本章目标:将前几章的理论应用到具体模型(LLaMA 3)上,做端到端的训练配置推演和成本估算。
对应原书:Chapter 6 (Training LLaMA 3 on TPUs)
改写范围:原书案例基于 TPU;这里保留 LLaMA 3 推演主线,并加入 H100/Megatron 视角的配置和成本讨论。 优先级:⭐⭐ 中 | 建议时间:Day 9, 约 2 小时
9.1 LLaMA 3 的模型规格
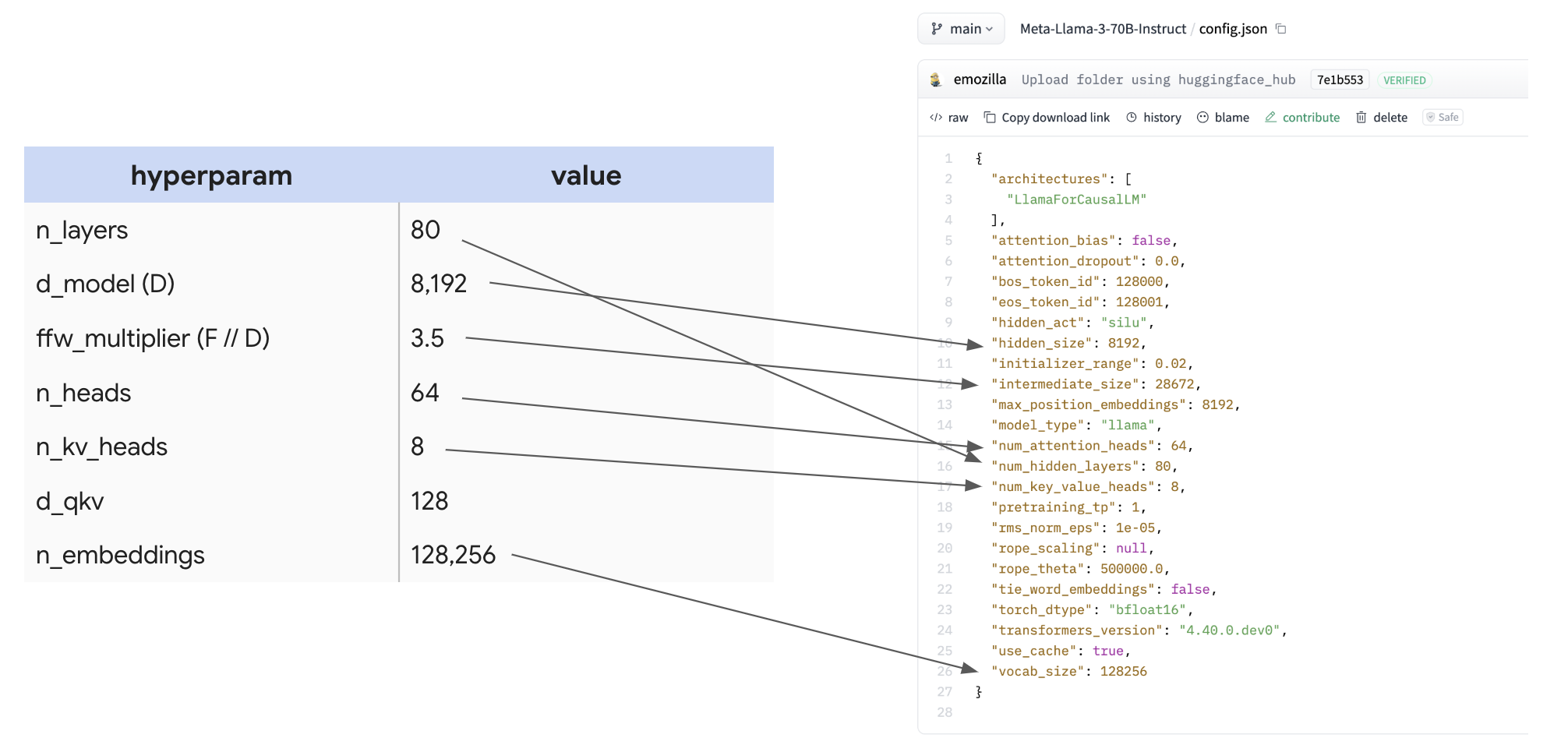
| 参数 | LLaMA 3-8B | LLaMA 3-70B | LLaMA 3-405B |
|---|---|---|---|
| 层数 L | 32 | 80 | 126 |
| 隐藏维度 D | 4096 | 8192 | 16384 |
| FFN 维度 F | 14336 | 28672 | 53248 |
| 注意力头数 H | 32 | 64 | 128 |
| KV 头数 | 8 (GQA) | 8 (GQA) | 8 (GQA) |
| 每头维度 K | 128 | 128 | 128 |
| 词表 V | 128256 | 128256 | 128256 |
| 总参数量 | ~8B | ~70B | ~405B |
9.2 参数量验证
以 LLaMA 3-70B 为例,按组件逐项计算:
| 组件 | 公式 | 参数量 |
|---|---|---|
| FFN (SwiGLU) | $D \times F \times 3 \times L$ = 8192 × 28672 × 3 × 80 | 56.3B |
| Attention | $L \times [2 \times D \times H \times K + 2 \times D \times \text{Kv} \times K]$ = 80 × (2×8192×64×128 + 2×8192×8×128) | 12.1B |
| Vocab (in + out) | $2 \times V \times D$ = 2 × 128256 × 8192 | 2.1B |
| 总计 | 70.4B ✓ |
📋 关键观察:FFN 主导参数量
FFN 的 56.3B 占总参数的 80%。这意味着:
- 在做内存估算时,可以近似只看 FFN
- TP 主要收益来自分片 FFN 的权重
- MoE 只替换 FFN 部分,但这已经是大部分参数
每层参数(详细):
- Attention:Wq[8192, 8192] + Wk[8192, 1024] + Wv[8192, 1024] + Wo[8192, 8192] = 8192 × (8192 + 1024 + 1024 + 8192) = 8192 × 18432 ≈ 151M
- FFN(SwiGLU):3 × [8192, 28672] = 3 × 234M ≈ 704M
- 每层总计:~855M
- 80 层:68.4B + embedding 2.1B ≈ 70.4B ✓
9.3 训练 FLOPs 和时间估算
每 token 的 FLOPs
应用第 7 章的 $6 \times \text{params}$ 规则:
\[\text{FLOPs/token} = 6 \times 70 \times 10^9 = 4.2 \times 10^{11} \approx \text{0.42 TFLOPs/token}\]在单张 H100 上(990 TFLOPs/s bf16),假设 100% 利用率,处理一个 token 需要:
