80 GB ✓
性能估算
假设 MFU = 50%:
- 每张卡有效 FLOPs/s = 1.0e15 × 0.5 = 5e14
- 总有效 FLOPs/s = 128 × 5e14 = 6.4e16
- 每个 token 的 FLOPs = 6 × 70e9 = 4.2e11(前向 + 反向)
- 吞吐 = 6.4e16 / 4.2e11 = 152,381 tokens/s
- 每步时间(1024 seq × 4096 tokens)= 4,194,304 / 152,381 = 27.5 秒
8.9 Worked Problems(习题与详解)
以下习题基于 LLaMA-2 13B:
| 参数 | 值 |
|---|---|
| L(层数) | 40 |
| D(d_model) | 5,120 |
| F(d_ff) | 13,824 |
| H(注意力头数) | 40 |
| V(词表大小) | 32,000 |
Problem 1:参数计数
题目:计算 LLaMA-2 13B 的总参数数量。注意 LLaMA 有 3 个 FFN 矩阵(2 个上投影 + 1 个下投影)。
点击查看答案
- FFN 参数:$3 \times L \times D \times F = 3 \times 40 \times 5120 \times 13824 = 8.5 \times 10^9$
- Attention 参数:$4 \times D \times D \times L = 4 \times 5120 \times 5120 \times 40 = 4.2 \times 10^9$
- Q, K, V 投影各 $D \times D$,输出投影 $D \times D$
- 词表参数:$2 \times V \times D = 2 \times 32000 \times 5120 = 0.33 \times 10^9$
- 输入 embedding + 输出 projection
总计:$8.5 + 4.2 + 0.33 = 13.03 \times 10^9 \approx 13B$ ✓
Problem 2:内存占用
题目:假设用 Adam 训练,参数用 bf16,优化器状态用 fp32。Batch = 16M tokens,使用 gradient checkpointing(每层 checkpoint 3 次)。计算总内存占用。
点击查看答案
参数 + 优化器:
- 参数(bf16):$13 \times 10^9 \times 2 = 26$ GB
- 一阶矩(fp32):$13 \times 10^9 \times 4 = 52$ GB
- 二阶矩(fp32):$13 \times 10^9 \times 4 = 52$ GB
- 小计:130 GB
激活值(checkpoint 后):
- 每层 checkpoint 3 个张量:2 个
[B, F]+ 1 个[B, D] - 每层内存:$2 \times (2 \times B \times F + B \times D) = 2B \times (2F + D)$
- 总激活:$2 \times L \times B \times (2F + D) = 2 \times 40 \times 16 \times 10^6 \times (2 \times 13824 + 5120)$
- $= 1.28 \times 10^9 \times 32768 = 4.19 \times 10^{13}$ bytes = 42 TB
总计:130 GB(参数/优化器)+ 42 TB(激活)≈ 42 TB
激活值占主导!这就是为什么需要分布式训练。
Problem 3:并行策略选择
题目:在 TPU v5p 16×16×16 slice(4096 芯片,393 TB HBM)上训练 LLaMA-2 13B。Batch = 3M tokens,序列长度 32k。
- 能用纯 DP 吗?为什么?
- 能用纯 FSDP 吗?会 communication-bound 吗?
- 应该用混合 FSDP+TP 吗?最优的 X 和 Y 是多少?
点击查看答案
1. 纯 DP:
不能。每张卡需要 130 GB(参数 + 优化器),但 TPU v5p 每张卡只有 96 GB HBM。
2. 纯 FSDP:
内存:
- 参数/优化器:130 GB / 4096 = 32 MB per chip ✓
- 激活(按比例缩放):42 TB × (3M / 16M) / 4096 = 1.9 GB per chip ✓
- 总计:~2 GB per chip « 96 GB ✓
Roofline:
- 临界 per-device batch(3 轴)= 2550 / 3 = 850
- 实际 per-device batch = 3M / 4096 = 732 < 850
- Communication-bound ✗
所以纯 FSDP 内存够,但会 communication-bound。
3. 混合 FSDP+TP:
临界 per-device batch = $2550^2 / (2 \times 13824) = 235$
实际 per-device batch = 732 > 235 ✓
最优配置:
\[X_{\text{opt}} = \sqrt{\frac{3 \times 10^6}{13824} \times 2 \times 4096} = \sqrt{217 \times 4096} \approx 942\]取 X = 1024(2^10),Y = 4096 / 1024 = 4
结论:FSDP=1024, TP=4 是最优配置。
Problem 4:训练时间估算
题目:基于 Problem 3 的配置(FSDP=1024, TP=4),假设 MFU = 40%,估算每个训练步的时间。
点击查看答案
每步 FLOPs:
- 每个 token:$6 \times 13 \times 10^9 = 7.8 \times 10^{10}$ FLOPs
- 每步(3M tokens):$3 \times 10^6 \times 7.8 \times 10^{10} = 2.34 \times 10^{17}$ FLOPs
有效算力:
- 每张 TPU v5p:$4.6 \times 10^{14} \times 0.4 = 1.84 \times 10^{14}$ FLOPs/s
- 总算力:$4096 \times 1.84 \times 10^{14} = 7.54 \times 10^{17}$ FLOPs/s
时间:
\[t = \frac{2.34 \times 10^{17}}{7.54 \times 10^{17}} = 0.31 \text{ 秒} = 310 \text{ ms}\]答案:每步约 310 ms。
关键要点
- DP:激活分片,权重复制,反向 AllReduce 梯度。Per-device batch > 2550 才 compute-bound。
- FSDP:激活 + 权重都分片,内存 ÷ X,roofline 与 DP 相同(免费的内存节省)。
- TP:权重沿 F 分片,激活沿 D 分片,每层都通信。Roofline:$F > Y \times 2550$,通常 TP ≤ 8。
- 混合 FSDP+TP:最优配置 $X_{\text{opt}} = \sqrt{(B/F) \cdot (M_X/M_Y) \cdot N}$,允许 per-device batch 低至 ~100。
- PP:按层分片,通信量小但有 bubble。Virtual PP 可减少 bubble。
- 跨 Pod DP:需要 per-pod batch > 70k tokens。
- Megatron 3D:TP(节点内)+ PP(跨节点)+ DP(全局),配合
--overlap-*优化。 - 内存公式:纯 DP 每卡 12P,FSDP 每卡 12P/X,激活值通常占主导(需 gradient checkpointing)。
进一步阅读
- 原书 Chapter 5: How to Parallelize a Transformer for Training
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Reducing Activation Recomputation in Large Transformer Models(Megatron v2: Sequence Parallelism)
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM(Megatron v3: Pipeline Parallelism)
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- DeepSeek-V3 Technical Report(无 bubble 流水线)
- PyTorch FSDP 文档