\[t = \frac{4.2 \times 10^{11}}{9.9 \times 10^{14}} \approx 0.42 \text{ ms}\]训练总 FLOPs
假设训练 15T tokens(LLaMA 3 论文的设置):
\[C = 6 \times N \times P = 6 \times 15 \times 10^{12} \times 70 \times 10^9 = 6.3 \times 10^{24} \text{ FLOPs}\]6.3 yottaFLOPs!在单张 H100 上需要 $6.3 \times 10^{24} / 9.9 \times 10^{14} \approx 200$ 年。
训练时间估算
16K H100, MFU=40%:
\[T = \frac{C}{\text{GPU数} \times \text{FLOPs/s} \times \text{MFU}} = \frac{6.3 \times 10^{24}}{16000 \times 9.9 \times 10^{14} \times 0.4} = 10^6 \text{ s} \approx \textbf{11.5 天}\]📋 背景知识:MFU(Model FLOPs Utilization)
MFU 衡量的是硬件 FLOPs 中有多少比例在做”有用计算”(模型前向+反向传播的矩阵乘法)。
\[\text{MFU} = \frac{\text{实际模型 FLOPs/s}}{\text{硬件峰值 FLOPs/s}}\]
MFU 不包含:通信时间、pipeline bubble、激活重计算的 FLOPs、内存带宽等待时间。
MFU 范围 含义 50-60% 优秀(顶级训练框架 + 最优配置) 40-50% 良好(大多数生产训练) 30-40% 一般(有优化空间) < 30% 差(通信瓶颈或配置问题)
最少需要多少 GPU?
💡 Pop Quiz:内存决定下限
LLaMA 3-70B 训练的最少 GPU 数量是多少?(假设 bf16 参数 + fp32 Adam + 每层 4 个 gradient checkpoint,batch size = 4M tokens)
点击查看答案
组件 公式 大小 参数 (bf16) 2 × 70B 140 GB Adam 状态 (fp32) 8 × 70B 560 GB Gradient Checkpoints $2 \times D \times B \times 4 \times L$ = 2 × 8192 × 4M × 4 × 80 20.9 TB 总计 ~21.6 TB Gradient checkpoint 主导内存!H100 有 80 GB HBM,需要至少 $21.6 \text{ TB} / 80 \text{ GB} = 270$ 张。
但 270 张 GPU 训练需要 $11.5 \times 16000 / 270 \approx 680$ 天 ≈ 将近 2 年。所以用大集群不是因为内存不够,而是需要更多 FLOPs 来缩短训练时间。
9.4 分片策略推演
📋 背景知识:选择分片策略的思路
选择 TP/PP/DP 组合时的核心原则:
- 先看内存:能不能放下?(参数 + 优化器 + 激活值)
- 再看通信:是否 compute-bound?(第 8 章的公式)
- 最后调优:micro-batch size、重计算策略、通信重叠
目标:在满足内存约束的前提下,最大化 MFU。
Step 1:能否用纯 DP/FSDP?
内存分析:
70B 模型训练需要的”静态”内存(不含激活):
- 参数 (bf16):140 GB
- 梯度 (bf16):140 GB
- Adam 状态 (fp32):560 GB
- 小计:840 GB
H100 有 80 GB HBM。纯 DP 需要每卡都存完整的参数+优化器 = 840 GB → 不可能。
使用 FSDP(ZeRO-3)分片参数和优化器:每卡 840/N GB。
- N=16:52.5 GB/卡 → 可以放下参数,但激活值没有空间
- N=32:26.3 GB/卡 → 合理,有空间给激活值
通信分析:
回顾第 8 章:FSDP 在 per-device batch size < $C/W$ 时变成通信瓶颈。
对于 GPU(H100):
- NVLink 带宽(节点内):~900 GB/s → $C/W \approx 990 \times 10^{12} / (900 \times 10^9) \approx 1100$
- IB 带宽(节点间):~400 GB/s → $C/W \approx 2475$
如果用 128 卡 FSDP,batch size = 4M tokens:per-device batch = $4M / 128 = 31250$ → 远大于 1100,compute-bound。
但问题是——128 卡全部用 FSDP 意味着跨节点通信。如果 FSDP 跨 16 个节点(每节点 8 卡),则需要节点间 AllGather 权重,带宽只有 ~400 GB/s(IB),而不是 900 GB/s(NVLink)。
结论:纯 FSDP 在 128-256 卡时可行但不是最优——跨节点通信代价较高。
Step 2:加入 TP 减少通信
TP 在节点内使用 NVLink(900 GB/s),通信量是激活而非权重。回顾 TP 的通信瓶颈条件:
\[F > Y \times \frac{C}{W_{\text{NVLink}}}\] \[28672 > Y \times 1100 \implies Y < 26\]TP=8(一个节点内)完全可行,远未到通信瓶颈。
Step 3:确定 PP
TP=8 后,每卡参数内存 = 140 GB / 8 = 17.5 GB。加上优化器(使用 distributed-optimizer 在 DP 维度分片):
使用 128 卡(16 节点),TP=8:
- DP 维度 = 128 / 8 = 16(如果 PP=1)
- 每卡优化器 = 560 GB / 16 / 8 (TP) = 4.4 GB(distributed-optimizer 在 TP×DP 全维度分片)
- 每卡总静态内存 ≈ 17.5 + 4.4 ≈ 22 GB → 余下 ~58 GB 给激活值 → 足够
PP=1 可能就够了! 但如果 batch size 需要很大或激活内存紧张,可以 PP=2:
方案 A(推荐):TP=8, PP=1, DP=16 (128 卡)
方案 B(保守):TP=8, PP=2, DP=8 (128 卡)
Step 4:通信分析
TP 通信(节点内 NVLink,900 GB/s):
- 每层 2 次 AllReduce(前向 1 次 AG+RS,反向 2 次 AG+RS)
- 每次通信量:$2 \times B_{\text{local}} \times D$ bytes = $2 \times (4M/16) \times 8192 = 4$ MB
- 在 900 GB/s NVLink 上:4 MB / 900 GB/s ≈ 4.4 μs → 完全被计算掩盖
DP 通信(跨节点 IB,~400 GB/s):
- 梯度 ReduceScatter + 参数 AllGather
- 通信量 ∝ 权重大小 / TP = 140 GB / 8 = 17.5 GB
- 但可以和反向计算完全重叠(
--overlap-grad-reduce)
PP 通信(如果使用,跨节点 IB):
- 每 micro-batch 传输
bf16[micro_bs × seq_len, D] - 通信量很小,通常不是瓶颈
💡 Pop Quiz:混合 FSDP+TP 的最优比例
如果有 N=8960 张 TPU v5p($C = 4.6 \times 10^{14}$, $W_{\text{ICI}} = 1.8 \times 10^{11}$),batch size = 4M tokens,训练 LLaMA 3-70B($F = 28672$),最优的 FSDP/TP 配比是什么?
点击查看答案
使用第 8 章的 $X_{opt}$ 公式:
\[X_{opt} = \sqrt{\frac{B \cdot M_X}{F \cdot M_Y} \cdot N} = \sqrt{\frac{4.19 \times 10^6 \times 2}{28672 \times 1} \times 8960} \approx 1618\]
取最近的 2 的幂:FSDP ≈ 2048, TP ≈ 4。
验证 per-chip batch size:$4.19M / 8960 \approx 468 > \alpha^2 / (2F) = 2550^2 / (2 \times 28672) = 113$ → compute-bound ✓
</details>
GPU vs TPU 的分片策略对比
原书以 TPU v5p 为平台,但核心思路对 GPU 同样适用。主要区别在于拓扑:
| 特性 | TPU v5p Pod (8960 chips) | GPU H100 集群 (128-16K) |
|---|---|---|
| 节点内互联 | ICI 3D Torus (~180 GB/s/chip) | NVLink (~900 GB/s/GPU) |
| 节点间互联 | DCN (~6.25 GB/s/chip) | IB (~50 GB/s/GPU) |
| TP 部署 | ICI 域内(同一 pod) | 节点内 NVLink(8 GPU) |
| DP 部署 | ICI + DCN | IB 跨节点 |
| PP 需求 | 较少(ICI 带宽高) | 常用(节点间带宽有限) |
| 拓扑 | 3D Torus | Fat Tree |
GPU 上的关键差异:
- TP 限制在节点内:NVLink 只连接同一节点的 8 GPU,所以 TP 通常最多 8-way
- PP 更常用:GPU 节点间带宽有限,PP 的点对点通信比 FSDP 的 AllGather 更友好
- 跨节点 DP:GPU 的 IB 带宽 (~50 GB/s/GPU) 远低于 TPU 的 ICI (~180 GB/s/chip)
通信瓶颈阈值对比:
| 平台 | FSDP 瓶颈 (B/N >) | TP 最大 Y | FSDP+TP 瓶颈 (B/N >) |
|---|---|---|---|
| TPU v5p (ICI) | 2550 / M_X | F / 2550 ≈ 11 | ~100 |
| H100 (NVLink) | 1100 | F / 1100 ≈ 26 | ~45 |
| H100 (IB, 跨节点) | 2475 | N/A (不跨节点) | ~245 |
GPU 节点内(NVLink)的 C/W 比 TPU ICI 更优(1100 vs 2550),因为 NVLink 带宽极高。但一旦跨节点(IB),条件变得更严格(2475)。这就是为什么 GPU 训练更依赖 PP 来减少跨节点通信。
Pipeline Parallelism 的 Bubble 问题
当使用 PP 时,需要关注 pipeline bubble——pipeline 阶段之间的空闲等待时间。
1F1B 调度(One Forward One Backward):
Stage 0: F0 F1 F2 F3 | B3 B2 B1 B0
Stage 1: F0 F1 F2 F3 | B3 B2 B1 B0
Stage 2: F0 F1 F2 F3 | B3 B2 B1 B0
Stage 3: F0 F1 F2 F3 | B3 B2 B1 B0
^^^^
bubble
Bubble 比例 ≈ $(PP - 1) / (\text{micro-batches} + PP - 1)$
| PP 数 | Micro-batches | Bubble 比例 |
|---|---|---|
| 2 | 8 | 11% |
| 4 | 16 | 16% |
| 8 | 32 | 18% |
| 16 | 64 | 19% |
减少 bubble 的方法:
- 增加 micro-batch 数(但增加内存)
- Interleaved PP:Megatron 的
--num-layers-per-virtual-pipeline-stage将每个 stage 拆成多个虚拟 stage - Zero-bubble PP:DeepSeek-V3 的方案——将 dW 计算与 dx 分离,在 bubble 中执行 dW
🛠️ 实践:Megatron PP 配置
# 基本 PP --pipeline-model-parallel-size 4 --micro-batch-size 1 --global-batch-size 1024 # Interleaved PP (减少 bubble) --pipeline-model-parallel-size 4 --num-layers-per-virtual-pipeline-stage 2 # 80 层 / 4 PP / 2 虚拟 stage = 10 层/虚拟 stageInterleaved PP 将 bubble 比例从 $(PP-1)/(m+PP-1)$ 降低到 $(PP-1)/(m \times v + PP-1)$,其中 $v$ 是虚拟 stage 数。代价是增加通信轮次。
9.5 MFU 计算
\[\text{MFU} = \frac{\text{实际训练 FLOPs/s}}{\text{硬件峰值 FLOPs/s}} = \frac{6BP / T_{\text{step}}}{N_{\text{gpu}} \times \text{Peak FLOPs/s}}\]其中:
- B = 每步总 token 数(global batch size × seq_len)
- P = 模型参数量
- $T_{\text{step}}$ = 每步训练时间
🛠️ 实践:Megatron
Megatron 的 MFU 监控:
- Megatron 在训练日志中会输出
throughput (TFLOP/s/GPU)和MFU- 也可以用 Weights & Biases 监控:
wandb.log({"mfu": mfu})LLaMA 3-70B 的 Megatron 配置参考:
# 模型参数 --num-layers 80 --hidden-size 8192 --ffn-hidden-size 28672 --num-attention-heads 64 --group-query-attention --num-query-groups 8 --seq-length 8192 --max-position-embeddings 8192 # 并行策略 --tensor-model-parallel-size 8 --pipeline-model-parallel-size 2 # DP = world_size / (8 × 2) # 内存优化 --use-distributed-optimizer --recompute-granularity selective --sequence-parallel --use-flash-attn # 训练超参 --micro-batch-size 1 --global-batch-size 1024 --bf16 # 通信优化 --overlap-grad-reduce --overlap-param-gather调优技巧:
- 先固定 TP=8,PP=1,看内存是否够用
- 如果 OOM,增加 PP 或启用 recompute
- 调 micro-batch-size 使 GPU 利用率最高
- 监控 MFU,目标 > 40%
- 如果 MFU 低,检查是否通信瓶颈(
nsysprofile)
9.6 Per-Chip 内存分析
假设使用方案 A(TP=8, PP=1, DP=16, 128 H100),让我们精确计算每张 GPU 的内存使用:
| 组件 | 公式 | 每卡大小 |
|---|---|---|
| bf16 权重 | 140 GB / TP(8) | 17.5 GB |
| bf16 梯度 | 140 GB / TP(8) | 17.5 GB |
| fp32 主权重 + Adam | 560 GB / (TP×DP) = 560/128 | 4.4 GB |
| 静态小计 | 39.4 GB | |
| 激活值 (selective recompute) | 估算 | ~20-30 GB |
| 总计 | ~60-70 GB |
H100 有 80 GB → 方案 A 可行,留有 ~15 GB 余量。
如果 OOM,可以:
- 降低
--micro-batch-size(减少激活内存) - 使用
--recompute-granularity full(block remat,FLOPs +33% 但大幅减少激活) - 切换到方案 B(PP=2,每卡层数减半)
9.7 Sequence Parallelism 与 Context Parallelism
Sequence Parallelism(序列并行)
Megatron 的 Sequence Parallelism 与 TP 配合使用:在非 TP 部分(LayerNorm、Dropout)沿序列维度分片,避免冗余计算。
TP=8
┌──────────────────────────┐
│ LayerNorm [B, T/8, D] │ ← Sequence Parallel (每卡 T/8)
│ AllGather → [B, T, D] │
│ Attention (TP sharded) │ ← Tensor Parallel
│ ReduceScatter → [B, T/8]│
│ LayerNorm [B, T/8, D] │ ← Sequence Parallel
│ AllGather → [B, T, D] │
│ FFN (TP sharded) │ ← Tensor Parallel
│ ReduceScatter → [B, T/8]│
└──────────────────────────┘
效果:减少 LayerNorm 和 Dropout 的激活内存 $\times 1/\text{TP}$。
Context Parallelism(上下文并行)
对于超长序列(32K+),序列维度本身需要分片。Megatron 的 Context Parallelism 将序列分到多张 GPU:
--context-parallel-size 2 # 序列分成 2 份
注意力层需要特殊处理(Ring Attention):每张 GPU 持有部分 Q,通过 ring 方式轮转 KV 来计算完整 attention。
| 并行方式 | 分片维度 | 通信类型 | 适用场景 |
|---|---|---|---|
| DP/FSDP | Batch | AllReduce/AG+RS | 始终使用 |
| TP | d_ff | AG + RS(激活) | 节点内(NVLink) |
| PP | Layer | P2P(激活) | 大模型(>30B) |
| SP | Sequence (非 TP 部分) | 与 TP 通信合并 | 总与 TP 一起 |
| CP | Sequence (attention) | Ring Attention | 超长序列 |
9.8 容错与 Checkpointing
在 16K GPU 规模上训练数周,硬件故障是必然的。
故障率估算
假设单卡年故障率 ~2%:
- 16K GPU:每天预期故障数 = $16000 \times 0.02 / 365 \approx 0.88$ → 几乎每天都有故障
- 128 GPU:每天 ~$0.007$ → 约 143 天一次
Checkpoint 策略
| 策略 | 频率 | 时间开销 | 丢失的训练 |
|---|---|---|---|
| 同步 checkpoint | 每 N steps | 数分钟(写入共享存储) | 最多 N steps |
| 异步 checkpoint | 每 N steps | ~0(后台写入) | 最多 N steps |
🛠️ 实践:Megatron Checkpointing
--save-interval 500 # 每 500 steps 保存 --save /path/to/checkpoints # 保存路径 --load /path/to/checkpoints # 恢复路径 --async-save # 异步保存(减少训练中断)Checkpoint 大小 = 参数 (fp32) + 优化器状态 ≈ $16 \times P$ 字节。 LLaMA 70B:$16 \times 70B \approx 1.12$ TB/checkpoint。
存储需求:如果保留最近 5 个 checkpoint = 5.6 TB。使用分布式文件系统(如 Lustre、GPFS)或对象存储(S3)。
9.9 训练超参数与 Batch Size 选择
Batch Size 与训练效率的 Trade-off
Batch size 的选择不仅影响通信效率,还影响训练收敛:
| Batch Size | 通信效率 | 收敛效率 | 典型用途 |
|---|---|---|---|
| 很小 (< 1M tokens) | 可能通信瓶颈 | 梯度噪声大,收敛慢 | 微调、小模型 |
| 中等 (1M-8M) | 良好 | 最佳 learning-per-token | 大模型预训练 |
| 很大 (> 16M) | 优秀 | 收益递减,可能不稳定 | 集群利用率优先 |
LLaMA 3-70B 使用 batch size warmup:
- 前 1000 steps:BS = 512K tokens
- 逐步增大到 BS = 4M tokens
- 保持 4M 直到训练结束
这样做的原因:小 batch 在训练早期提供更多梯度更新(per-token 更高效),大 batch 在后期提供更稳定的梯度。
学习率调度
LR
│ ┌─────────────────────────┐
│ / \
│ / warmup cosine decay \
│/ \
├──┬────────────────────────────┬──→ steps
0 2K 15T tokens
典型配置(LLaMA 3-70B):
- Peak LR: 1.5e-4
- Warmup steps: 2000
- Decay: cosine → 0.1 × peak LR
- Weight decay: 0.1
🛠️ 实践:Megatron 学习率配置
--lr 1.5e-4 --lr-warmup-iters 2000 --lr-decay-style cosine --lr-decay-iters 3750000 # 根据总 tokens / batch size 计算 --min-lr 1.5e-5 # 0.1 × peak lr --weight-decay 0.1 --adam-beta1 0.9 --adam-beta2 0.95 --clip-grad 1.0
9.10 分片决策流程图
开始:给定模型大小 P, 集群大小 N, batch size B
Step 1: 能否单卡放下?(P × 10 bytes < HBM?)
├─ 是 → 纯 DP (TP=1, PP=1), 验证 B/N > C/W
└─ 否 → Step 2
Step 2: FSDP 够吗?(P × 10 / N < HBM?)
├─ 是, B/N > C/W → FSDP (TP=1, PP=1)
├─ 是, 但 B/N < C/W → 需要 TP → Step 3
└─ 否 → 需要 PP → Step 3
Step 3: 确定 TP = min(8, GPU/节点)
确定 PP (看内存)
DP = N / (TP × PP)
验证 B/DP > C/W_IB
具体模型的决策示例
| 模型 | P | N (GPU) | Step 1 | Step 2 | Step 3 | 最终配置 |
|---|---|---|---|---|---|---|
| LLaMA 8B | 8B | 32 | 80B > 80GB ✗ | 2.5GB/卡 ✓ | — | FSDP, TP=1, PP=1 |
| LLaMA 70B | 70B | 128 | ✗ | 5.5GB/卡 ✓ | TP=8 更优 | TP=8, PP=1, DP=16 |
| LLaMA 405B | 405B | 16K | ✗ | 0.25GB/卡 ✓ | TP=8, PP 必须 | TP=8, PP=16, DP=125 |
9.11 Megatron 调优实战指南
🛠️ 实践:从零配置 Megatron 训练
Phase 1:确定基本配置
TP=8 # H100 节点内 PP=1 # 先尝试 PP=1 # DP = world_size / (TP * PP) 自动计算 --use-distributed-optimizer # 必开 --sequence-parallel # 与 TP 配合 --use-flash-attn # Flash Attention --micro-batch-size 1 # 先用小值测试Phase 2:调优 micro-batch size
micro-batch-size: 1 → 2 → 4 → ... 直到 GPU 内存使用约 90-95%Phase 3:处理 OOM
# 方案 A: 增加重计算 --recompute-granularity selective # 方案 B: 增加 PP --pipeline-model-parallel-size 2Phase 4:验证 MFU
MFU = 6 × tokens/step × params / (step_time × GPU数 × peak_FLOPs) 目标: > 40% (H100 bf16)常见问题排查:
症状 可能原因 解决方案 MFU < 30% 通信瓶颈 检查 TP 是否跨节点;增大 micro-batch MFU 波动大 Pipeline bubble 增加 micro-batches 或用 interleaved PP OOM 激活内存 降低 micro-batch 或增加 recompute 吞吐骤降 节点间通信 nsysprofile 检查通信比例
9.12 成本估算
| 配置 | GPU 数 | 时间 | 成本($2/GPU·h) |
|---|---|---|---|
| 16K H100, MFU=40% | 16,000 | ~12 天 | ~$9.2M |
| 8K H100, MFU=45% | 8,000 | ~21 天 | ~$8.1M |
| 2K H100, MFU=50% | 2,000 | ~73 天 | ~$7.0M |
| 128 H100, MFU=50% | 128 | ~1140 天 | ~$7.0M |
权衡:
- 更多 GPU → 更快但 MFU 可能更低(通信开销增加)→ 成本可能反而更高
- 少 GPU + 高 MFU 可以降低总成本,但训练时间更长(增加故障恢复风险)
- 实际中通常选择 能在 2-4 周内完成 的最小集群规模
习题
Q1:Scaling to 更多节点
如果要用 512 张 H100(64 节点)训练 LLaMA 3-70B,batch size = 4M tokens:
(a) 推荐的 TP/PP/DP 配比是什么? (b) 是否 compute-bound? (c) 训练时间是多少?
点击查看答案
(a) TP=8(节点内),PP=1 或 2,DP=64 或 32。
推荐 TP=8, PP=1, DP=64。Per-device batch = 4M/64 = 62500 tokens。
(b) DP 的通信瓶颈条件:per-device batch > $C/W_{\text{IB}} = 990T / 400G \approx 2475$。
62500 » 2475 → compute-bound ✓
(c) 训练时间 = $6.3 \times 10^{24} / (512 \times 9.9 \times 10^{14} \times 0.4) \approx 3.1 \times 10^7$ s ≈ 360 天。
512 卡太少了——对于 15T token 的训练,至少需要数千卡才能在合理时间内完成。
Q2:LLaMA 3-8B 训练配置
LLaMA 3-8B 的配置:D=4096, F=14336, L=32, H=32, Kv=8。
(a) 参数量是多少? (b) 能否用纯 FSDP 在 32 张 H100 上训练? (c) 推荐的配置是什么?
点击查看答案
(a)
- FFN: $3 \times 4096 \times 14336 \times 32 = 5.64B$
- Attention: $32 \times (2 \times 4096 \times 32 \times 128 + 2 \times 4096 \times 8 \times 128) = 1.34B$
- Vocab: $2 \times 128256 \times 4096 = 1.05B$
- 总计 ≈ 8.0B ✓
(b) 静态内存 = $(2 + 2 + 8) \times 8B = 96$ GB。分到 32 卡 = 3 GB/卡 → 可以。
通信:per-device batch(假设 BS=4M)= 4M/32 = 125000 » 2475 → compute-bound ✓。
(c) 8B 模型足够小,纯 FSDP(TP=1, PP=1, DP=32) 即可!
不需要 TP 和 PP。这就是小模型训练的好处——简单、高效、MFU 容易做到 50%+。
# Megatron 配置
--tensor-model-parallel-size 1
--pipeline-model-parallel-size 1
--use-distributed-optimizer
--micro-batch-size 4
--global-batch-size 1024
Q3:LLaMA 3-405B 训练配置
LLaMA 3-405B:D=16384, F=53248, L=126, H=128, Kv=8, V=128256。
(a) 总参数量? (b) 在 16K H100 上训练 15T tokens 需要多久(MFU=35%)? (c) 推荐的 TP/PP/DP 配比? (d) 每卡内存估算?
点击查看答案
(a)
- FFN: $3 \times 16384 \times 53248 \times 126 = 330B$
- Attention: $126 \times (2 \times 16384 \times 128 \times 128 + 2 \times 16384 \times 8 \times 128) = 70.5B$
- Vocab: $2 \times 128256 \times 16384 = 4.2B$
- 总计 ≈ 405B ✓
(b) FLOPs = $6 \times 15T \times 405B = 3.65 \times 10^{25}$
\[T = \frac{3.65 \times 10^{25}}{16000 \times 9.9 \times 10^{14} \times 0.35} = 6.6 \times 10^6 \text{ s} \approx \textbf{76 天}\](c) 静态内存 = $(2+2+8) \times 405B = 4.86$ TB。
- TP=8(节点内,NVLink),验证:$F=53248 > 8 \times 1100$ ✓
- PP=8-16(405B / 8(TP) = 50.6 GB 权重/卡,不够放优化器;需要 PP 进一步分层)
- 假设 PP=16:每卡层数 = 126/16 ≈ 8 层
- DP = 16000 / (8×16) = 125
推荐:TP=8, PP=16, DP=125。
Meta 实际使用了 TP=8, PP=16, DP=125(16000 H100),MFU 约 38-43%。
(d) 每卡:
- 权重:$2 \times 405B / (8 \times 16) = 6.3$ GB
- 优化器(distributed):$8 \times 405B / (8 \times 16 \times 125) = 0.2$ GB
- 激活值:取决于 micro-batch size 和 recompute 策略
- 总静态 ≈ ~7 GB(非常小!PP 极大地减少了每卡内存)
Q4:跨多节点的 DCN/IB 通信分析
在 128 卡(16 节点 × 8 GPU/节点)训练 LLaMA 70B,TP=8 (节点内), DP=16 (跨节点),batch=4M tokens:
(a) DP 的 AllReduce 通信量是多少? (b) 在 IB 400 GB/s 带宽下,通信时间? (c) 能否被计算完全掩盖?
点击查看答案
(a) DP 的梯度通信量 = 权重大小 / TP = 140 GB / 8 = 17.5 GB(bf16)。
AllReduce 实际传输 = $2 \times 17.5 = 35$ GB(AG + RS)。
(b) 在 IB 400 GB/s 下:$35 \text{ GB} / 400 \text{ GB/s} = 87.5$ ms。
(c) 单步反向传播时间 ≈ $\frac{4 \times B_{\text{local}} \times P_{\text{local}}}{\text{FLOPs/s}}$。
$B_{\text{local}} = 4M / 16 = 250K$ tokens,$P_{\text{local}} = 70B / 8 = 8.75B$(TP 后每卡参数)。
\[T_{\text{backward}} = \frac{4 \times 250000 \times 8.75 \times 10^9}{9.9 \times 10^{14} \times 0.5} \approx 17.7 \text{ s}\]87.5 ms « 17.7 s → 完全可以被掩盖 ✓。
DP 的 AllReduce 在反向传播过程中逐层发送(--overlap-grad-reduce),充分重叠。
关键要点(总结)
- 训练 FLOPs = $6NP$,每 token FLOPs ≈ $6P$
- 训练时间 = $6NP / (\text{GPU数} \times \text{Peak} \times \text{MFU})$
- FFN 占参数的 ~80%,是分片的主要对象
- 纯 DP 无法训练 >9B 模型(参数+优化器 > HBM)
- FSDP 瓶颈:per-device batch > $C/W$(H100 NVLink: 1100, IB: 2475)
- TP+FSDP 把临界 batch 降到 ~100/chip
- GPU 配置决策链:TP=8 (节点内) → PP (看内存) → DP (余量)
- MFU 目标 > 40%,监控日志中的 throughput
- Gradient checkpoint 主导激活内存
- Batch size warmup + cosine LR decay 是标准训练策略
- 16K GPU 规模下几乎每天都有硬件故障 → checkpoint 间隔 < 500 steps
| 模型 | 最少 GPU | 推荐 GPU | TP | PP | 训练时间 (15T tokens) |
|---|---|---|---|---|---|
| 8B | 2-4 | 32-64 | 1 | 1 | 数天-数周 |
| 70B | ~270 | 2K-16K | 8 | 1-2 | 2-12 周 |
| 405B | ~2000 | 16K+ | 8 | 8-16 | 2-3 月 |
进一步阅读
- 原书 Chapter 6: Training LLaMA 3 on TPUs
- LLaMA 3 论文 (Meta, 2024) — 训练细节章节
- Megatron-LM GitHub 示例脚本
- DeepSeek-V3 技术报告 — MoE 训练的 pipeline 和并行策略
- ZeRO 论文 (Rajbhandari et al., 2020) — FSDP/ZeRO 的理论基础